【NLP专题】斯坦福CS224n课程笔记03:词向量表示(2)——深入探究词向量
【导读】专知内容组近期将会推出自然语言处理、计算机视觉等国外经典课程笔记系列。我们将首先介绍基于深度学习的自然语言处理的相关知识及应用。本系列博文基于斯坦福CS224n 2018最新课程进行总结,希望大家喜欢。
上一次我们讲解一下词向量的概念,详细说了WordNet、one-hot vectors和Word vectors 这三种方式的优劣,并且介绍了Word2vec目标函数梯度计算和其优化方法。这节课主要给大家深入讲解词向量,并且讲解其优劣,介绍了基于窗口的共现矩阵的方法,引入GloVe。最后介绍了内部和外部词向量评估机制。感兴趣的读者可以详细阅读一下。
【NLP专题】斯坦福CS224n课程笔记01:自然语言处理与深度学习简介
【NLP专题】斯坦福CS224n课程笔记02:词向量表示(1)
2018CS224n官网:
http://web.stanford.edu/class/cs224n/index.html
2017CS224n官方笔记:
https://github.com/stanfordnlp/cs224n-winter17-notes
2017CS224n视频地址:
https://www.youtube.com/watch?v=OQQ-W_63UgQ&list=PL3FW7Lu3i5Jsnh1rnUwq_TcylNr7EkRe6
2017CS224n国内在线观看:
https://www.bilibili.com/video/av13383754
cs224n深度学习与NLP课程详细信息可以参见专知以前的内容:
【最新】2018斯坦福cs224n深度学习与NLP课程又开课了(附ppt下载)
Lecture 03 Word Vectors(2)—— More Word Vectors
本节课计划——深入探究Word Vectors
1. 继续完成Word2vec的学习
2. 从Word2vec可以得到什么
3. 如何更有效地捕捉Word2vec的本质
4. 如何分析和评估词向量
一. 上节课回顾
1. Word2vec的主要思路
•遍历整个语料库的所有单词
