【CS224N笔记】词向量和词义

作者:艾春辉
学校:华北电力大学、苏州大学准研究生
编辑:王萌(澳门城市大学)
review: Word2vec: More details

wordNet的问题:?
步骤:
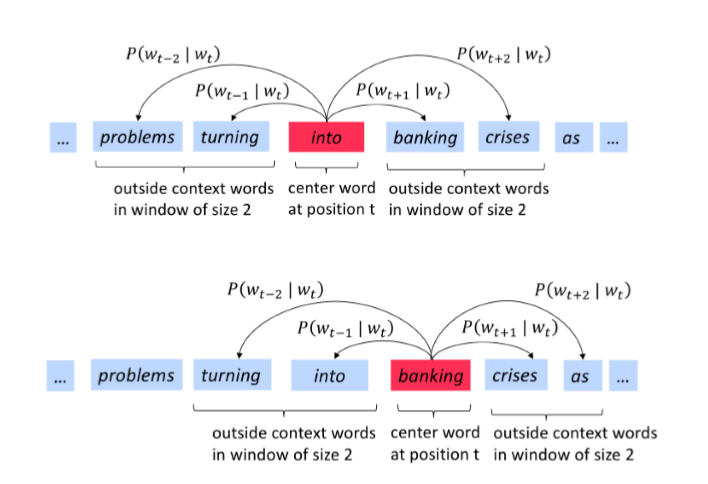
word2vec的一些参数:

为什么每个单词都需要训练两个词向量
两个模型变体
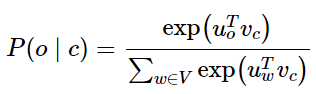
原始的论文中skip-gram模型是最大化的,这里给出:
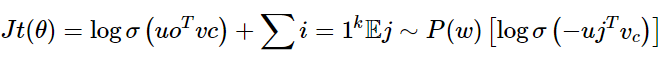
课程中的公式:
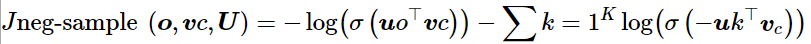
我们希望中⼼词与真实上下⽂单词的向量点积更⼤,中⼼词与随机单词的点积更⼩
k是我们负采样的样本数⽬
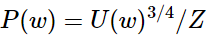
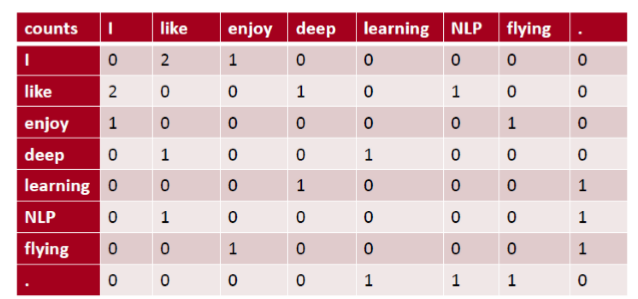
But why not capture co-occurrence counts directly?共现矩阵
共现矩阵 X
利⽤某个定⻓窗⼝中单词与单词同时出现的次数来产⽣window-based (word-word) co-occurrence matrix
let me to tell you a example: 句子
方法一: SVD分解
方法二: Ramped windows that count closer words more----将window倾斜向能统计更接近的单词中
方法三: 采用person相关系数
glove
两种方法:
优点
缺点
优点
缺点
采用共现矩阵的思想对meaning进行编码
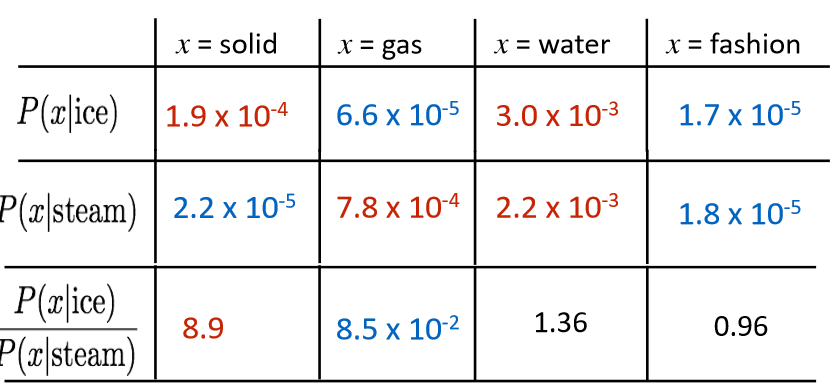
我们如何评判在线性表达下的共现矩阵相似度
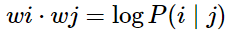
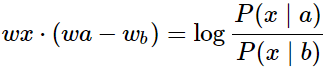
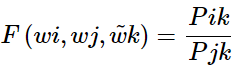
 代表了context vector, 如上例中的solid, gas, water, fashion等。
代表了context vector, 如上例中的solid, gas, water, fashion等。
 则是我们要比较的两个词汇, 如上例中的ice,steam。
的差的形式:
则是我们要比较的两个词汇, 如上例中的ice,steam。
的差的形式:
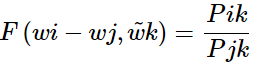 或:
或:
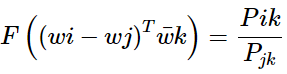
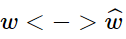 与
与
