关于BERT:你不知道的事


近期对BERT系列综述了一番,但记得以前刚接触BERT的时候有很多疑问,之后通过看博客、论文陆续弄明白了。这次就以QA的形式将关于BERT的疑问及其相应解答分享给大家,不足之处,望请指出。关注【NLP有品】后期会不定期分享各个版本bert的详细解读以及实战代码,敬请期待。
(1)BERT 的MASK方式的优缺点?
答:BERT的mask方式:在选择mask的15%的词当中,80%情况下使用mask掉这个词,10%情况下采用一个任意词替换,剩余10%情况下保持原词汇不变。
优点:1)被随机选择15%的词当中以10%的概率用任意词替换去预测正确的词,相当于文本纠错任务,为BERT模型赋予了一定的文本纠错能力;2)被随机选择15%的词当中以10%的概率保持不变,缓解了finetune时候与预训练时候输入不匹配的问题(预训练时候输入句子当中有mask,而finetune时候输入是完整无缺的句子,即为输入不匹配问题)。
缺点:针对有两个及两个以上连续字组成的词,随机mask字割裂了连续字之间的相关性,使模型不太容易学习到词的语义信息。主要针对这一短板,因此google此后发表了BERT-WWM,国内的哈工大联合讯飞发表了中文版的BERT-WWM。
(2)BERT中的NSP任务是否有必要?
答:在此后的研究(论文《Crosslingual language model pretraining》等)中发现,NSP任务可能并不是必要的,消除NSP损失在下游任务的性能上能够与原始BERT持平或略有提高。这可能是由于Bert以单句子为单位输入,模型无法学习到词之间的远程依赖关系。针对这一点,后续的RoBERTa、ALBERT、spanBERT都移去了NSP任务。
(3)BERT深度双向的特点,双向体现在哪儿?
答:BERT使用Transformer-encoder来编码输入,encoder中的Self-attention机制在编码一个token的时候同时利用了其上下文的token,其中‘同时利用上下文’即为双向的体现,而并非想Bi-LSTM那样把句子倒序输入一遍。
(4)BERT深度双向的特点,深度体现在哪儿?
答:针对特征提取器,Transformer只用了self-attention,没有使用RNN、CNN,并且使用了残差连接有效防止了梯度消失的问题,使之可以构建更深层的网络,所以BERT构建了多层深度Transformer来提高模型性能。
(5)BERT中并行计算体现在哪儿?
答:不同于RNN计算当前词的特征要依赖于前文计算,有时序这个概念,是按照时序计算的,而BERT的Transformer-encoder中的self-attention计算当前词的特征时候,没有时序这个概念,是同时利用上下文信息来计算的,一句话的token特征是通过矩阵并行‘瞬间’完成运算的,故,并行就体现在self-attention。
(6)BERT中Transformer中的Q、K、V存在的意义?
答:在使用self-attention通过上下文词语计算当前词特征的时候,X先通过WQ、WK、WV线性变换为QKV,然后如下式右边部分使用QK计算得分,最后与V计算加权和而得。
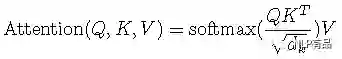
倘若不变换为QKV,直接使用每个token的向量表示点积计算重要性得分,那在softmax后的加权平均中,该词本身所占的比重将会是最大的,使得其他词的比重很少,无法有效利用上下文信息来增强当前词的语义表示。
而变换为QKV再进行计算,能有效利用上下文信息,很大程度上减轻上述的影响。
(7)BERT中Transformer中Self-attention后为什么要加前馈网络?
答:由于self-attention中的计算都是线性了,为了提高模型的非线性拟合能力,需要在其后接上前馈网络。
(8)BERT中Transformer中的Self-attention多个头的作用?

推荐阅读
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏