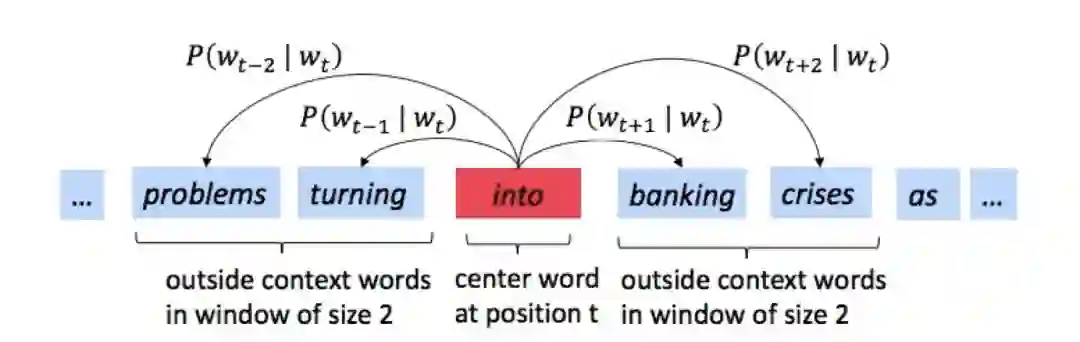
•预测每个单词周围的单词(以一个特定的窗口大小),如下图的例子所示,窗口大小为2。
•预测函数(predictionfunction)
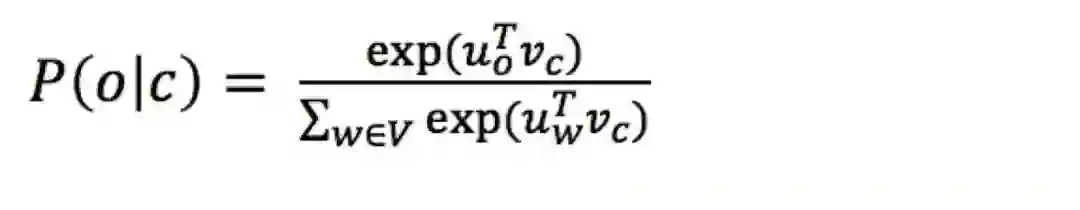
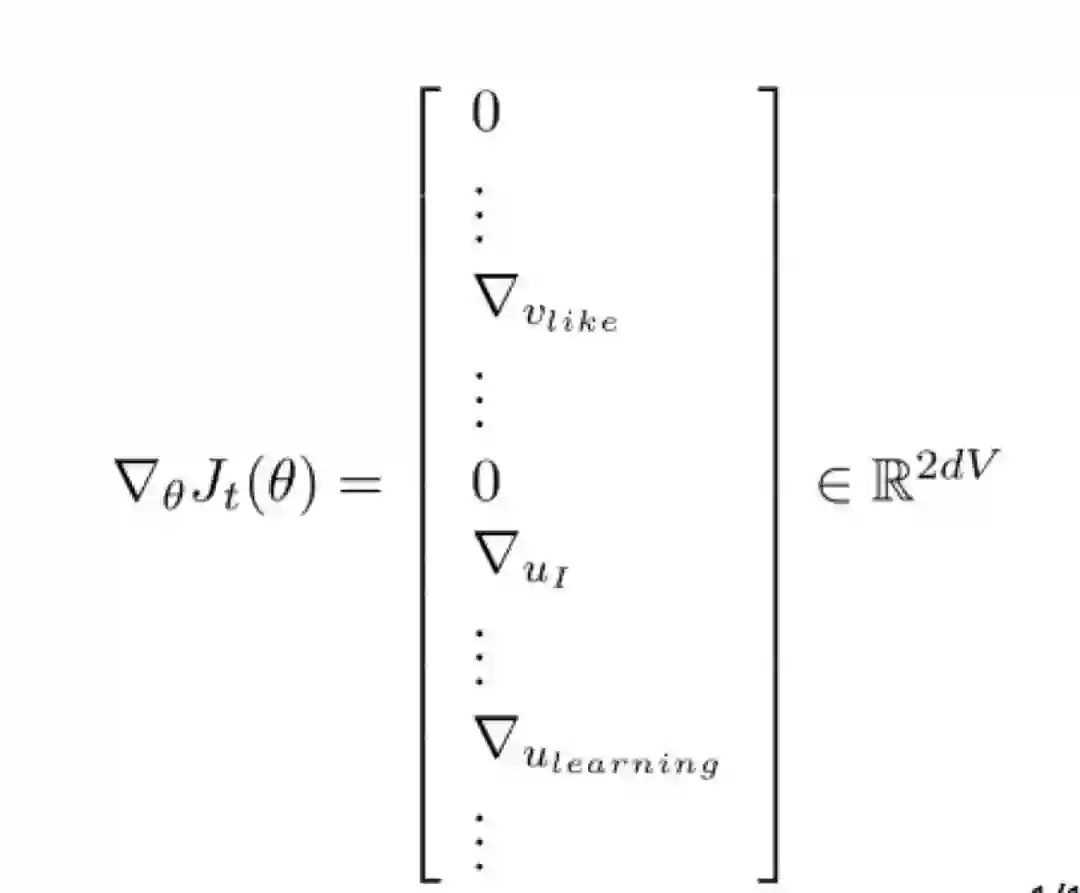
2. 带有词向量的随机梯度(Stochasticgradients with word vectors)
•然后在每一个这样的窗口(window)计算梯度(take gradients)进行随机梯度下降(SGD)
•但是每个窗口最多只有2m + 1个单词(m为窗口大小),所以会非常稀疏(sparse)! 因为我们只更新那些实际上真正出现的单词。
•解决办法:1.进行稀疏矩阵操作,你只需要更新full embedding 矩阵U和V的某些特定的列; 2.为每个词语建立到词向量的哈希映射
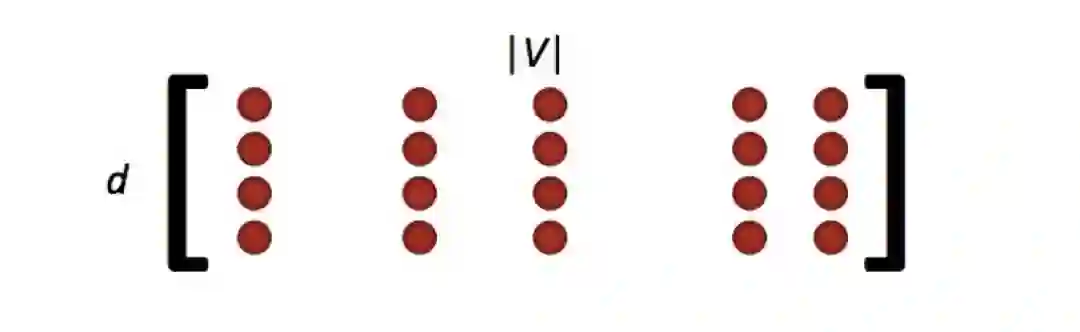
•如果你有数百万个词向量,并且做distributed计算,那么不需要进行庞大的更新是很重要的!
3. 近似(Approximations)——负采样(negative sampling)
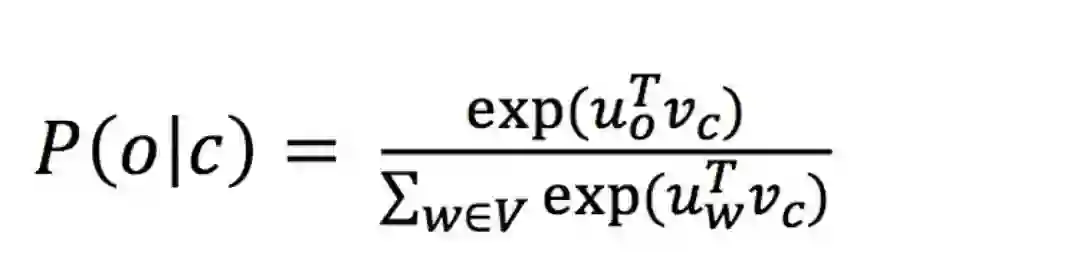
•这个公式中,如果词表V的量级非常大的话,分母正则化的计算代价会很大。
•因此,在assignment 1中要求你们用negative sampling实现skip-gram。
•主要思想:这是一种采样子集简化运算的方法。具体做法是,对每个正例(中心词语及它的上下文中的一个词语)采样几个负例(中心词语和其他随机词语),训练binary logistic regression(也就是二分类器)。
•Word2vec通过在空间中放置相似的词来提高目标函数。

4. Word2vec总结
•浏览整个语料库的每个单词
•预测每个单词的周围单词
•这样可以一次获取一个的同时出现(co-occurrence)的单词
5. 问题:为什么不直接获取同时出现(co-occurrence)发生的次数呢?
