前沿 | BAIR开发现实环境的RL机器人,通过与人类的物理交互学习真实目标
选自BAIR
作者:Andrea Bajcsy
机器之心编译
参与:Nurhachu Null、刘晓坤
可交互机器人通常将人类干预当成干扰,在干预撤除后随即恢复原来的轨迹,像弹簧一样执拗,无法根据人类偏好优化动作。伯克利近日开发出可交互学习的机器人系统,以类似强化学习的范式(目标函数不确定),能根据人类干预对自身轨迹进行修正,以最大化奖励,从而可以实时学习人类偏好。
人类每天都在进行彼此间的物理交互—从某人快要撒掉饮料时扶住他/她的手到将你的朋友推到正确的方向,身体上的物理互动是一种用来传达个人喜好和如何正确执行一个任务的直观方式。
那么,我们为什么不和当下的机器人像人一样进行物理交互呢?人类和机器人之间进行无缝的物理交互需要很多条件:轻量级的机器人设计、可靠的力学传感器、安全和反应式的控制方案、预测人类协作者意图的能力,等!幸运的是,机器人学在专门为人类开发的个人机器人设计方面已经取得了很多进步。
然而,再推敲一下我们刚开始就列举的第一个例子,即你在朋友快要撒掉饮料的时候扶住了他/她的手。现在假定你那位即将撒掉饮料的朋友(而不是你)是一个机器人。因为在目前最先进的机器人的规划和控制算法中,通常会将人类的物理干预视为外部扰动,一旦你放开机器人,它将恢复它那错误的轨迹,继续洒出饮料。这种差距的关键在于机器人是如何思考与人类之间的物理交互的:绝大多数机器人会在交互结束之后恢复其初始行为,而不是思考人类为什么根据需求对它进行物理干预并重新规划。
我们认为机器人应该将人类的物理干预视为和它应该如何执行任务相关的有用的信息。我们将机器人对物理干预的反应形式化为一种目标(奖励)学习问题,并且提出了一个解决方案,使得机器人在执行一个任务的时候能够根据在这些交互中得到的信息来改变它们的行为。
对物理交互的推理:未知的干扰与有意义的信息
物理人机交互(pHRI)领域研究的是共享工作空间里亲密的物理交互中出现的设计、控制和规划问题。之前的 pHRI 研究已经开发出了应对机器人在执行任务时面对物理交互的应对方法。由 Hogan(http://summerschool.stiff-project.org/fileadmin/pdf/Hog1985.pdf)等人提出的阻抗控制是常用的方法之一,阻抗控制可以让机器人在有人存在的空间里朝着期望的轨迹移动。使用这个控制方法时,机器人就像一个弹簧一样:它允许人推它,但是在人停止施力之后,它会移回到原来的期望位置。尽管这种策略非常快速,并且能够让机器人安全地适应人类的力量,但是机器人并不会利用这种干预去更新它对任务的理解,机器人将继续以与人类交互之前规划好的方式执行任务。

为什么会是这种情况呢?这可以归结为机器人对任务知识以及它所感知到的力的理解。通常,任务的概念是以一种目标函数的形式被赋予机器人的。这个目标函数为任务的不同方面编码奖励,例如「到达位置 X」,或者「在远离人类的同时朝着桌子移动」。机器人使用它的目标函数来生成可以满足任务所有方面的动作:例如,机器人会朝着目标 X 移动,同时选择靠近桌子和远离人类的路径。如果机器人最初的目标函数是正确的,那么任何外部干扰对它而言都是对它正确路径的干扰。因此,为了安全起见,机器人应该允许物理交互来干预它,但是它最终会返回到计划的最初路径,因为它固执地认为最初的规划是正确的。
相比之下,我们认为人类的干预往往是有目的的,并且是在机器人出错的时候才去干预它。虽然机器人的原始行为相对其预定义好的目标函数可能是最优的,但是需要人类干预的事实则意味着最初的目标函数并不是特别正确。所以,物理的人类干预不再是扰动了,而是对机器人应该呈现的真实目标函数的有用观察。基于这种考虑,我们从逆强化学习(IRL)(http://ai.stanford.edu/~ang/papers/icml00-irl.pdf)中获得一些灵感,即机器人观察到了一些行为(例如被推离了桌子),并且尝试着去推理新的目标函数(例如,「远离桌子」)。请注意,虽然很多 IRL 方法集中在让机器人在下一次做得更好,而我们则关注于让机器人正确地完成当前的任务。
形式化对 pHRI 的反应
基于对物理人机交互的认识,我们可以用一个动态系统来描述 pHRI,其中机器人不能确定正确的目标函数,人类的交互将给它提供信息。这种形式定义了一类广泛的 pHRI 算法,包括现有的阻抗控制方法,使得我们能够得到一种新颖的在线学习方法。
我们将会集中讨论这种方法的两个部分:(1)目标函数的结构;(2)机器人通过给定的人类物理交互推理目标函数的观察模型。让 x 代表机器人的状态(例如位置和速度),uR 代表机器人的动作(例如施加到关节的扭矩)。人类可以通过外部的力矩来与机器人产生物理交互,称作 uH,机器人通过它的动力运动到下一个状态。
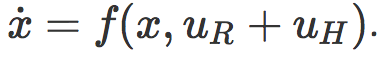
机器人的目标:在最少的人类交互下正确地完成任务
在 pHRI 中,我们希望机器人能够学习人类,但同时我们也不想让人类在持续的物理交互中负担过重。所以,我们可以为机器人定下这么一个目标,既能完成任务,也能最小化所需的交互数量,最终在这则两者之间进行权衡。
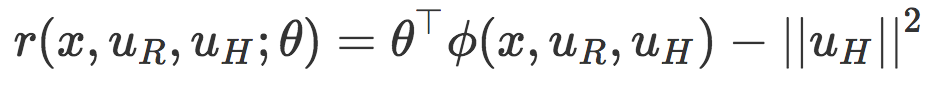
这里,ϕ(x,uR,uH) 对任务相关的特征进行编码(例如,「到桌子的距离」、「到人类的距离」、「到目标的距离」),θ决定每种特征的相对权重。这个函数中,θ封装了真正的目标——如果机器人准确地知道如何给任务的各个方面进行加权,那么它就可以计算出如何以最佳的方式执行任务。然而,机器人并不知道这个参数!机器人并不总会知道执行任务的正确方式,更不用说人类喜欢的方式了。
观测模型:从人类的交互中推理正确的目标函数
