Quiver:让你的多卡GNN训练更快
前言
Quiver是一个开源的GNN框架,其不仅能提升单卡训练的性能,同时能极大的提升训练的多卡扩展性,甚至在有NVLink的机器上实现超线性加速比,而这一切需要的代价仅仅是数十行源码的修改即可(尤其当你是一个PyG用户)!
import quiver
...
## Step 1: Replace PyG graph sampler
# train_loader = NeighborSampler(data.edge_index, ...) # Comment out PyG sampler
train_loader = torch.utils.data.DataLoader(train_idx) # Quiver: PyTorch Dataloader
quiver_sampler = quiver.pyg.GraphSageSampler(quiver.CSRTopo(data.edge_index), sizes=[25, 10]) # Quiver: Graph sampler
...
## Step 2: Replace PyG feature collectors
# feature = data.x.to(device) # Comment out PyG feature collector
quiver_feature = quiver.Feature(rank=0, device_list=[0]).from_cpu_tensor(data.x) # Quiver: Feature collector
...
## Step 3: Train PyG models with Quiver
# for batch_size, n_id, adjs in train_loader: # Comment out PyG training loop
for seeds in train_loader:
n_id, batch_size, adjs = quiver_sampler.sample(seeds) # Use Quiver graph sampler
batch_feature = quiver_feature[n_id] # Use Quiver feature collector
https://pic3.zhimg.com/80/v2-7bde56cd249e756d8b34281027207c82_1440w.jpg
Quiver的github链接在下面,欢迎GNNSys研究同行star、fork、pr三连!
https://github.com/quiver-team/torch-quiver
在这篇文章中我们介绍Quiver的部分设计方案以及背后实现的动机,完整的方案我们会在后续的论文中全部放出。
一、整体介绍
所有研究图机器学习系统的团队都知道基于采样的图模型训练性能瓶颈在图采样和特征聚合上,但两个瓶颈背后的本质到底是什么?Quiver核心观点是:
-
图采样是一个 latency critical problem,高性能的采样核心在于通过大量并行掩盖访问延迟。 -
特征聚合是一个 bandwidth critical problem,高性能的特征聚合在于优化聚合带宽。
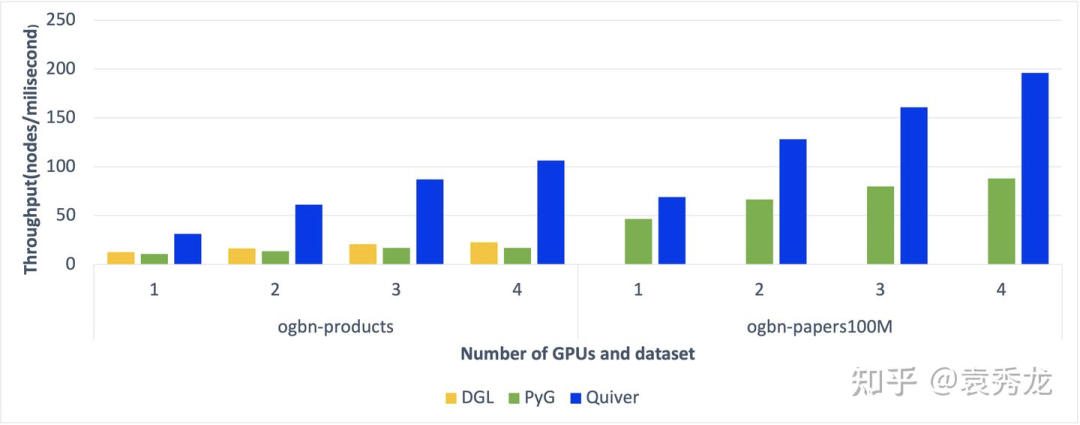