Yes, we can! 使用一个共现矩阵(co-occurrencematrix):
•两种选择:窗口(windows)或者全文档(full document)
•窗口:word2vec将窗口视作训练单位,在每个单词的周围使用窗口来捕获语法(POS)和语义信息,每个窗口或者几个窗口都要进行一次参数更新。并且很多词串出现的频次是很高的。能不能遍历一遍语料,迅速得到结果呢?
•早在word2vec之前,就已经出现了很多得到词向量的方法,这些方法是基于统计共现矩阵的方法。如果在窗口级别上统计词性和语义共现,可以得到相似的词。如果在文档级别上统计,则会得到相似的文档(潜在语义分析LSA)。
二. 基于窗口的共现矩阵(Window based co-occurrence matrix)
1.举例说明
• 窗口长度为1(更常见的是5 - 10)
• 对称(不相关的左右语境)
• 在如下示例语料库中统计共现矩阵:
– I like deep learning.
– I like NLP.
– I enjoy flying.
可得到如下共现矩阵:
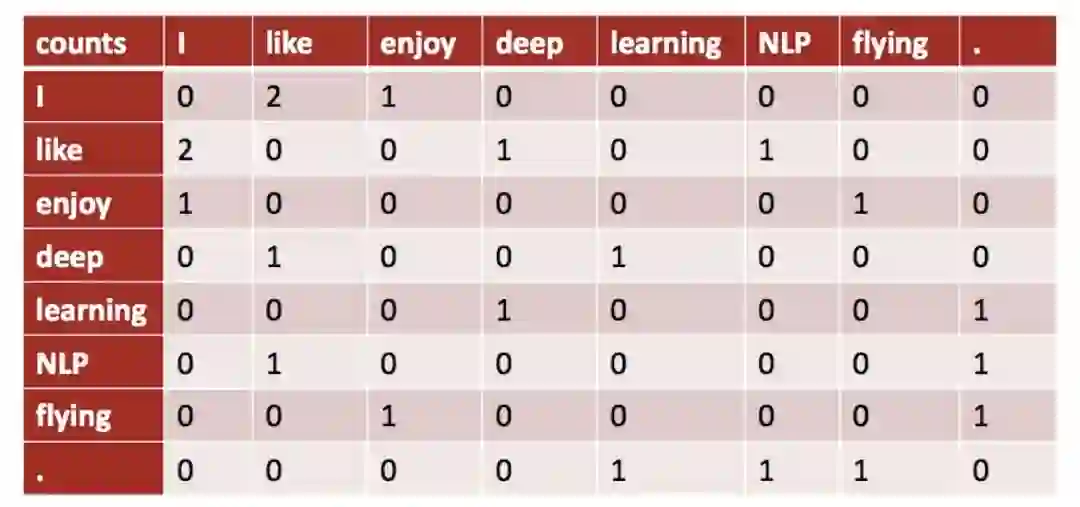
2. 朴素共现向量的问题
根据上述的共现矩阵,可以得到朴素共现向量。但是,会存在一些局限性:
• 随着词表词汇量的增加,维度是不断增加的。
• 非常高维:所以需要大量的存储空间。
• 随后的分类模型存在稀疏性问题,会导致模型不太健壮(less robust)
解决办法:低维向量
3. 低维向量
• 想法:将“大部分”的重要信息存储在一个固定的,少量的维度中:使用一个密集的向量(a dense vector)。
• 通常是25 - 1000个维度,类似于word2vec。
• 问题:如何降维呢?