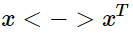 的时候该式仍然成立。如何保证这种对称性呢?
的时候该式仍然成立。如何保证这种对称性呢?
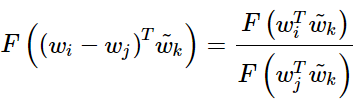
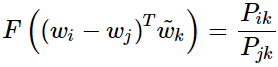 相比较有
相比较有
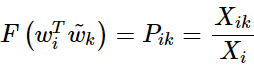
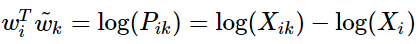
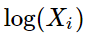 破坏了交换
破坏了交换
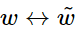 与
与
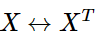 时的对称性, 但是这一项并不依赖于 k 所以我们可以将其融合进关于
时的对称性, 但是这一项并不依赖于 k 所以我们可以将其融合进关于
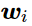 的bias项
的bias项
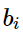 第二部就是为了平衡对称性, 我们再加入关于
第二部就是为了平衡对称性, 我们再加入关于
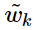 的bias项
的bias项
 我们就可以得到
我们就可以得到
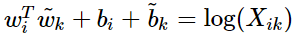 的形式。另一方面作者注宣到模型的一个缺点是对于所有的co-occurence的权重是一样的,即使是那些较少发 生的co-occurrence。作者认为这些可能是噪声声,所以他加入了前面的
的形式。另一方面作者注宣到模型的一个缺点是对于所有的co-occurence的权重是一样的,即使是那些较少发 生的co-occurrence。作者认为这些可能是噪声声,所以他加入了前面的
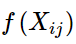 项来做weighted least squares regression模型,即为
项来做weighted least squares regression模型,即为
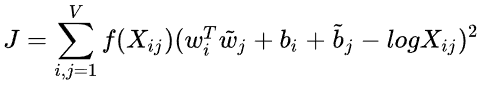 的形式。
的形式。
-
f(0)=0,因为要求 是有限的。 -
较少发生的co-occurrence所占比重较小。 -
对于较多发生的co-occurrence, f(x) 也不能过大。
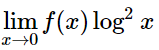
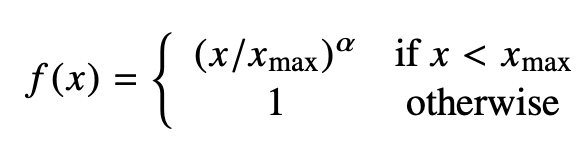
-
优点 -
训练快速 -
可以扩展到⼤型语料库 -
即使是⼩语料库和⼩向量,性能也很好
How to evaluate word vectors?
-
与NLP的⼀般评估相关:内在与外在 -
内在 -
对特定/中间⼦任务进⾏评估 -
计算速度快 -
有助于理解这个系统 -
不清楚是否真的有⽤,除⾮与实际任务建⽴了相关性 -
外在 -
对真实任务的评估 -
计算精确度可能需要很⻓时间 -
不清楚⼦系统是问题所在,是交互问题,还是其他⼦系统 -
如果⽤另⼀个⼦系统替换⼀个⼦系统可以提⾼精确度
Intrinsic word vector evaluation
-
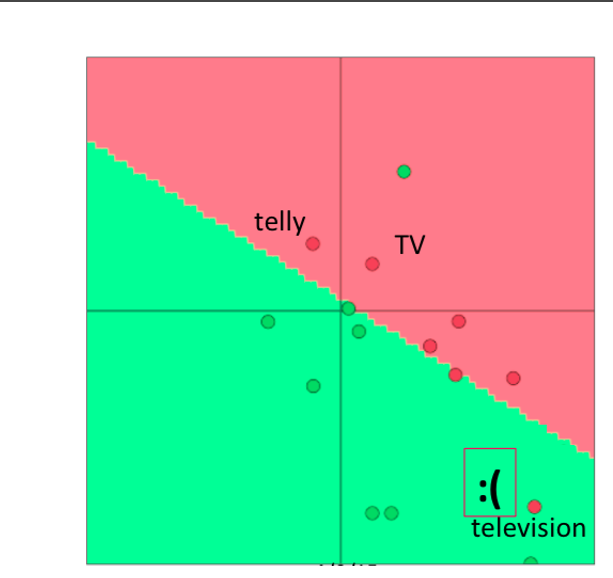
词向量类⽐a:b = c:?,类似于之前的男人对国王,求女人对?
英文解释: This metric has an intuitive interpretation. Ideally, we want xb−xa = xd −xc (For instance, queen – king = actress – actor). This implies that we want xb−xa + xc = xd. Thus we identify the vector xd which maximizes the normalized dot-product between the two word vectors (i.e. cosine similarity). -
一些结果举例子:
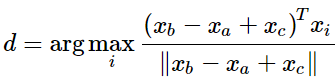
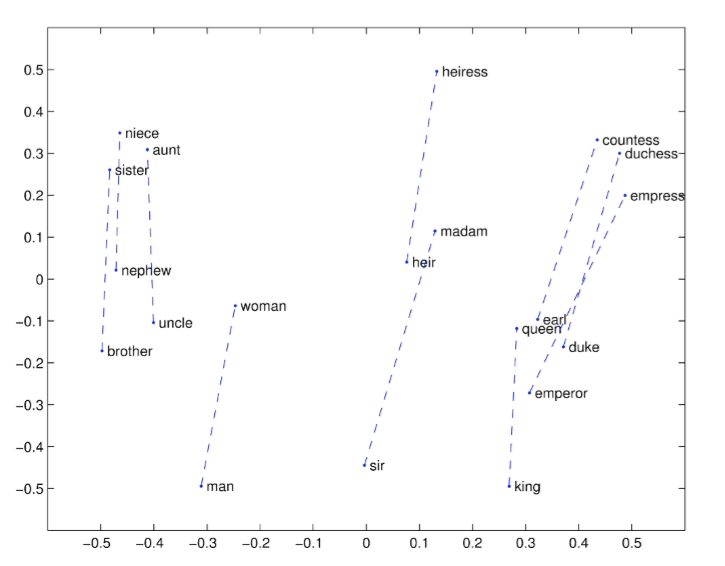
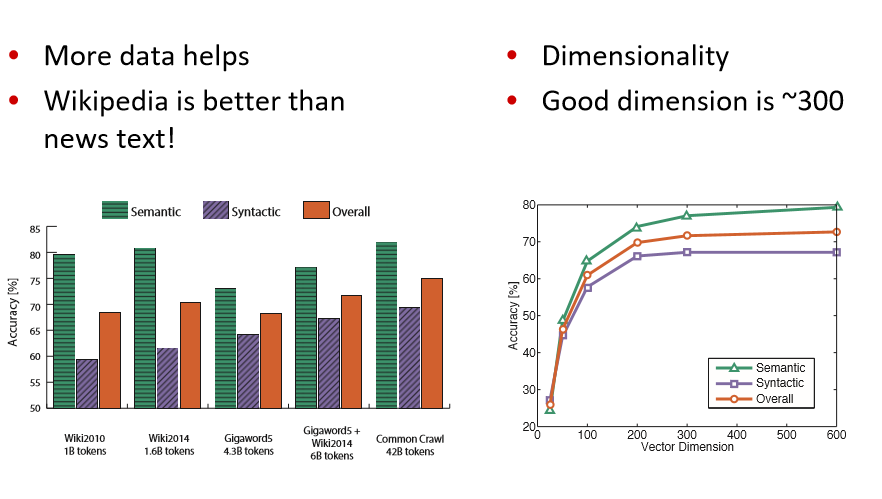
结论
the problem:Most words have lots of meanings!(一词多义问题)• Especially common words • Especially words that have existed for a long time
method1: Improving Word Representations Via Global Context And Multiple Word Prototypes (Huang et al. 2012) -------将常⽤词的所有上下⽂进⾏聚类,通过该词得到⼀些清晰的簇,从⽽将这个常⽤词分解为多个单词,例如 bank_1, bank_2, bank_3

method2: Linear Algebraic Structure of Word Senses, with Applications to Polysemy (Arora, …, Ma, …, TACL 2018)
Different senses of a word reside in a linear superposition (weighted sum) in standard word embeddings like word2vec -----------采用加权和的形式进行处理
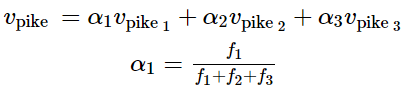
令人惊讶的是,这个加权均值的效果非常好
Training for extrinsic tasks
到目前我们学的为止,我们的目标是内在任务,强调开发一个特别优秀的word embedding。接下来我们讨论如何处理外部任务
