ICCV三个Strong Accept,UCSB等机构提出首个大规模视频语言数据集
机器之心报道
参与:路、一鸣
继获得 CVPR 2019 审稿得分排名第一(三个 Strong Accept)并获得最佳学生论文奖之后,加州大学圣芭芭拉分校王鑫等人所著论文再次获得三个 Strong Accept,被另一大计算机视觉顶会 ICCV 2019 接收。
两年一度的计算机视觉顶会 ICCV 2019 将于 2019 年 10 月 27-11 月 2 日在韩国首尔举行。今日该会议发放接收论文通知,据机器之心统计,ICCV 2019 共收到 4303 篇论文,接收 1077 篇,接收率为 25%。相比于上一届会议,ICCV 2019 的论文提交和接收数量都有大幅提升(ICCV 2017 共收到 2143 篇论文投稿,接收 621 篇,接收率为 29%)。
来自加州大学圣塔芭芭拉分校王威廉组的王鑫、吴佳炜与字节跳动人工智能实验室李磊、陈俊坤等人合作的 VATEX 论文被 ICCV 2019 接收,并获得三个 Strong Accept。此前,王鑫等人的视觉语言导航研究《Reinforced Cross-Modal Matching and Self-Supervised Imitation Learning for Vision-Language Navigation》在 CVPR 2019 评审过程中也获得三个 Strong Accept,最终获得了 CVPR 2019 最佳学生论文奖。
我们来看这篇获得三个 Strong Accept 的论文讲了什么。
这篇论文讲什么
论文:VATEX: A Large-Scale, High-Quality Multilingual Dataset for Video-and-Language Research

论文链接:https://arxiv.org/pdf/1904.03493.pdf
这篇论文介绍了一个新型大规模多语视频描述数据集 VATEX,该数据集包含超过 41250 个视频和 82.5 万中英文视频描述,其中包括超过 20.6 万描述是中英平行翻译对。它包含 600 种人类活动和不同的视频内容。每个视频具备 10 个英文描述和 10 个中文描述,分别来自 20 个人类标注者。

与广泛使用的 MSRVTT 数据集相比,VATEX 是多语言的,且规模更大、语言更复杂、视频和自然语言描述更加多样化。
具体来说,