一般情况下,我们选择使用CPU进行图采样和特征聚合,这种方案不仅会带来单卡训练的性能问题,同时由于采样与特征聚合均为CPU密集型操作,多卡训练时会由于CPU计算资源的瓶颈导致训练扩展性不理想。我们以ogbn-product数据集为例benchmark PyG使用CPU采样和特征聚合时的多卡训练扩展性结果如下。具体的测试脚本见Quiver项目链接。
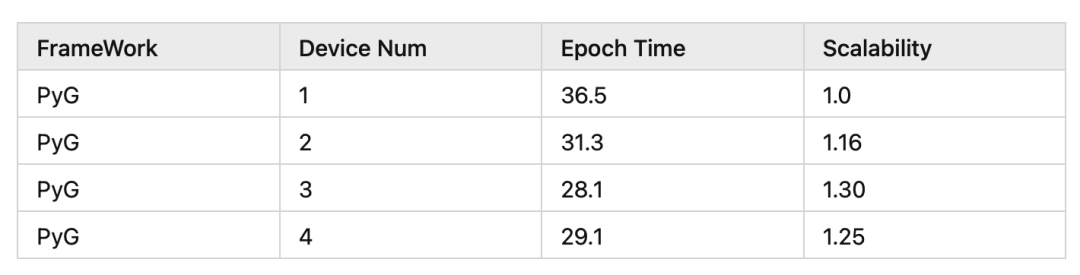
接下来我们一一介绍Quiver在图采样和特征聚合上面的加速工作。
二、Quiver的性能优化
2.1 采样方案
为了解决CPU采样带来的问题,DGL和PyG同时也支持部分采样算法的GPU实现。GPU采样从性能上讲肯定是要远远高于CPU采样的,但是却面临一个严重的问题是:图的拓扑大小受限于显存空间。比如我们上面评测的paper100M,纯拓扑数据就有大约13G,而MAG240M数据集纯拓扑有大约25G,企业里面的业务图很多比MAG240M甚至还要大一些,这对于市面上绝大部分GPU来说都很难完全放到显存中去,更不用提本身我们需要一部分显存来做模型训练。
Quiver中向用户提供UVA-Based(Unified Virtual Addressing Based)图采样算子,既支持用户将数据放在GPU中进行采样,也支持在图拓扑数据较大时选择将图存储在CPU内存中的同时使用GPU进行采样。这样我们不仅获得了远高于CPU采样的性能收益,同时能够处理的图的大小从GPU显存大小限制扩展到了CPU内存大小(一般远远大于GPU显存)。
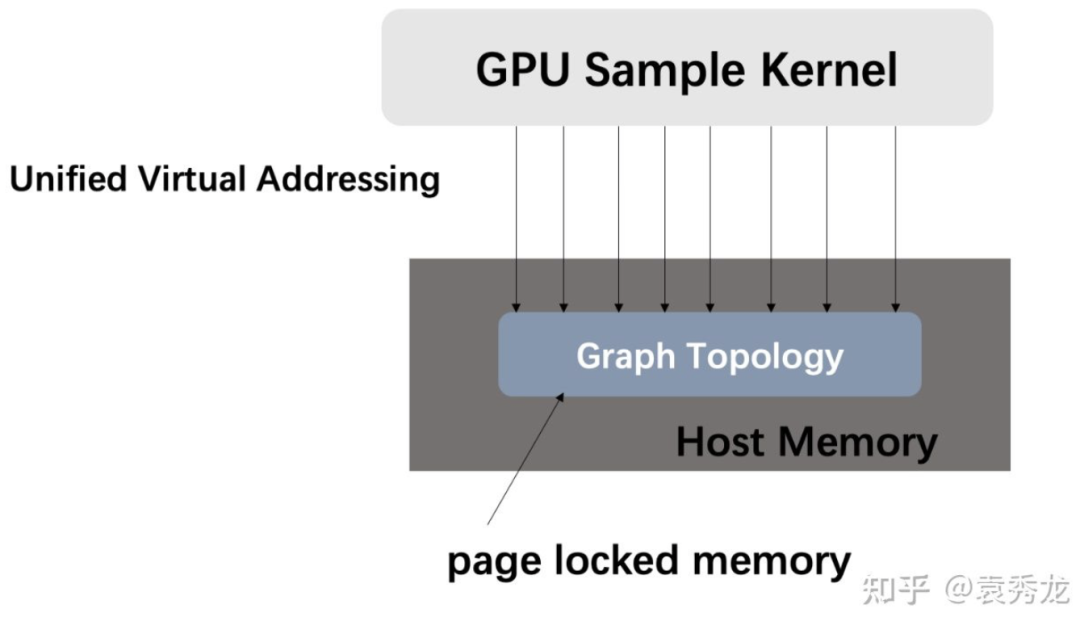