Most NLP extrinsic tasks can be formulated as classification tasks. For instance, given a sentence, we can classify the sentence to have positive, negative or neutral sentiment. Similarly, in named-entity recognition (NER), given a context and a central word, we want to classify the central word to be one of many classes. ------许多nlp的task都可以归类为分类任务
for example:我们有一个句子: Jim bought 300 shares of Acme Corp. in 2006,我们的目标是得到一个结果:[Jim]Person bought 300 shares of [Acme Corp.]Organization in [2006]Time.
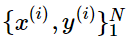
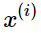 是一个d维度的词向量,
是一个d维度的词向量,
 是一个C维度的one-hot向量,表示我们wished label(情感词语,其他词语,命名主体词语,买卖决策,等)
是一个C维度的one-hot向量,表示我们wished label(情感词语,其他词语,命名主体词语,买卖决策,等)
我们预训练的词向量在外部评估中的表现仍然有提高的可能,然而,如果我们选择重新训练,我们会存在很大的风险------可能效果会比之前差得多
If we retrain word vectors using the extrinsic task, we need to ensure that the training set is large enough to cover most words from the vocabulary. -----因为word2vec和glove会产生一些语义接近的单词,并且这些单词位于同一个单词空间。如果我们在一个小的数据集上预训练,这些单词可能在向量空间中移动,这会导致我们的结果更差
softmax的训练
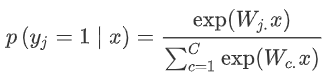
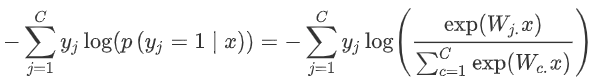
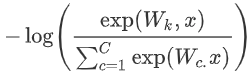
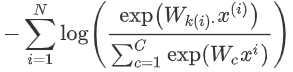
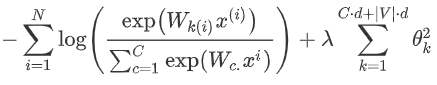
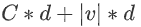 ?
?
我们通常的输入不是一个单词


本文推荐阅读论文:
Improving Distributional Similarity with Lessons Learned from Word Embeddings
Evaluation methods for unsupervised word embeddings
glove原文
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心![]() 。
。
欢迎加入AINLP技术交流群
进群请添加AINLP小助手微信 AINLPer(id: ainlper),备注NLP技术交流
![]()
推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。
![]()
阅读至此了,分享、点赞、在看三选一吧🙏