正如我们讨论的,机器人应该观察人类的动作来推理位置的任务目标。为了把机器人测量的直接人力与目标函数联系起来,机器人采用了观测模型。在最大熵逆强化学习(IRL)(https://www.aaai.org/Papers/AAAI/2008/AAAI08-227.pdf)中的现有工作和人类行为认知科学模型(http://web.mit.edu/clbaker/www/papers/cogsci2007.pdf)中的玻尔兹曼分布的基础上,我们将人类的干预建模为:机器人在处于状态 x 并采取 uR+uH 的行动时,能够将机器人期望的奖励近似最大化的矫正。这个期望的奖励包含即时奖励和未来奖励,并且由 Q 值描述。
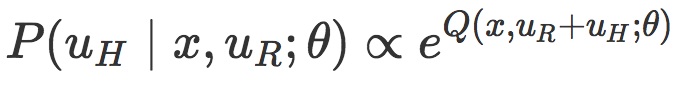
直觉地看,这个模型的解释是,人类更可能选择这样一种物理交互,它能够与机器人的动作结合起来,以形成一个期望的行为(具有高奖励值的行为)。
从人类的物理交互中进行实时学习
就像教一个人类一样,我们希望机器人能够在我们与它交互的时候持续地学习。然而,我们提出的学习框架需要机器人求解一个部分可观测马尔科夫决策过程(POMDP,partial observable markov decision process);不幸的是,我们知道,精确地求解 POMDP 需要昂贵的计算代价,而且在最坏的情况下是无法解决的。然而,我们可以从这种形式中推导它的近似值,这些近似值可以使机器人在与人类交互的同时进行学习和行动。
为了实现这种任务内学习,我们做了三个近似,归纳如下:
1)把求解最优控制策略和估计真实目标函数区分开来。这意味着机器人要在每一个时间步更新它对θ的可能值的置信度,然后重新规划一个满足新分布的最优控制策略。
2)将控制和规划区分开来。计算一个最优控制策略意味着要在连续状态、动作和置信空间中的每个状态计算出一个要采取的最佳行动。尽管在每一次交互之后实时重新计算出一个完全的最优策略是很难的,但是我们可以在当前的状态实时重新计算出一个最优轨迹。这就是说,机器人首先会规划出一个最符合当前估计的轨迹,然后用一个阻抗控制器追踪这个轨迹。我们前面描述过的阻抗控制提供了需要的良好属性,在交互期间,人们可以物理地修改机器人的状态,同时还能保证安全。
回顾一下我们的估计步骤,我们将对轨迹空间进行类似的变换,并且修改我们的观测模型来反映这一点:
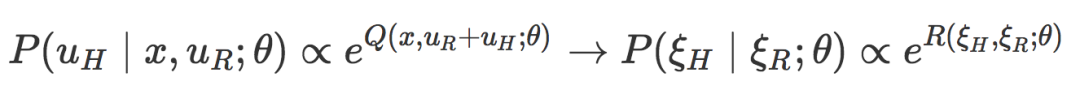
现在我们的观测模型仅仅依赖于在一个轨迹上的累积奖励 R,R 可以通过对所有步骤中的奖励进行求和计算得到。在这个近似中,在推理真实目标函数的时候,在给定当前执行轨迹 ξR 以后,机器人仅须考虑与人类偏好轨迹 ξH 的似然度。
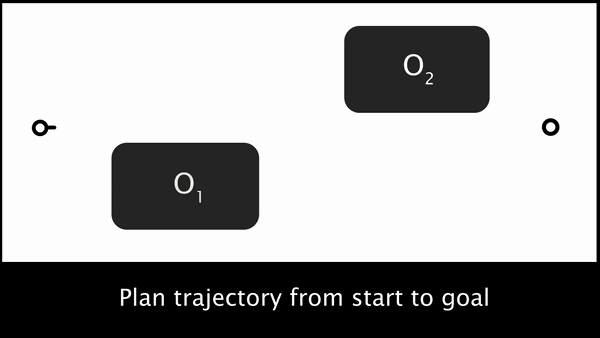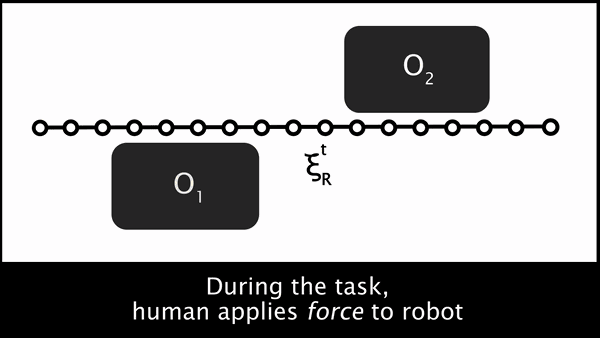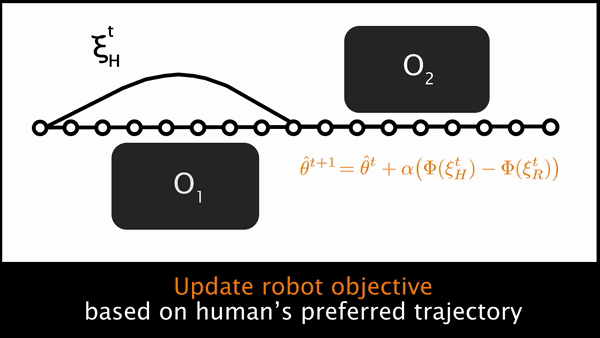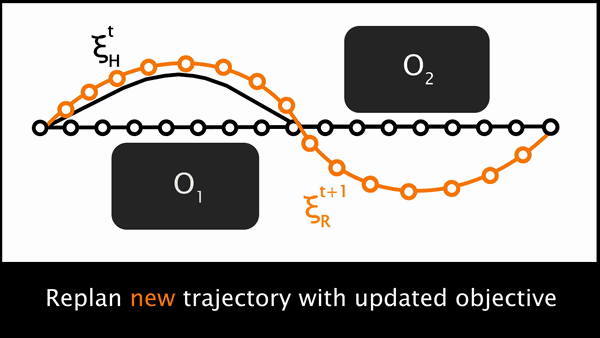