• 方法一:对(共现矩阵)进行降维。
4. 对共现矩阵进行奇异值分解(Singular Value Decomposition:SVD),如下图所示:

使用Python代码进行SVD操作:
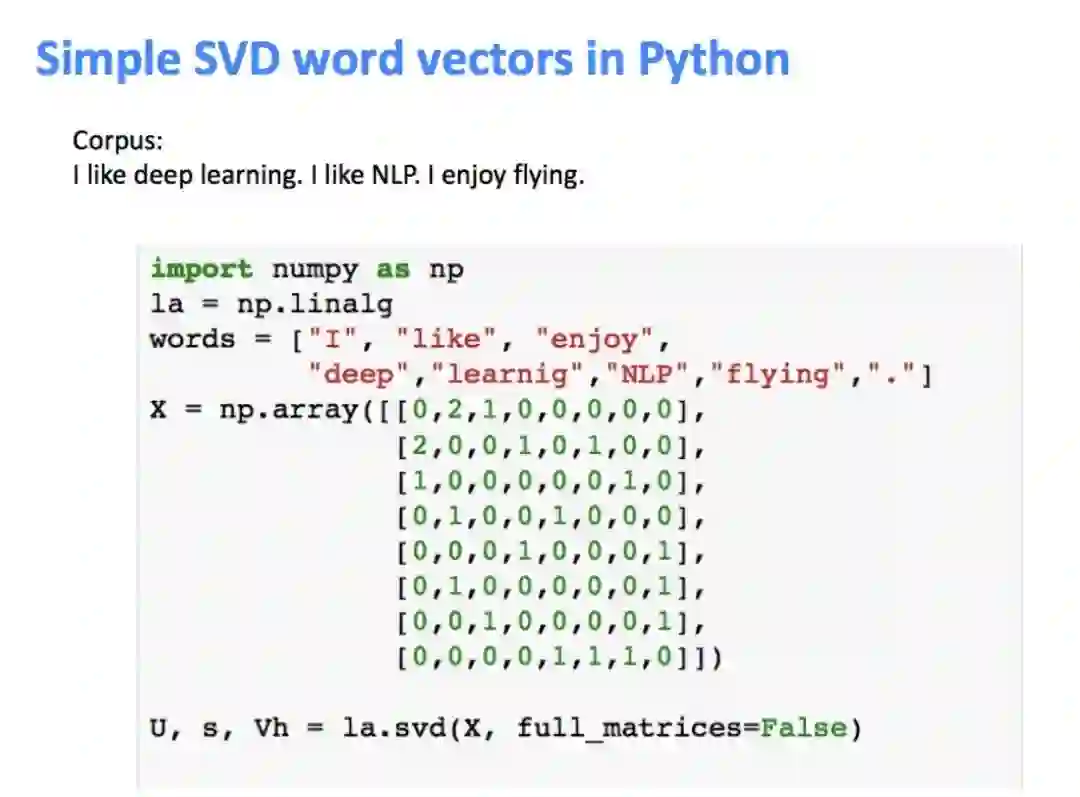
降维之后,取奇异值最大的两列作为二维坐标可视化:
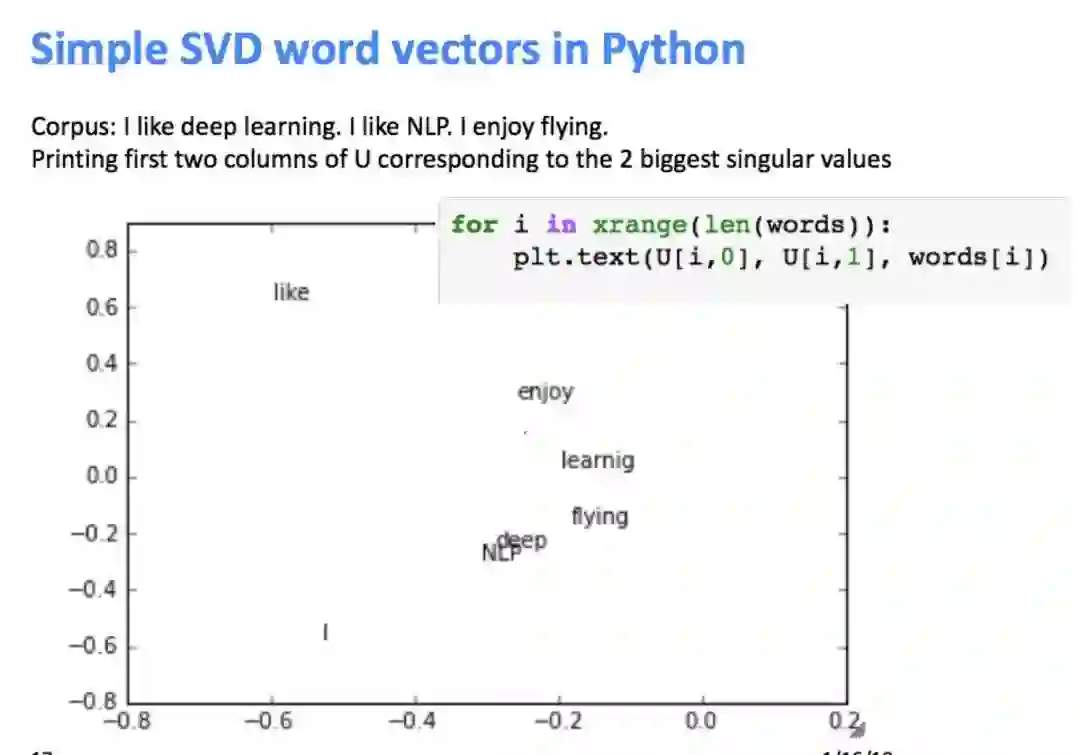
但是一些功能词(the, he, has)出现太过频繁,对语法(syntax)影响较大,上图所示的效果并不十分理想,需要对进行改进:
• 限制高频词的频次,min(X,t),with t~100 ,或者干脆忽略这些高频词
• 增加的窗口更精确地计算相近的单词(ampedwindows that count closer words more)用皮尔逊相关系数( Pearson correlations)代替词频(counts),然后将负值设置为0。