VATEX 包含大量中英文描述,支持多语言研究,而这是单语言数据集无法满足的;
VATEX 具备最大数量的视频片段-句子对,且每个视频片段都有多个不同的句子描述,每个描述在整个数据集中都是独一无二的;
VATEX 包含更全面且具代表性的视频内容,覆盖 600 种人类活动;
VATEX 中的中英文语料在词汇方面更加丰富,从而可以生成更自然和多样化的视频描述。
研究者还基于 VATEX 数据集提出了两项视频语言研究任务:1)多语视频描述,即使用紧凑的统一描述生成模型为视频生成多种语言的描述;2)以视频为辅助的机器翻译,即使用视频信息作为额外的时空语境将源语言描述翻译为目标语言描述。
图 1:VATEX 任务示例。(a) 使用紧凑的统一视频描述模型准确地以中英文形式描述视频内容。(b) 机器翻译模型将「pull up bar」错译为「pulling pub」(拉起酒吧),将「do pull ups」错译为「do pull」(做拉)。而有了相关视频语境作为辅助,机器翻译模型可以将英语句子准确地翻译为中文。

研究者在 VATEX 数据集上进行了大量实验,结果表明:
统一的多语言模型不仅能够更高效地生成视频中英文描述,其性能还优于单语模型;
时空视频语境可以有效帮助对齐源语言和目标语言,从而辅助机器翻译。
该研究还讨论了使用 VATEX 数据集进行其他视频语言研究的潜力。
这项研究有哪些贡献
该研究的贡献主要为以下三点:
创建了新型大规模、高质量多语视频描述数据集,有利于视频语言研究领域的发展;对 MSR-VTT、VATEX 英语语料库、VATEX 中文语料库进行了深入对比。
提出了多语视频描述任务,并使用紧凑的统一模型验证了其在生成中英文视频描述时的效率和效果。
首次提出视频辅助的机器翻译任务,并验证了使用时空视频语境作为额外信息对机器翻译性能的提升效果。
VATEX vs. MSR-VTT
研究者对 VATEX 数据集和 MSR-VTT 数据集进行了全面分析。由于 MSR-VTT 只有英语语料,因此研究者把 VATEX 分割成英语语料 (VATEX-en) 和中文语料 (VATEX-zh)。
VATEX 包含针对 41,300 个视频的 413,000 个英文描述和 413,000 个中文描述,这些视频共涵盖 600 种人类活动;而 MSR-VTT 仅包含针对 7000 个视频的 200,000 个描述,视频覆盖 257 种人类活动。除了比 MSR-VTT 规模大以外,VATEX-en 和 VATEX-zh 中的描述句子都更长一些,也更加具体。VATEX-en、VATEX-zh 和 MSR-VTT 的平均句子长度分别为 15.23、13.95 和 9.28。