我们在ogbn-products和reddit上的两个数据集上进行采样性能测试显示,UVA-Based的采样性能远远高于CPU采样性能(CPU采样使用PyG的采样实现为基线),我们衡量采样性能的指标为单位时间内的采样边数(Sampled Edges Per Second, SEPS)。我们可以看到在同样不需要存储图在GPU显存中的情况下,Quiver的采样在真实数据集上提供大约20倍的性能加速。(具体benchmark代码见项目链接)
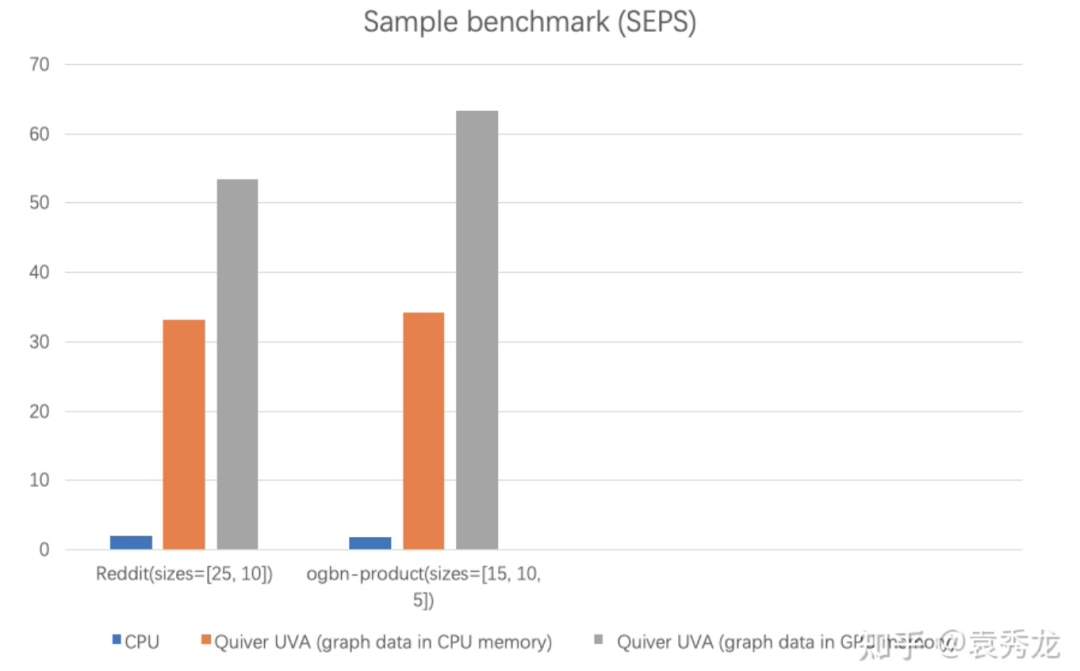
当用户的GPU足够放下整个图的拓扑数据时,可通过设置采样参数mode=GPU选择将图放置在GPU上以获得更高的性能。从我们的benchmark中发现,设置mode=GPU时, 相比较UVA模式能够带来30%-40%的性能提升。
使用UVA采样带来的好处不仅仅是采样的加速,更是缓解了对CPU计算资源的需求使得多卡扩展性得到了极大的改善,为了避免歧义,我们下文中所有的UVA Sample都指的是数据存储在Host Memory中,接下来我们重点介绍对于特征聚合吞吐的优化。
2.2 图特征聚合(Feature Collection)
由于GNN训练时一个batch的特征数据往往有数百MB甚至几个GB,这些特征数据任何一次在CPU内存中的搬运,以及CPU到GPU之间的数据搬运都有着较大的耗时。图特征聚合优化的核心在于优化端到端的吞吐,即从特征获取到传输到GPU过程的吞吐。现有的方案一般分为两种:
-
CPU进行特征聚合,并将聚合特征传输到GPU进行训练 -
当特征数据较少时,将全部特征放到GPU显存中