但是,人类的偏好轨迹 ξH 又是什么呢?机器人仅仅会直接测量人类施加的力 uH。一种用来推理人类偏好轨迹的方式是在机器人的当前轨迹上传播人类的力。图 1 建立了基于 Losey 和 O'Malley 之前的工作的轨迹形变,开始于机器人的原始轨迹,然后施加外力,然后施加形变以产生 ξH。
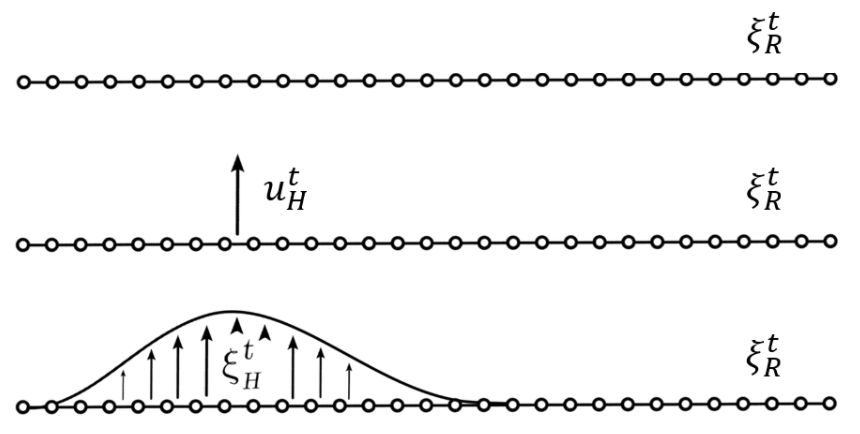
图 1. 为了推理给定目前规划好的轨迹中的人类偏好轨迹,机器人首先测量了人类的交互力 uH,然后平滑地使轨迹上与交互点接近的点发生形变,从而得到人类偏好的轨迹。
3)使用θ的最大后验(MAP)估计进行规划。最后,因为θ是一个连续变量,并且可能会具有较高的维度,加之观测模型是非高斯的,所以我们会仅使用 MAP 估计进行规划,而不是对θ的完全置信。我们发现,在高斯先验条件下,机器人当前轨迹的二阶泰勒级数展开下的 MAP 估计相当于执行在线梯度下降:
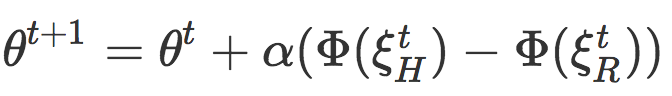
在每一个时间点,机器人会根据其当前最优轨迹和人类的偏好轨迹之间的累积特征差 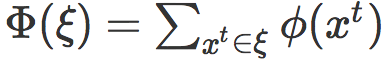
最终,将这三步结合起来就得到了原始 POMDP 的一个优雅的近似解决方案。在每一个时间步骤中,机器人规划一个轨迹 ξR,然后开始移动。人类可以进行物理交互,使得机器人能够感知到人类施加的力量 uH。然后,机器人利用人的力量使其原始轨迹发生形变,并生成人类期望的轨迹 ξH。然后机器人会推理其原始轨迹和人类期望的轨迹在任务的哪些方面存在不同,并在这种差别的方向上更新 θ 的值。然后,机器人使用新的特征权重重新规划一个更加符合人类偏好的轨迹。
您可以阅读我们在 2017 年机器人学习会议上的论文(http://proceedings.mlr.press/v78/bajcsy17a/bajcsy17a.pdf)来了解我们的形式化和近似的全面描述。
在现实世界中向人类学习
为了评价任务内学习在现实个人机器人上的好处,我们招募了 10 名参与者进行用户研究。每位参与者都与运行我们提出的在线学习方法的机器人进行交互,同时将没有从物理交互中学习,只是简单运行阻抗控制方法的机器人作为对比基准。
图 2 展示了三个实验性的居家操作任务,在每一个任务中,机器人开始时都被初始化为一个不正确的目标函数,参与者必须对其进行校正。例如,机器人会把杯子从架子上移动到桌子上,但它不会考虑杯子倾斜(它不会注意到杯子里是否有液体)。
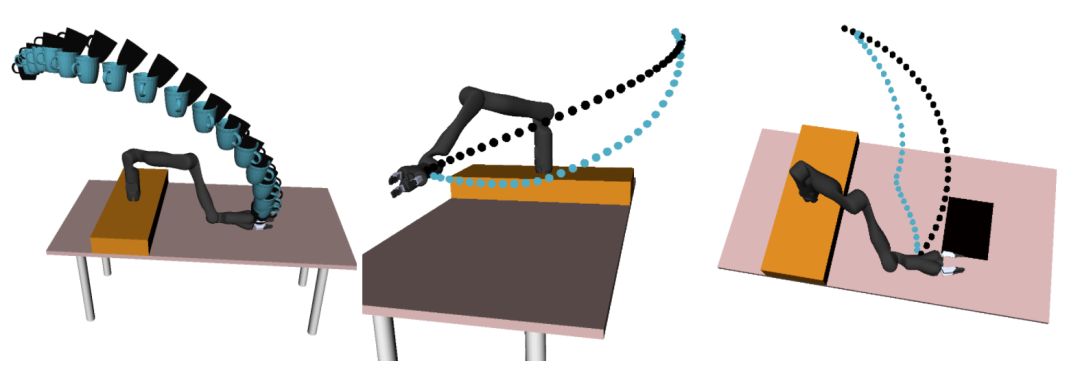
图 2. 初始目标函数被标记为黑色的线,真实目标函数的期望轨迹标记为蓝色线条。参与者需要校正机器人,教它将杯子保持直立(左边),使其朝着桌子移动(中间),并避免经过笔记本电脑(右边)。
我们测量了机器人相对真实目标的性能、参与者付出的努力、交互时间以及 7 点 Likert 量表调查的响应。

在任务 1 中,看到杯子倾斜时,要教机器人使杯子保持直立,参与者必须进行物理干预(图左的阻抗控制不会将杯子保持修正后的状态,图右的在线学习则能实时修正杯子变得直立)。