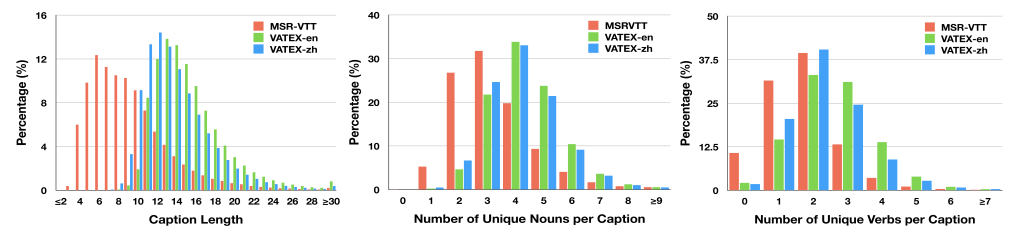
研究者还评估了二者的语言复杂度。他们对比了 VATEX-en、VATEX-zh 和 MSR-VTT 的 unique n-grams 和 POS tags(如动词、名词、副词等),结果表明 VATEX 数据集较 MSR-VTT 有很大提升。VATEX 数据集具备更广泛的描述风格,覆盖更多的动作、物体和视觉场景。
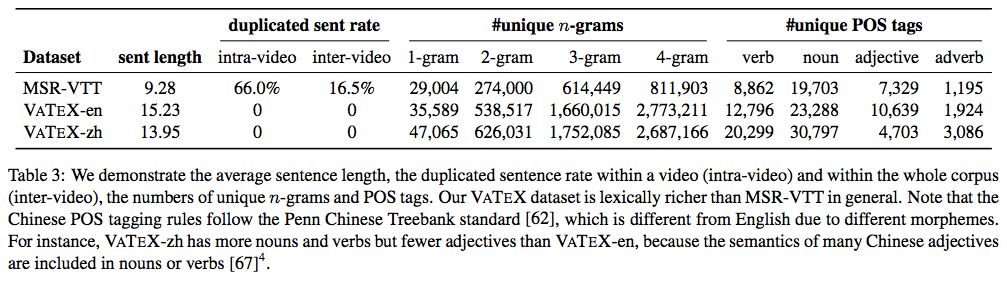
关于视频描述的多样性,该研究也进行了深入对比。如表 3 所示,MSR-VTT 面临严重的重复问题,66% 的视频具备同样的描述,而 VATEX 数据集没有这个问题,不仅如此,同一个视频中的描述也不会出现重复。此外,VATEX 数据集中的视频描述句子在整个语料库中都更加多样化,这表明 VATEX 数据集可以作为视频检索的高质量基准。
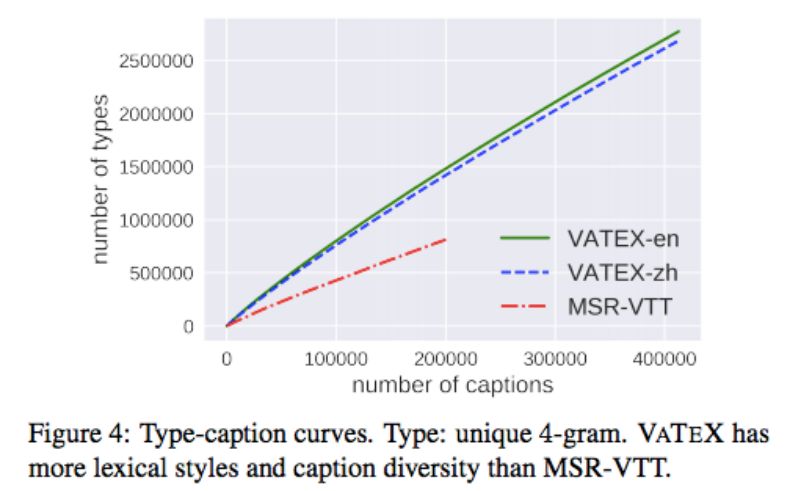
为了更直观地衡量词语丰富性和描述多样性,研究者提出了 Type-Caption Curve。如下图 4 所示,VATEX 数据集具备更强的语言复杂度和多样性。
多语视频描述任务
多语视频描述任务即用超过一种语言(如英文和中文)描述视频内容。
模型
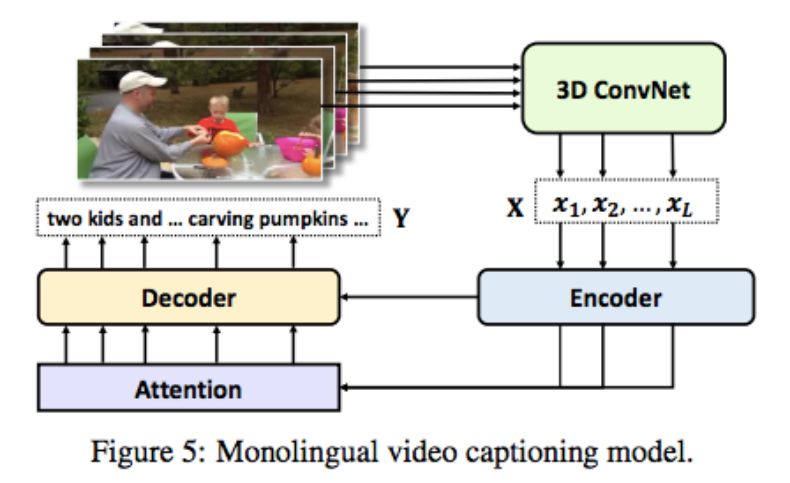
该研究使用的单语视频描述基线模型如下图所示:
该研究使用了三个不同的多语视频描述模型,分别是:
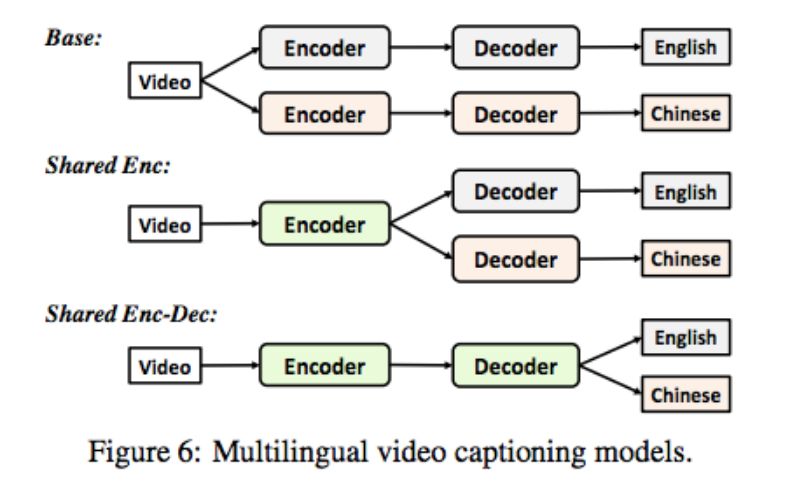
两个 Base 模型:两个分别为英文和中文训练的单语编码器-解码器模型(如图 5 所示)的组合;
Shared Enc 模型:共享视频编码器,但有两个语言解码器,分别适用于英文和中文;
Shared Enc-Dec 模型:仅有一个编码器和一个解码器,中英文共享编码器和解码器,唯一的区别是不同语言的词嵌入权重矩阵不同。
如下图所示:
结果
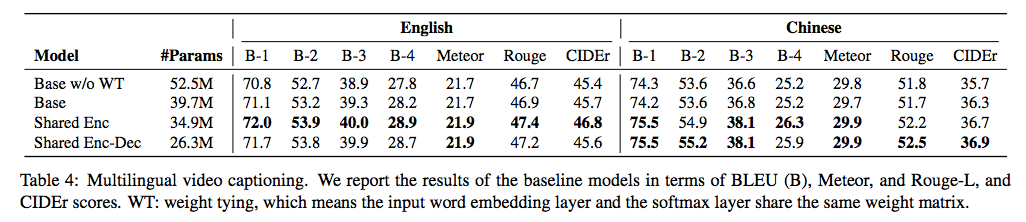