基于CPU的方案面临着吞吐性能的问题,同时CPU的Feature Collection本身为CPU密集型操作,同样面临着多卡训练时由于对CPU资源的竞争导致特征聚合的多卡扩展性较差。而基于GPU的方案2仍然面临着处理的图特征受限于GPU显存大小。而实际情况中,特征的大小远远大于图的拓扑结构大小。比如MAG240M数据集拓扑结构大约有25G,而实际特征大小有大约300G,这就很难放倒GPU中去。
Quiver提供了高吞吐的quiver.Feature用于进行特征聚合。quiver.Feature的实现主要基于如下两个观察:
-
真实图往往具有幂律分布特性,少部分节点占据了整图大部分的连接数,而大部分基于图拓扑进行采样的算法,最终一个Epoch中每个节点被采样到的概率与该节点的连接数成正相关。 -
一个AI Server中的各种访问传输带宽大小关系如下 GPU Global Memory > GPU P2P With NVLink > Pinned Memory > Pageable Memory。 但现有的系统几乎很少能够很好的利用这个hierarchy访问层级来加速整个数据吞吐。
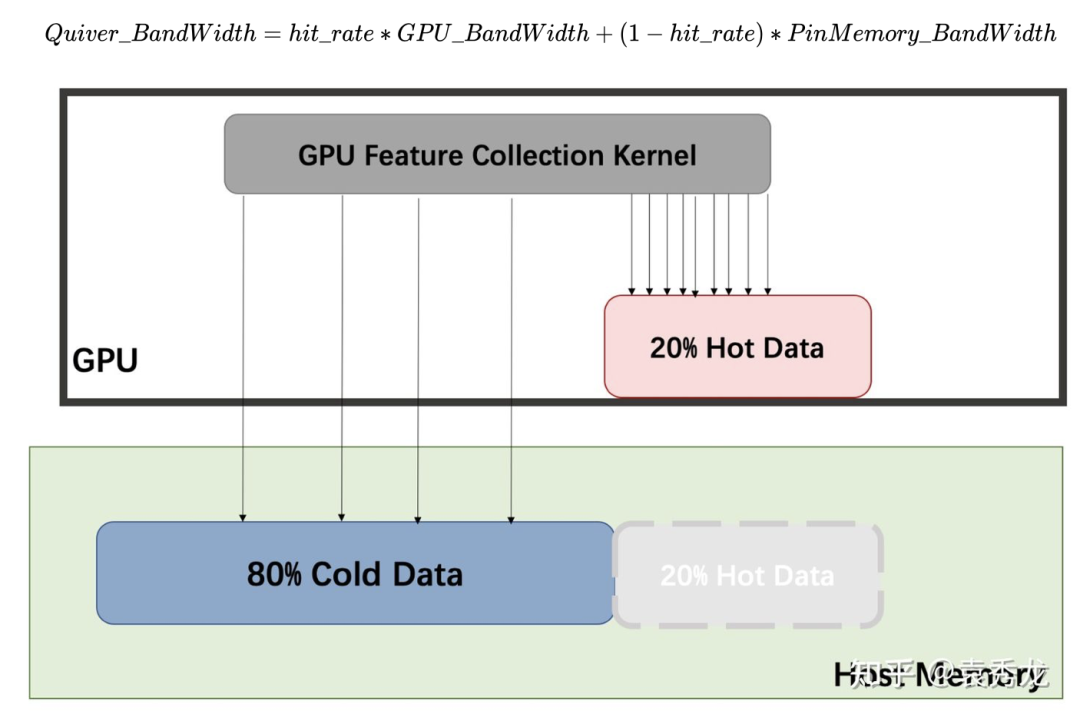
考虑到上述的访问带宽层级关系以及图节点的访问不均匀性质,Quiver中的quiver.Feature根据用户配置的参数将特征进行自动划分存储在GPU显存以及CPU Pinned Memory中, 并将热点数据存储在GPU,冷数据存储在CPU中。我们实现了一个高效的GPU Kernel来统一做跨设备的数据存储访问并确保一个warp中的所有thread能够聚合存储访问,这样对于跨PCIe的memory request和对GPU Global memeory的显存访问都更加友好,同时由于图节点的访问不均匀性,大部分thread都命中GPU部分数据,进而能最大化的利用显存,最终的访问带宽计算公式为:
