Facebook: 会话机器人最新进展
会话方面的研究是构建强人工智能的重要组成部分。虽然近年来有限场景下的会话机器人广泛使用,但开放领域的会话机器人方面的研究仍存在着极大的挑战。
会话过程中,生成连贯的、有吸引力的回复需要非常巧妙的会话技巧,比如语义的理解和知识推理的使用。Facebook在会话机器人领域做出了很好的研究成果,致力于创造更加有吸引力、个性化的AI系统。本文将介绍开放领域会话机器人的五大挑战:一致性、回复的具体性、情感性、知识引入能力、多模态理解。
1. 一致性
会话机器人的回复不能够自相矛盾,下面给出一个例子:
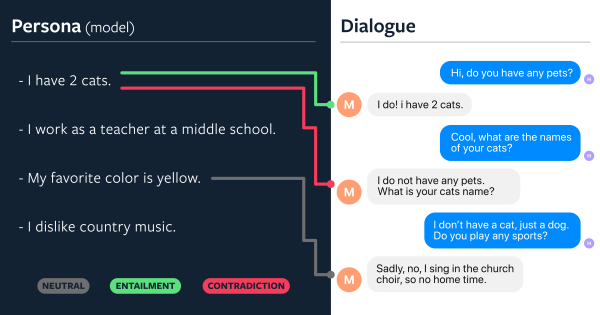
左边的是机器人的回复,第一条回复表示有两只猫,第二条回复却表示自己没有宠物,这样自相矛盾的信息会让会话体验变差。Facebook在论文《Dialogue Natural Language Inference》提出了一个新的模型,大大提升了会话机器人的回复一致性,自相矛盾的回复减少了3倍。
2. 机器人回复要设计的具体程度
很多会话机器人容易产生“没用”的通用回复,例如:我没听懂您说的话,哈哈,哦哦等等。为改善用户体验,有很多研究人员开展会话机器人回复具体程度方面的研究,比如《What makes a good conversation? How controllable attributes affect human judgments》。下面给出一个实例:
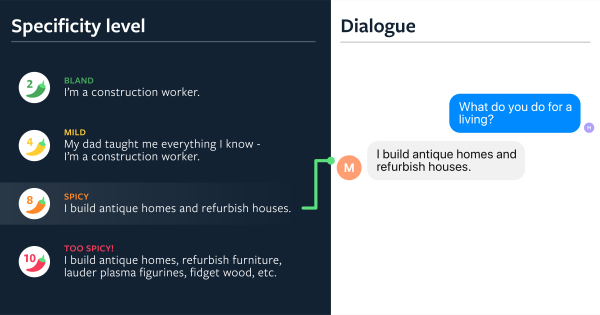
当人类问机器人:你是做什么工作的?机器人可以回答的很粗略,也可以回答的非常具体。哪种方式更好一些呢?请看下图:
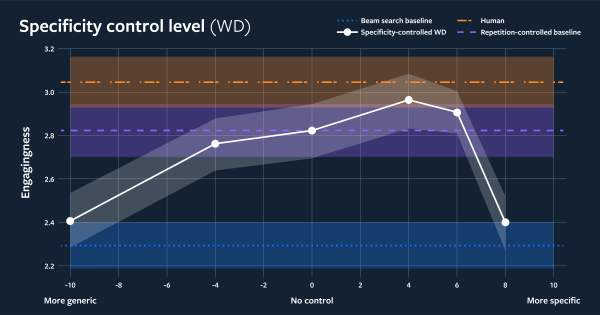
图中横轴是机器人回复的具体程度,纵轴是会话机器人的回复吸引力评价。图中黄色的线条是人类会话的吸引力水平,白色的线条是会话机器人加入了具体程度控制的吸引力水平。我们可以看到机器人的回复并非越具体越好。另外一方面,做好主动提问和回复之间的平衡,或者控制机器人回复的重复程度,都很大程度地影响会话机器人的吸引力。
3. 情感性
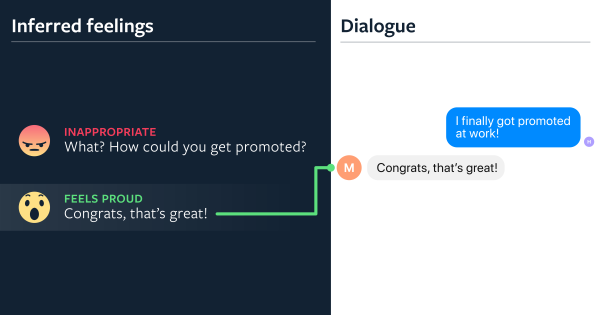
会话机器人的另一大挑战:识别情感并作出适当的反馈。华盛顿大学的学者们在论文《Towards Empathetic Open-domain Conversation Models: a New Benchmark and Dataset》中给出了一个数据集,包含了情感标签,用于衡量会话机器人的情感表达能力。Facebook的研究人员也发现,使用该数据进行fine-tune后,会话机器人在三个模型上的情感表达能力平均提升了0.95分(评分范围为:1-5分),很给力。