上表展示了三个基线模型在英文和中文测试集上的结果。多语模型(Shared Enc 和 Shared Enc-Dec)的性能优于单语模型 (Base)。这表明多语言学习通过共享视频编码器确实可以帮助视频理解(Shared Enc 模型的性能最优)。更重要的是,Shared Enc 和 Shared Enc-Dec 的参数量相比 Base 模型大大减少(分别减少了 4.7M 和 13.4M)。
这些观察结果证明,紧凑的统一模型能够生成多语言描述,视觉理解可以从多语言知识学习中受益。研究者认为专门的多语模型可能会进一步提升对视频的理解,带来更好的结果。
视频辅助的机器翻译
视频辅助的机器翻译 (VMT),即将视频信息作为时空语境帮助将源语言句子翻译成目标语言。该任务在很多现实世界应用,如翻译社交媒体中带有视频内容的帖子。
模型方法
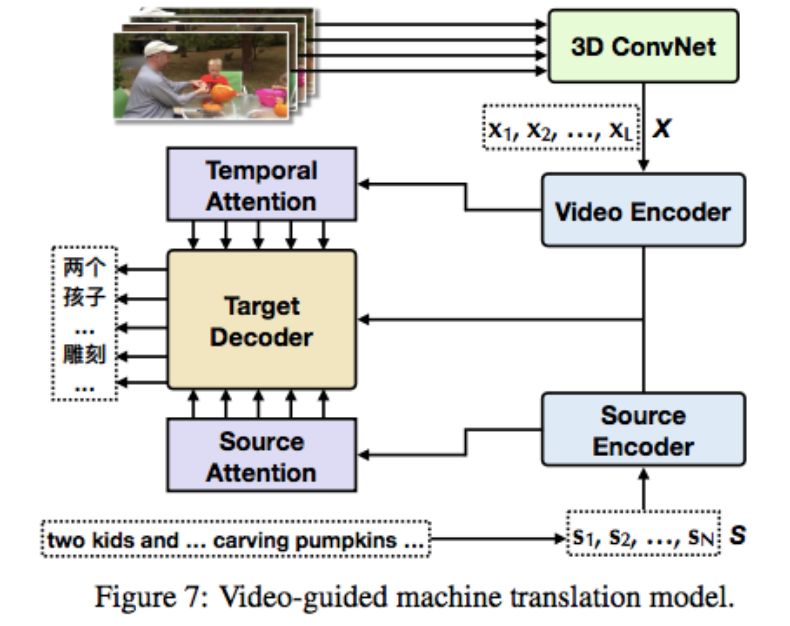
在 VMT 中,翻译系统使用源语言句子和对应的视频作为输入,生成目标语言句子。为了高效利用这两种模态(文本和视频),该研究设计了一个具备注意力机制的多模态序列到序列模型。该模型包含三个模块:源语言编码器(Source Encoder)、视频编码器(Video Encoder)和目标语言解码器(Target Decoder),模型架构如下图所示:
实验
研究者使用以下三个基线模型:
神经机器翻译模型(Base NMT 模型):仅考虑文本信息,采用编码器-解码器模型和注意力机制;
视频特征均值模型(Average Video Features):模型架构和 Base NMT Model 相同,但该模型不仅考虑文本信息,也考虑了视频信息;
LSTM 视频特征模型(LSTM Video Features):该模型与该研究提出的 VMT 模型相同,但是它缺少了时间注意力(temporal attention)。
表 5 展示了 4 个不同模型在英中、中英翻译任务上的结果。Average video Features 模型和 LSTM Video Features 模型性能较 Base NMT 模型有所提升,这表明被动接收和考虑视频特征对于对齐源语言和目标语言是无效的。

但是,使用具备时间注意力的 LSTM Video Features 模型(即该研究提出的 VMT 模型,表 5 最下面一行 LSTM VI w/ Attn (VMT))模型对视频特征进行动态交互时,翻译系统获得了较大的性能提升。这是因为,使用注意力机制时,语言动态可作为 query,突出视频中的相关时空特征,从而使学得的视频语境帮助源语言和目标语言空间中的词映射。这表明额外的视频信息可以有效提升机器翻译系统的性能。