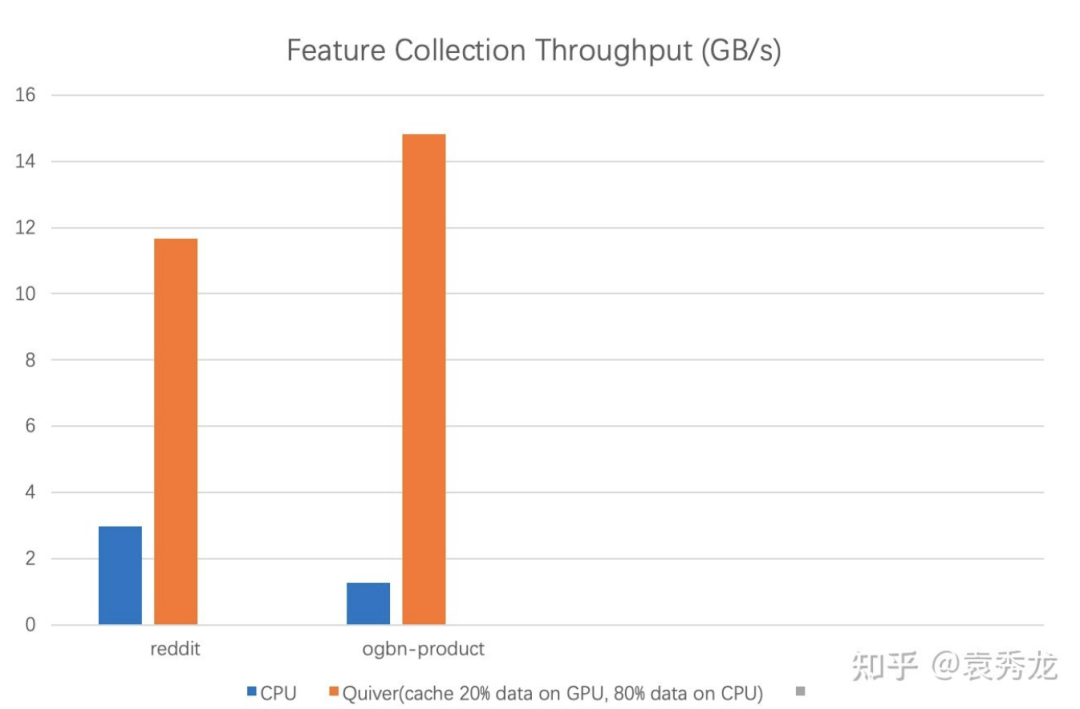
我们对这种方案进行benchmark特征聚合的吞吐,我们发现相比较CPU, Quiver完成特征聚合具有4-10倍的加速。同样,使用GPU做特征聚合带来的不仅是性能的提升,还有对CPU资源的需求缓解以避免多卡扩展时对CPU资源的竞争。
但是上文提及的NVLink的参与在哪里呢?别急,我们下文就有介绍。
三、多卡训练 —— Without NVLink
基于上述的quiver.Feature和quiver.pyg.GraphSageSampler 我们便可以进行GNN模型的训练,如果你是一位PyG用户,那么你只需要对你的源码进行数十行修改便可以使用Quiver来加速你的训练。我们对quiver.Feature和quiver.pyg.GraphSageSampler 实现了内置的IPC机制,你可以方便的把他们作为参数传给子进程进行使用。多卡中我们提出了device_replicate方案,即热数据在各个GPU上进行复制存储,冷数据存储在Host Memory中。
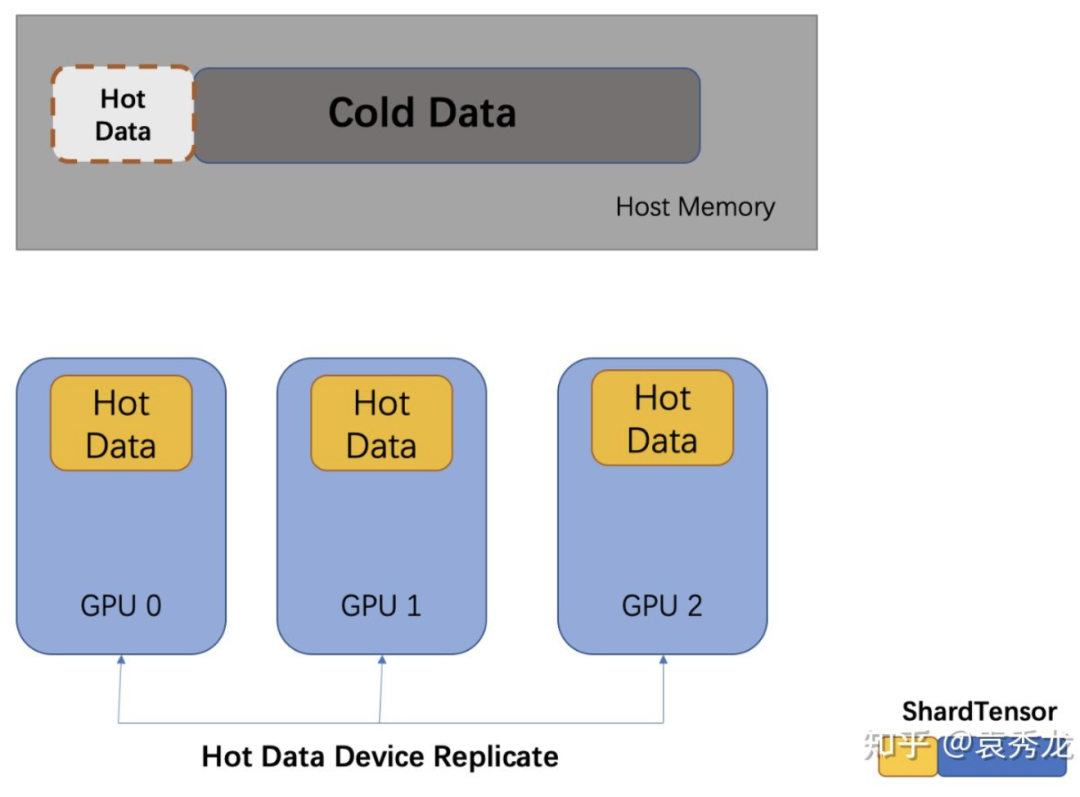
我们以ogbn-product为例子进行benchmark实验验证, 我们发现在使用GPU仅仅缓存20%的数据情况下,Quiver和使用CPU来进行特征聚合和采样的PyG端到端训练性能(实验中每个训练进程中的采样并行度为5)对比在4卡上有大约9倍的性能提升,即使是PyG将所有的特征数据放到GPU上,Quiver与之相比仍然在4卡上有3倍的加速,更为重要的是,随着GPU数目的增多,Quiver和PyG本身的性能差异在逐渐拉大。