4. 知识引入能力
人们在会话过程中通常会谈天说地(引入外部知识),现有的聊天机器人目前很难利用好已有的外部知识。现有的seq2seq模型很难记录历史会话信息,也很难融入外部知识。百度在今年举办的《会话机器人》比赛中,尝试将知识三元组引入会话。Facebook的科学家们也尝试将wikipedia中的知识融入到会话中,发表了论文《Wizard of Wikipedia: Knowledge-Powered Conversational agents》。
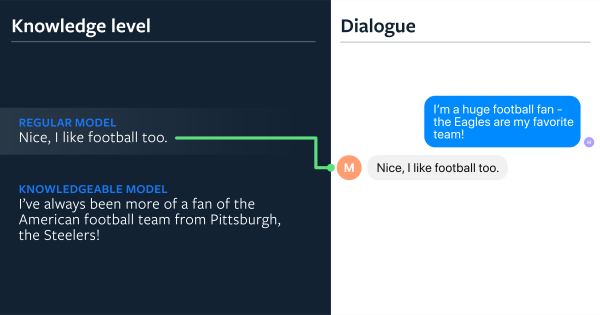
论文提出了transformer memory网络的概念,效果提升显著:吸引力方面提升了26%.
5. 多模态理解
未来的聊天机器人的输入是多方面的,包括语音、图像、文字等。近年来,随着image caption的发展,可以通过图片的理解与用户进行交互。比如论文《Engaging Image Captioning via Personality》,机器人会生成不同态度的image caption。比如,侦测到用户也比较开心时,机器人的回复可以是:“好漂亮的烟花啊!从没见过这么漂亮的烟花。”, 机器人也可以选择“不耐烦”的回复:“烟花虽然好看,但好吵啊”。这些极具个性的回复,能够提升用户的体验。实验表明,与人写的caption相比,用户会更加喜欢个性化生成的caption。
持续学习的会话机器人
Facebook搭建了一套会话产品,用于收集用户数据。每个用户登陆后,可以输入一句话,机器人和另一个真人用户都会进行回复。通过该产品,facebook收集了大量的语料信息。如何使用这些现成的语料不断迭代会话模型呢?Facebook提出了一个self-feeding架构,如下图所示:
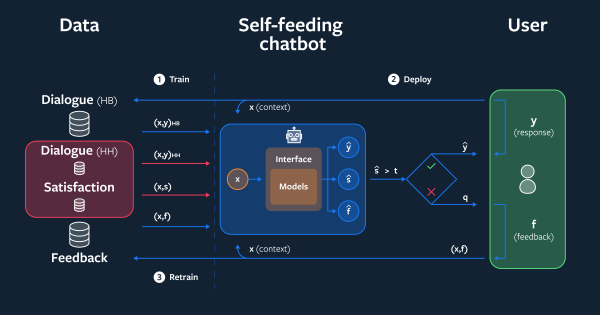
self-feeding会话机器人回复人类用户后,会评估每一次人类用户的满意程度。当用户不满意时,self-feeding会话机器人会收集用户反馈,并构建一个模型用于预测用户的满意度。self-feeding会话机器人会根据满意度,给出一个还不错的回复。使用了该方法后,回复的准确率提升了31%.
Facebook致力于解决开放领域会话机器人的五大挑战:一致性、回复的具体性、情感性、知识引入能力、多模态理解。Facebook也开源了开放领域会话机器人的平台 http://parl.ai,供大家尝试。
如果觉得文章对您有帮助,可以关注本人的微信公众号:机器学习小知识



