少了编码过程,你的节点表示不过是一把39米长的大刀
2017年11月8日,ACM CIKM 2017 学术会议在新加坡举行,中科院计算所网络数据科学与技术重点实验室程学旗老师团队的博士生孙冰杰(指导老师:沈华伟研究员)发表了题为“A Non-negative Symmetric Encoder-Decoder Approach for Community Detection”的论文并作了大会报告。此次报告的意义我觉得是传递一种反思的信号。当一个领域已经处于瓶颈期,我们需要回过头来审视整个领域的发展,给已处于强弩之末的领域再增加一个突破点,扩展它的认识范围赋予它更多的可能性。我们做的这篇论文就是这样一个反思的思路。诚然,深度学习现在比较火,我们暂时不用担心少了这种反思它不会继续向前发展,但是像Community detection这样已经做了很多年的领域,如果没有一个更高层面的新的认识,它将很难继续向前发展。我们这篇文章首次尝试将Community Detection和Network Embedding结合在一起,泛化到网络化数据表示学习(Networked data representation learning)框架之下,在更大的研究范围进行更普适的研究。

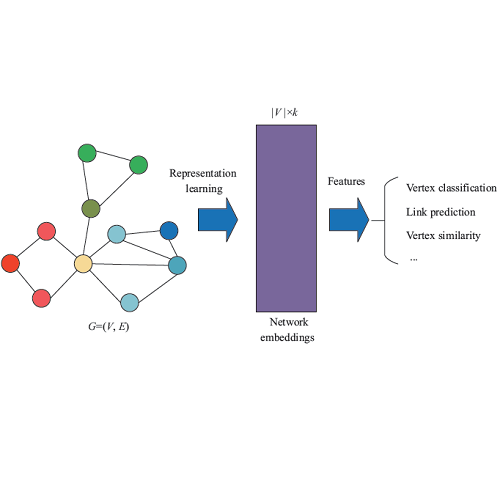
传统的社区发现工作寻找节点关于社区的表示,因此是一种典型的网络节点表示方法。然而社区发现中的节点表示除了指示性作用之外,无法应用于其他任务。Network Embedding方法(如,DeepWalk和LINE等),得到的节点表示可以很好的还原原始空间中的数据相似性,可以支持多种下游任务,但是节点表示本身可解释性很差。很自然的,我们可以想到将两者结合一下,这就是基于隐因子模型(Latent Factor Model, LFM)的方法,这类方法得到的节点表示既可以指示节点的重叠社区归属也可以在一定程度上反映节点在原空间中的相似性,因此成为目前比较流行的方法。
然而,基于LFM的方法只是在对原始数据进行重构,相当于一个解码过程(Decoder)。我套用现在网络上比较流行的一个玩笑,LFM现在只相当于“一把39米长的大刀”,虽然也可以解决大部分问题了,但是这把刀不仅钝而且最有效的那1米并没有。因为LFM优化目标函数中缺少了编码过程(Encoder)导致整个模型容易陷入局部最优(刀钝)并且无法处理新样本数据(刀短)。因此本文提出了同时优化编解码过程的方法,这就是我们将Community detection和Network Embedding融合在一起,我们站在更高的层次上,反思之后看到的问题。
加入编码过程看似只是给原本“39米长的大刀”增加了1米,但是这种对节点表示的微调带来的效用增长却是巨大的。通过编解码过程的对称性使得整个模型可以简单的实现隐式稀疏性约束。增加了编码过程,带来的好处是模型可以快速准确的编码新样本数据,得到的节点表示可以精确支持多种类型输入(邻接矩阵、节点序列等)下的多种类的任务(社区发现、连边预测等),现在你的刀有40米长了。整个模型与LFM的对比如图2所示。
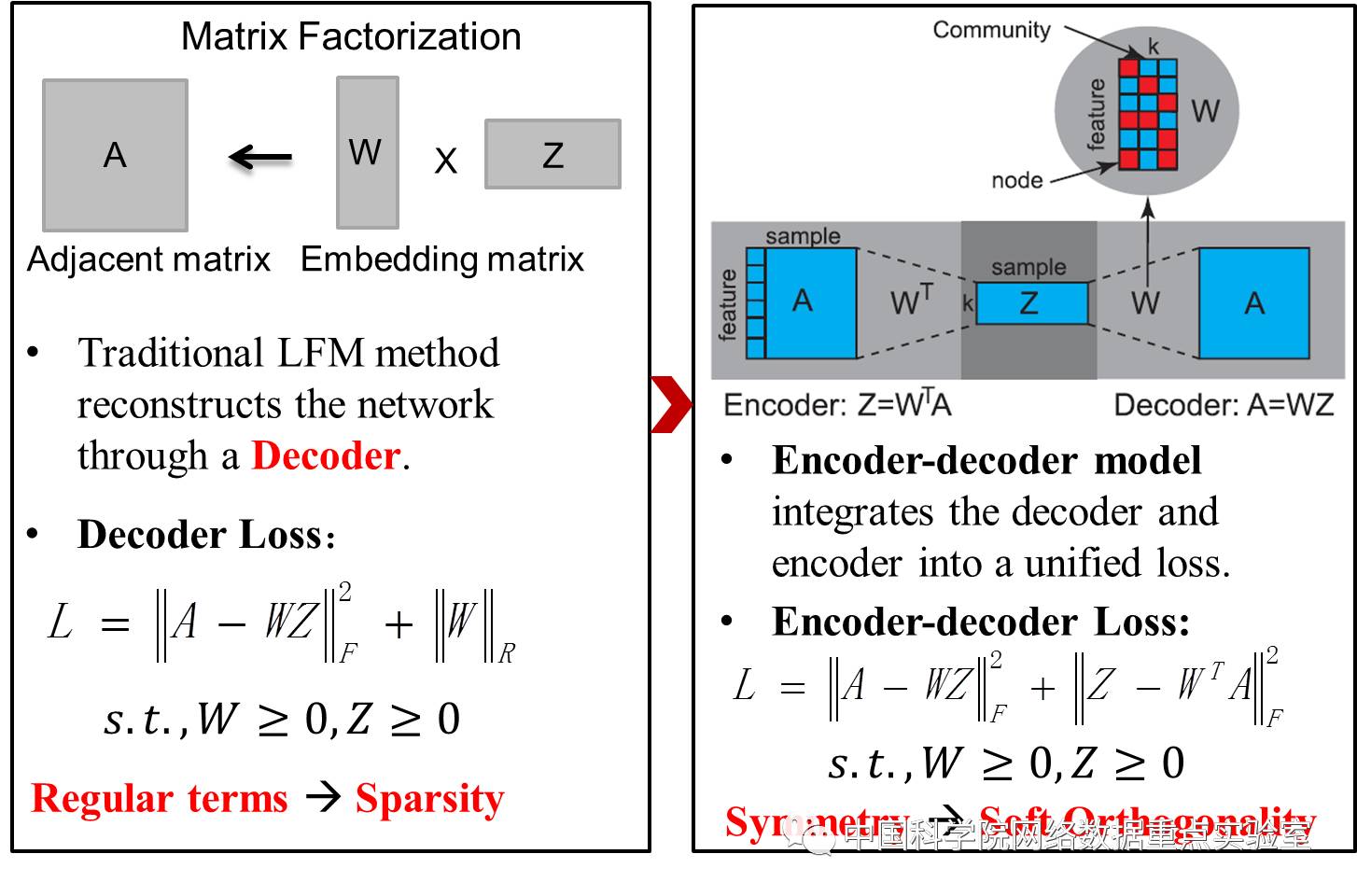
图 2 编解码模型与传统解码模型的对比
我们工作的意义在于站在网络化数据表示学习之上,为Community detection和Network embedding都注入了新的血液,可以容纳更多可以研究的问题,或许我们只是在一个新的靶子上射了一箭,但即使是抛砖引玉能让大家有所思考和收获,也不虚此次CIKM 2017之行了。(详细请参考具体的论文)
Bingjie Sun, Huawei Shen, Jinhua Gao, Wentao Ouyang, Xueqi Cheng. A Non-negative Symmetric Encoder-Decoder Approach for Community Detection. In Proceedings of ACM CIKM’17 conference, Pan Pacific Singapore, Nov 2017.