除了表 5 以 BLEU-4 为度量指标衡量模型性能之外,研究者还提出使用名词/动词恢复准确率(noun/verb recovery accuracy)来准确评估额外视频信息对恢复名词/动词的影响,名词/动词恢复准确率即目标句子中名词/动词准确翻译出来的概率。
下表 6 展示了 NMT 和 VMT 模型在不同 noun/verb masking rate 时的性能:
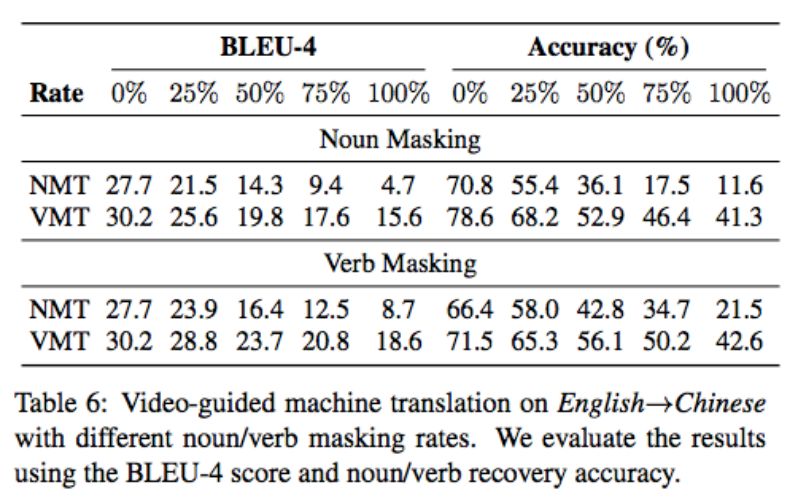
从上表中我们可以看到,VMT 模型的性能持续优于 NMT 模型。此外,随着 masking rate 增加,NMT 模型很难找出正确的名词/动词,而 VMT 可以依赖视频语境获得更多有用信息,因此二者在 recovery accuracy 上的性能差距显著增加。这表明,在 VMT 模型中视频信息对于理解主体、对象、动作及其关系有着重要作用。
一作介绍
该论文共同一作王鑫、吴佳炜均来自加州大学圣塔芭芭拉分校王威廉组。
王鑫现在加州大学圣塔芭芭拉分校读博,本科毕业于浙江大学。其研究兴趣为:语言和视觉;多模态标对导航(multimodal grounded navigation);自然语言生成;视频活动理解。

王鑫所著多篇论文被 ECCV、EMNLP、AAAI、NAACL、CVPR 等顶级会议接收,此前他担任一作的论文《Reinforced Cross-Modal Matching and Self-Supervised Imitation Learning for Vision-Language Navigation》被 CVPR 2019 接收,在评审阶段获得了 3 个 Strong Accept,排名第一,并最终获得了 CVPR 2019 最佳学生论文奖。
吴佳炜现在加州大学圣塔芭芭拉分校读博,导师为王威廉,本科毕业于清华大学,导师为刘知远。其研究兴趣为:在最少人类监督情况下,利用自然信号进行语言理解和生成,具体来讲,他主要研究无监督、自监督和半监督学习场景。此外,他也对视觉和语言的交叉领域感兴趣。

吴佳炜所著多篇论文被 ACL、ICCV、AAAI、CVPR 接收。
本文为机器之心报道,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com