效果:有趣的语义模式出现在向量中(参见论文:An Improved Model of Semantic Similarity Based on LexicalCo-Occurrence Rohde et al. 2005)

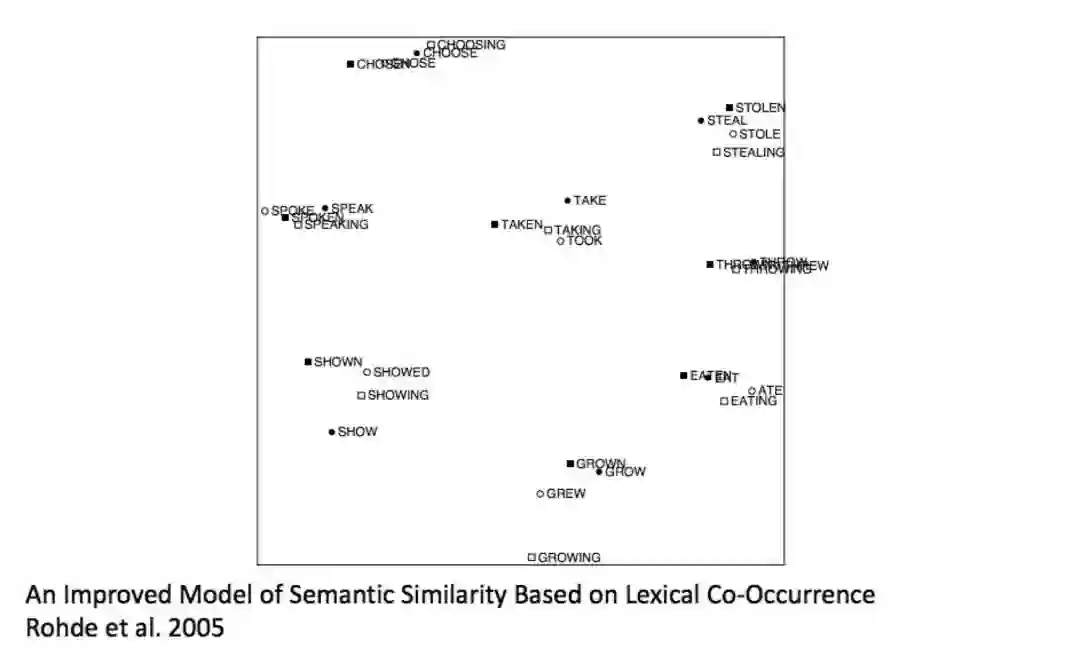
5. SVD的问题:
• 计算代价很大,复杂度很高,对n×m的矩阵是(n<m),所以不利于计算单词数或文档数为数百万的情况
• 不方便处理新词或新文档
• 与其他深度学习模型训练套路不同
6. 基于词频和直接预测的比较(Countbased vs direct prediction)
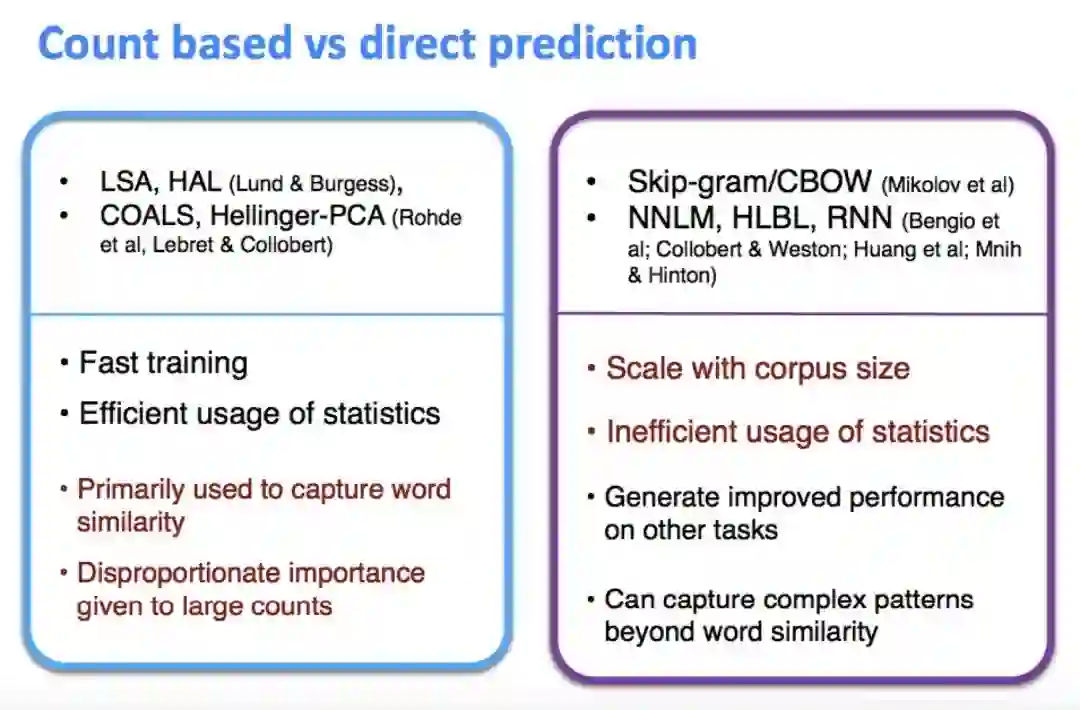
这些基于计数的方法在中小规模语料库中训练很快,可以有效地利用统计信息。但是他们的用途受限于捕捉词语相似度,也无法拓展到大规模语料。