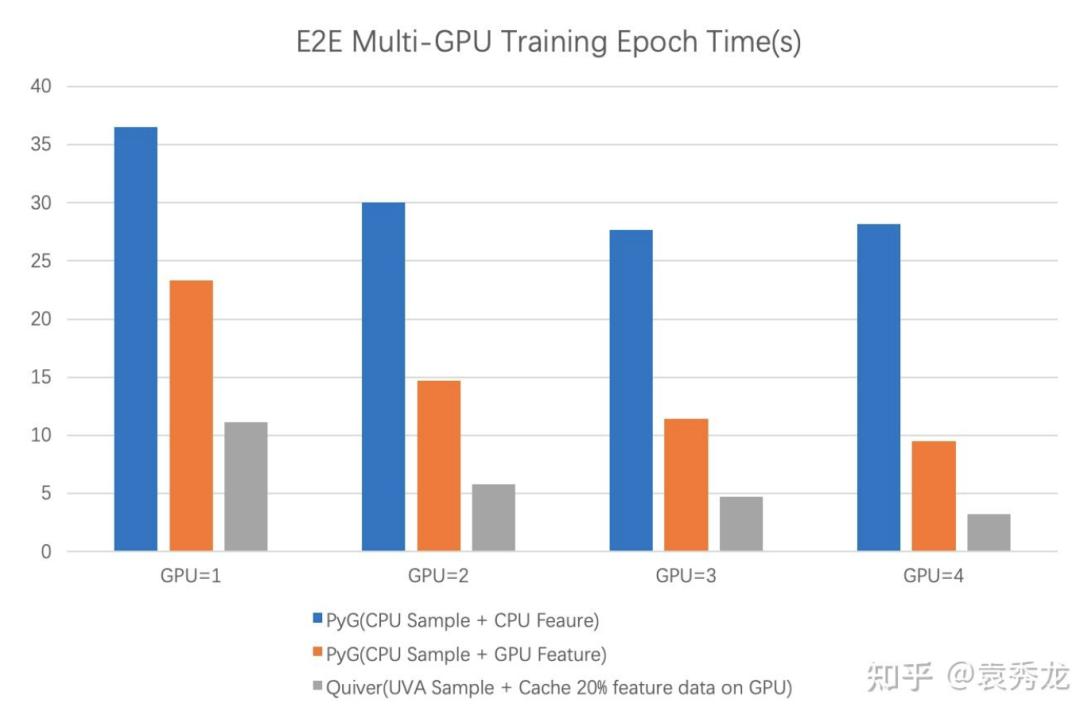
我们在4卡上跑paper100M的实验发现扩展效率约为85%(扩展比为3.4),那么这损失的15%来源于哪里呢?我们认为核心还是来自于对CPU内存总线的竞争。我们就想怎么能够把CPU总线上的负载分担一下,这样多卡扩展性会更好,于是我们瞄向了NVLink。
四、多卡训练 —— With NVLink
我们知道,当把数据存储在NVLink上时,如果走P2P访问,其数据传输本身不走CPU总线这一条路,这会明显的减少CPU总线的负载,同时GPU P2P With NVLink的吞吐远远高于PinMemory的聚合吞吐,这会进一步提升我们的特征聚合吞吐。
当我们有NVLink时,特征聚合的吞吐层次关系是:GPU本地显存 > GPU P2P With NVLink > PinMemory, 我们希望热数据能更多的命中本地显存和其他GPU显存。于是我们提出了p2p_clique_replicate策略,即当有NVLink时,一个NVLink团内(即该组GPU全部互相可以P2P访问)所有GPU共享缓存,p2p_clique之间仍然是热数据复制的策略。(要求p2p_clique之间对称)。
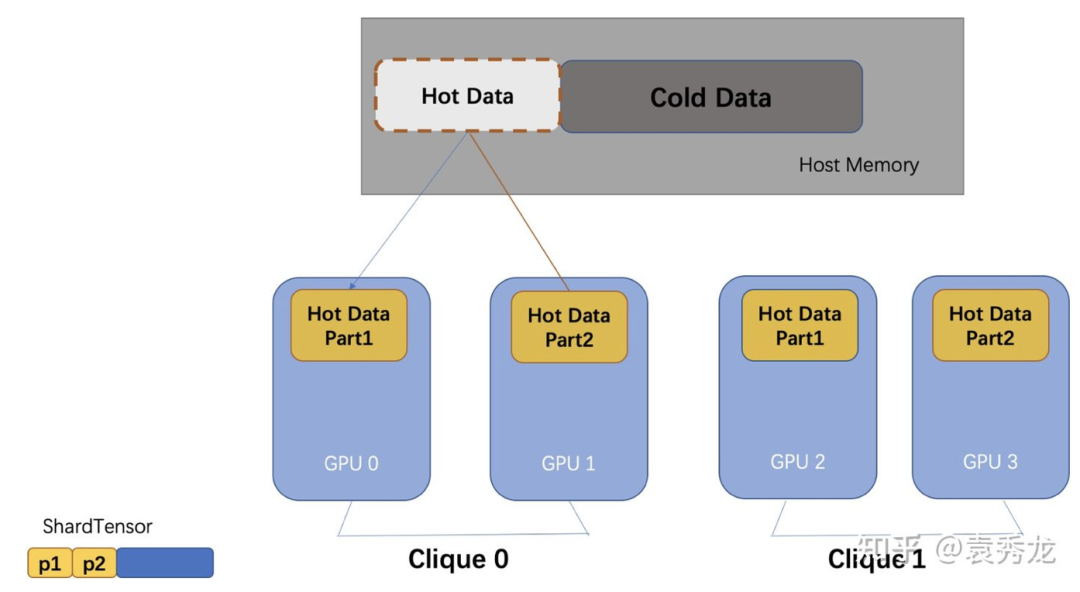
具体到一个Clique内部的数据访问如下所示,我们将热数据存储在Clique内的机器上,仍然一个Kernel完成不同GPU、Host Memory的访问。同时为了确保各个GPU内的数据访问负载均衡,我们做了一系列的shuffle预处理。
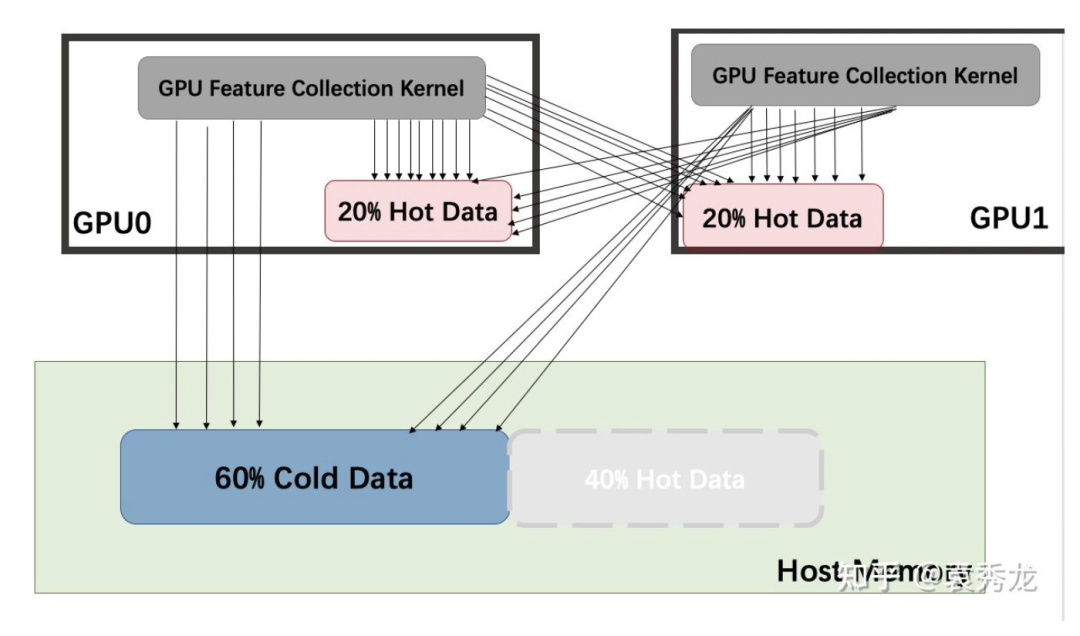
