图神经网络库PyTorch geometric
如何快速理解gcn的在文章《一文读懂图卷积GCN》中已经有比较详细的说明,建议没有任何基础的小伙伴先读下理论入门。
我们不能做思想上的巨人,行动上的矮子,因此来学习下如何利用现有的库快速跑通一个例子,英文文档见参考文献。
安装PyTorch geometric
首先确保安装了PyTorch 1.2.0及以上版本
$ python -c "import torch; print(torch.__version__)"
>>> 1.2.0安装依赖包
$ pip install --verbose --no-cache-dir torch-scatter
$ pip install --verbose --no-cache-dir torch-sparse
$ pip install --verbose --no-cache-dir torch-cluster
$ pip install --verbose --no-cache-dir torch-spline-conv (optional)
$ pip install torch-geometric注意:
def spawn(self, cmd):
spawn(cmd, dry_run=self.dry_run)改为
def spawn(self, cmd):
spawn(cmd, dry_run=self.dry_run)快速上手
对于某一个具体的简单无权无向图:
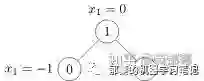
import torch
from torch_geometric.data import Data
#边,shape = [2,num_edge]
edge_index = torch.tensor([[0, 1, 1, 2],
[1, 0, 2, 1]], dtype=torch.long)
#点,shape = [num_nodes, num_node_features]
x = torch.tensor([[-1], [0], [1]], dtype=torch.float)
data = Data(x=x, edge_index=edge_index)
>>> Data(edge_index=[2, 4], x=[3, 1])数据集
PyTorch Geometric已经包含有很多常见的基准数据集,包括:
Cora:一个根据科学论文之间相互引用关系而构建的Graph数据集合,论文分为7类:Genetic_Algorithms,Neural_Networks,Probabilistic_Methods,Reinforcement_Learning,Rule_Learning,Theory,共2708篇;
Citeseer:一个论文之间引用信息数据集,论文分为6类:Agents、AI、DB、IR、ML和HCI,共包含3312篇论文;
Pubmed:生物医学方面的论文搜寻以及摘要数据集。
以及网址中的数据集等等。
初始化这样的一个数据集也很简单,会自动下载对应的数据集然后处理成需要的格式,例如ENZYMES dataset (覆盖6大类的600个图,可用于graph-level的分类任务):
from torch_geometric.datasets import TUDataset
dataset = TUDataset(root='/tmp/ENZYMES', name='ENZYMES')
>>> ENZYMES(600)
len(dataset)
>>> 600
dataset.num_classes
>>> 6
dataset.num_node_features
>>> 3对于其中的第一个图,可以这样取得:
data = dataset[0]
>>> Data(edge_index=[2, 168], x=[37, 3], y=[1])
#可以看出这个图包含边168/2=84条,节点37个,每个节点包含三个特征
data.is_undirected()
>>> True再看一个node-level的数据集
from torch_geometric.datasets import Planetoid
dataset = Planetoid(root='/tmp/Cora', name='Cora')
>>> Cora()
#可以看到这个数据集只有一个图
len(dataset)
>>> 1
dataset.num_classes
>>> 7
dataset.num_node_features
>>> 1433
#train_mask
data = dataset[0]
>>> Data(edge_index=[2, 10556], test_mask=[2708],
train_mask=[2708], val_mask=[2708], x=[2708, 1433], y=[2708])
#用来训练的数据量
data.train_mask.sum().item()
>>> 140
#用来验证的数据量
data.val_mask.sum().item()
>>> 500
#用来测试的数据量
data.test_mask.sum().item()
>>> 1000完整示例
下面再来看一个完整的例子:
import torch
import torch
import torch.nn.functional as F
from torch_geometric.nn import GCNConv
#数据集加载
from torch_geometric.datasets import Planetoid
dataset = Planetoid(root='/tmp/Cora', name='Cora')
#网络定义
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = GCNConv(dataset.num_node_features, 16)
self.conv2 = GCNConv(16, dataset.num_classes)
def forward(self, data):
x, edge_index = data.x, data.edge_index
x = self.conv1(x, edge_index)
x = F.relu(x)
x = F.dropout(x, training=self.training)
x = self.conv2(x, edge_index)
return F.log_softmax(x, dim=1)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = Net().to(device)
data = dataset[0].to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
#网络训练
model.train()
for epoch in range(200):
optimizer.zero_grad()
out = model(data)
loss = F.nll_loss(out[data.train_mask], data.y[data.train_mask])
loss.backward()
optimizer.step()
#测试
model.eval()
_, pred = model(data).max(dim=1)
correct = float(pred[data.test_mask].eq(data.y[data.test_mask]).sum().item())
acc = correct / data.test_mask.sum().item()
print('Accuracy: {:.4f}'.format(acc))图卷积层的实现
理解图卷积层的实现,先要理解底层的信息传输的操作是怎么做的,上一文中说到对于节点i在第l层的特征向量,它的特征向量 

其中, 

那么回到上一篇文章最后得到的式子,

其中,





可以看出是信息传递层的一个特例, 
具体步骤可以分解为:
增加自连接到邻接矩阵,即邻接矩阵的对角线元素为1,得到
;
对节点的特征矩阵进行线性变换,将特征变换到维度D;
使用函数
对节点特征进行规范化, 也就是乘以参数矩阵
再乘以归一化的拉普拉斯矩阵;
对邻居节点特征进行聚合操作,这里是求和;
返回新的节点embedding;
 ;
; 再乘以归一化的拉普拉斯矩阵;
再乘以归一化的拉普拉斯矩阵;GCNConv层具体的实现代码为:
import torch
from torch_geometric.nn import MessagePassing
from torch_geometric.utils import add_self_loops, degree
class GCNConv(MessagePassing):
def __init__(self, in_channels, out_channels):
super(GCNConv, self).__init__(aggr='add') # "Add" aggregation.
self.lin = torch.nn.Linear(in_channels, out_channels)
def forward(self, x, edge_index):
# x has shape [N, in_channels]
# edge_index has shape [2, E]
# Step 1: 增加自连接到邻接矩阵
edge_index, _ = add_self_loops(edge_index, num_nodes=x.size(0))
# Step 2: 对节点的特征矩阵进行线性变换
x = self.lin(x)
# Step 3-5: Start propagating messages.
return self.propagate(edge_index, size=(x.size(0), x.size(0)), x=x)
def message(self, x_j, edge_index, size):
# x_j has shape [E, out_channels]
# Step 3: Normalize node features.
row, col = edge_index
deg = degree(row, size[0], dtype=x_j.dtype)
deg_inv_sqrt = deg.pow(-0.5)
norm = deg_inv_sqrt[row] * deg_inv_sqrt[col]
return norm.view(-1, 1) * x_j
def update(self, aggr_out):
# aggr_out has shape [N, out_channels]
# Step 5: Return new node embeddings.
return aggr_out
更多数据挖掘,nlp,推荐等领域前沿知识,欢迎关注公众号郁蓁的机器学习笔记
觉得有用就点个赞叭👇