而Skip-gram/CBOW,NNLM,,HLBL,RNN,这些进行预测的模型必须遍历所有的窗口来进行训练,无法有效利用单词的全局统计信息。但它们显著地提高了上级NLP任务,可以捕捉到除了单词相似性之外的更复杂模式。
所以结合上述两者的优势,我们有了:GloVe
7. GloVe (ByPennington, Socher, Manning (2014) )
这种模型的目标函数是:
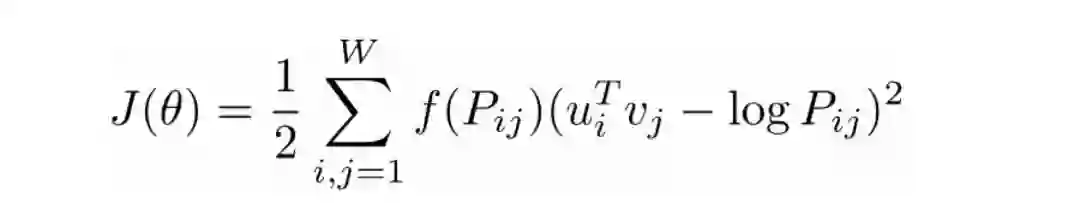
这里的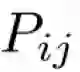
其优点是:训练快,可以拓展到大规模语料,也适用于小规模语料和小向量。在公式中,我们可以发现这里面有两个向量u和v,它们都捕捉了共现信息,我们从和得到两个矩阵U和V,怎么处理它们呢?试验证明,最佳方案是简单地加起来:
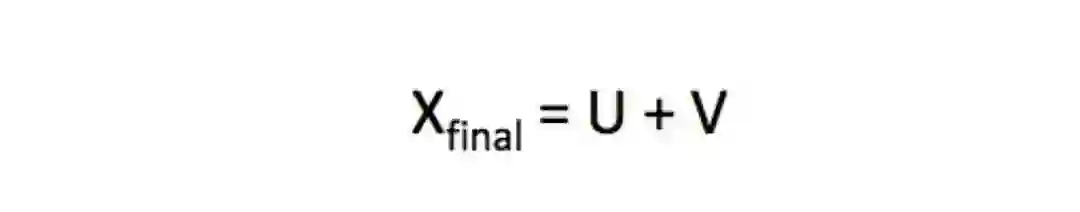