这样的策略给我们带来了如下的好处:
-
更大的缓存空间,原先我们只能一个GPU上缓存20%的数据,现在我们可以Clique内共享缓存,一共缓存40%的数据,同时由于NVLink的访问更快,使得整体数据访问呈超线性加速。 -
极大的减少CPU总线负载。原先device_replicate策略中随着多卡的加入,CPU总线的负载呈线性增长,但是在p2p_clique_replicate的策略下,随着Clique的增大,CPU总线负载反而下降,由于图数据的访问不均匀性,使得大部分特征聚合都被NVLink给Bypass了。
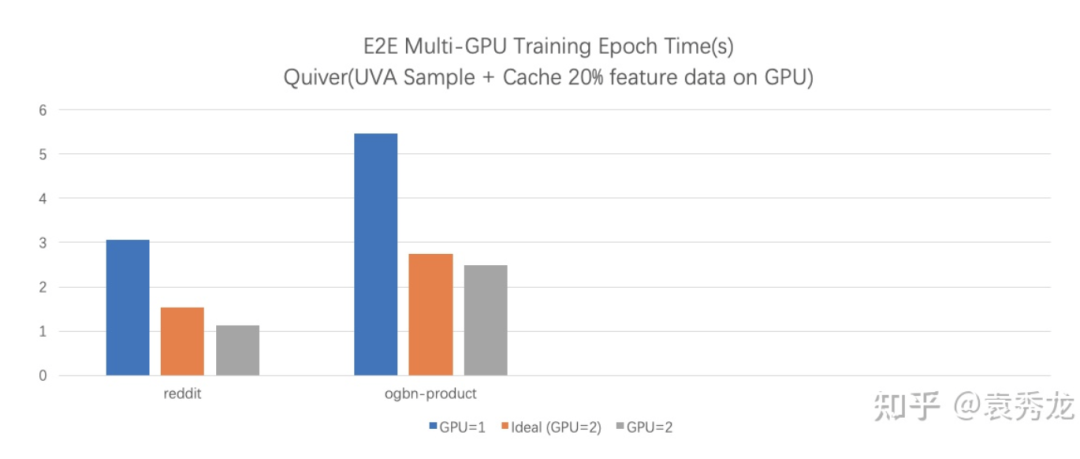
这两点带来的最终端到端的结果是,我们在一个具有NVLink的两卡机器上训练ogbn-product数据集达到了超线性加速比。quiver提供了非常简单易用的API设计,方便用户只需要修改cache_policy参数即可切换使用两种不同的多卡缓存策略。
五、总结
路漫漫其修远兮,吾将上下而求索。目前我们只是开源了Quiver的单机版本的部分功能,更多的功能和训练策略优化会在后续的论文中放出,同时在下一次realease中我们将开源Quiver的分布式版本,努力让超大图上的GNN训练变得更快,更轻松。Quiver由University of Edinburgh, Imperial College London, Tsinghua University and University of Waterloo的研究人员共同参与研究,并受到Alibaba and Lambda Labs两家企业的支持。感兴趣的同学欢迎关注我们的项目!