任务 2 让参与者教机器人靠近桌子(阻抗控制的机器手确实像弹簧,非常执拗)

对于任务 3,机器人的原始轨迹会经过笔记本电脑上方。为了教机器人避免从笔记本电脑上方经过,参与者必须进行物理干预。
我们的用户研究结果表明,从物理交互中学习能够以较少的人力获得更好的机器人任务性能。当机器人正在执行任务期间积极地从交互中学习的时候,参与者能够使机器人以更少的努力和交互时间更快地执行正确的行为。此外,参与者相信机器人能够更好地理解人类的偏好,能够减少他们互动的努力,参与者相信,机器人是一个更具协作性的合作伙伴。
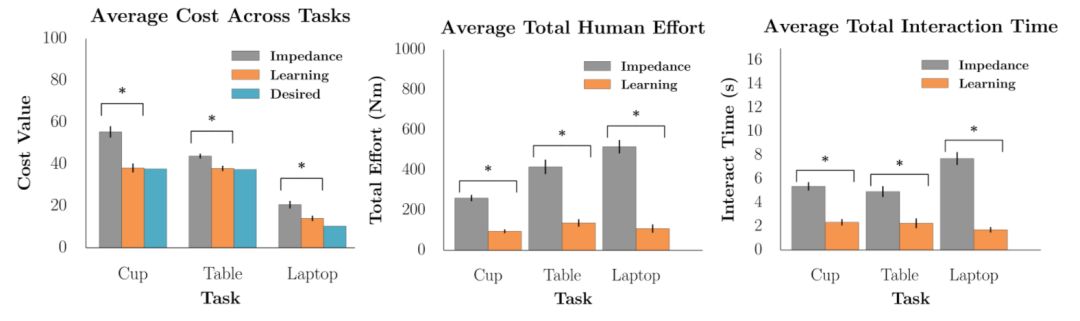
图 3 . 对于每一个目标测量(包括任务代价、人类努力以及交互时间),从交互中学习显著地优于不进行学习的情况。
最终,我们认为机器人不应该将人类的交互作为一种干扰,而应该将其作为提供信息的动作。我们证明,具有这种推理能力的机器人能够更新他们对正在执行的任务的理解并正确地完成任务,而不是依赖于人们引导他们直至任务的完成。
这项工作只是探索从 pHRI 中学习机器人目标的一个简单尝试。很多未解决的问题仍然存在,包括开发能处理动态方面的解决方案(例如关于移动时间的偏好),以及如何/何时将所学的目标函数推广到新任务中。此外,机器人的奖励函数经常会有一些任务相关的特征,人类的交互也许仅仅给出了关于相关权重的一个特定子集的信息。我们在 HRI 2018 中的最新工作研究了机器人如何通过一次只学习一个特征权重来消除对人们试图纠正的错误的歧义。总之,我们不仅需要能够从与人类的物理交互中进行学习的算法,而且这些方法还必须考虑到在尝试动觉地(肌肉运动感觉)教一个复杂的(可能不熟悉的)机器人系统时人类需要面对的固有难度。

这篇博客的主要内容基于以下两篇论文:
A. Bajcsy, D.P. Losey, M.K. O』Malley, and A.D. Dragan. Learning Robot Objectives from Physical Human Robot Interaction. Conference on Robot Learning (CoRL), 2017.
A. Bajcsy , D.P. Losey, M.K. O』Malley, and A.D. Dragan. Learning from Physical Human Corrections, One Feature at a Time. International Conference on Human-Robot Interaction (HRI), 2018.
原文地址:http://bair.berkeley.edu/blog/2018/02/06/phri/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com