这是GloVe中的众多超参数之一,详情见论文:Global Vectors for Word Representation, Pennington et al.(2014) Glove results.

三. 如何评估词向量?(How to evaluate word vectors?)
有两种方法:Intrinsic(内部)和 extrinsic(外部)
Intrinsic:专门设计单独的试验,由人工标注词语或句子相似度,与模型结果对比。好处是是计算速度快,有助于理解系统。但不知道对实际应用有无帮助。
Extrinsic:通过对外部真实的实际应用的效果提升来体现。耗时较长,不能排除是否是新的词向量与旧系统的某种契合度产生。不清楚是子系统的问题,还是它的交互系统或其他子系统的问题。需要至少两个子系统同时证明。
1. 内部词向量评估(Intrinsicword vector evaluation)
• 也就是词向量类推,或者说“a对于b来讲就相当于c对于哪个词?”。这可以通过余弦夹角得到:

• 通过对单词向量的余弦距离进行分析,可以得到直观的语义和句法类比问题。
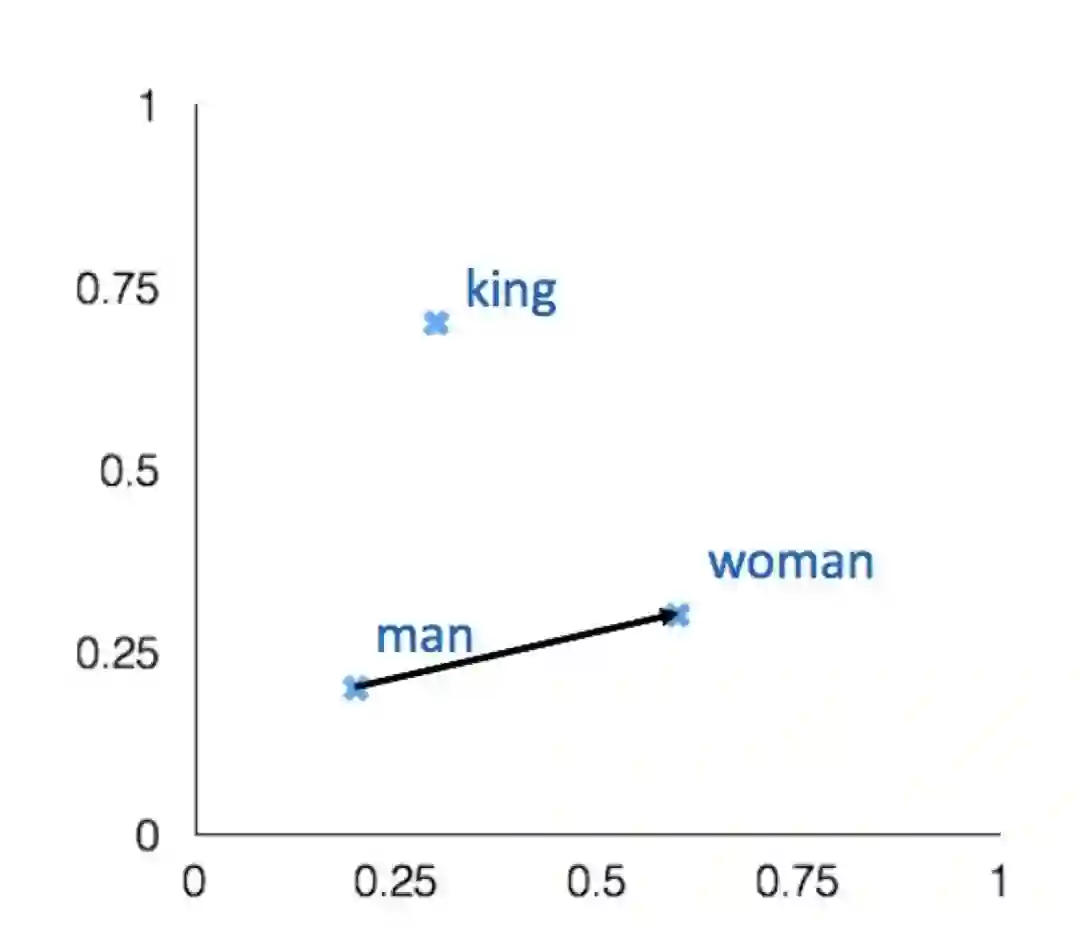
• 从检索中丢弃输入的单词(Discardingthe input words from the search!)
• 问题:如果单词是存在的,但是它们之间不是线性的呢?
• Glove可视化,会发现这些类推的向量都是近似平行的:
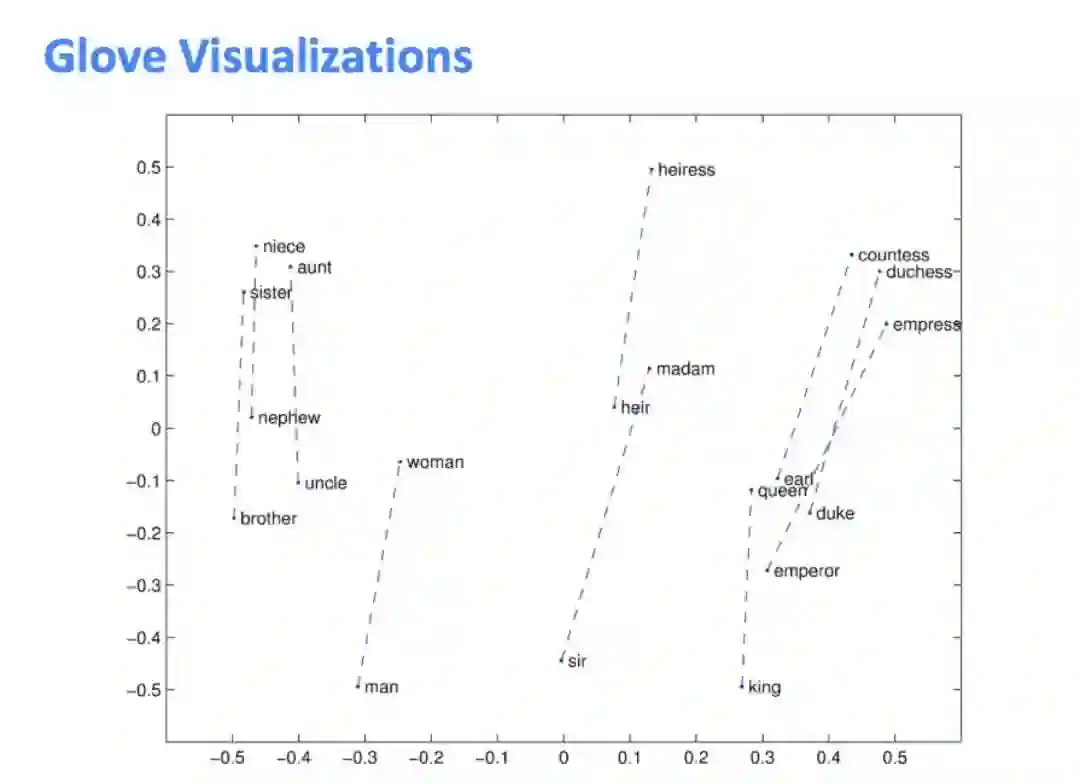
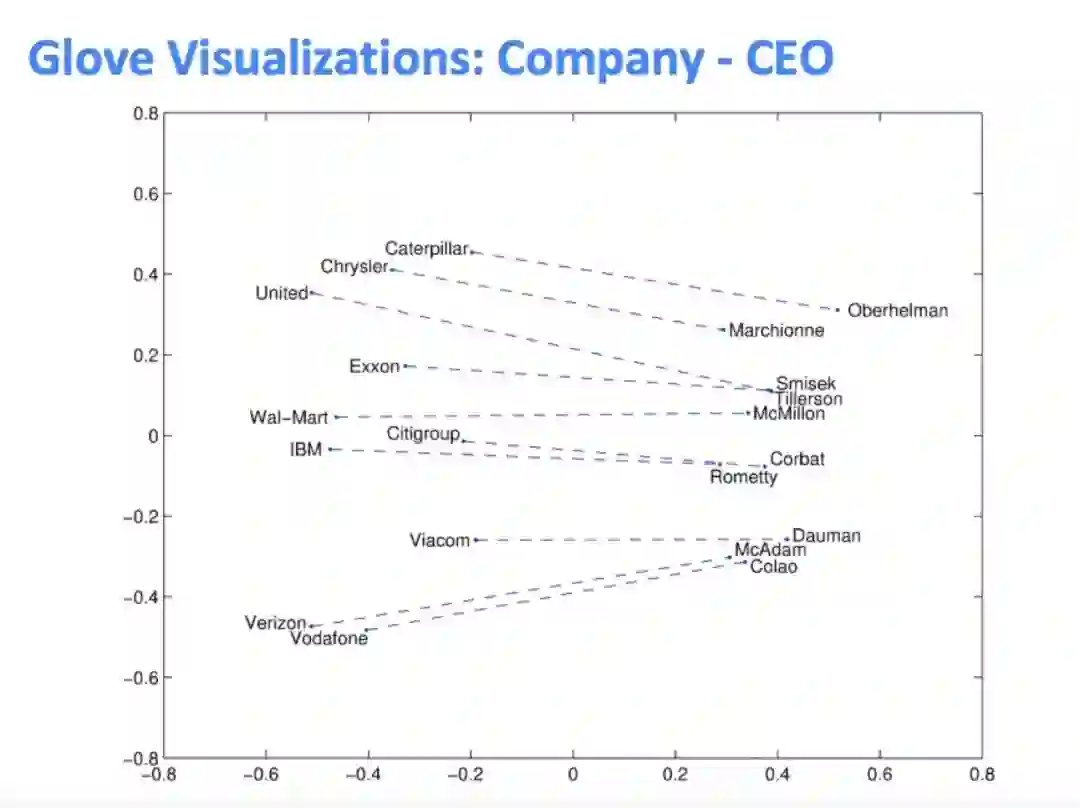
下面这张图说明word2vec还可以做语法上的类比:
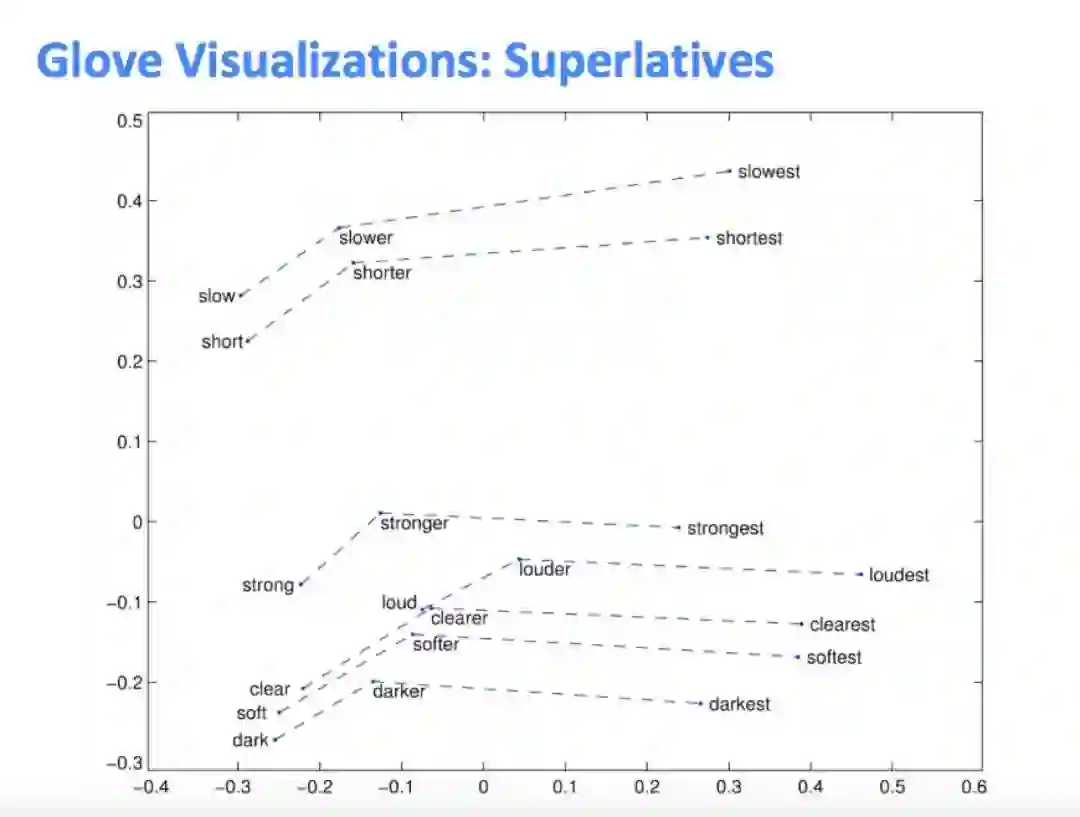
其他有趣的word2vec类比:这在数学上是没有证明的
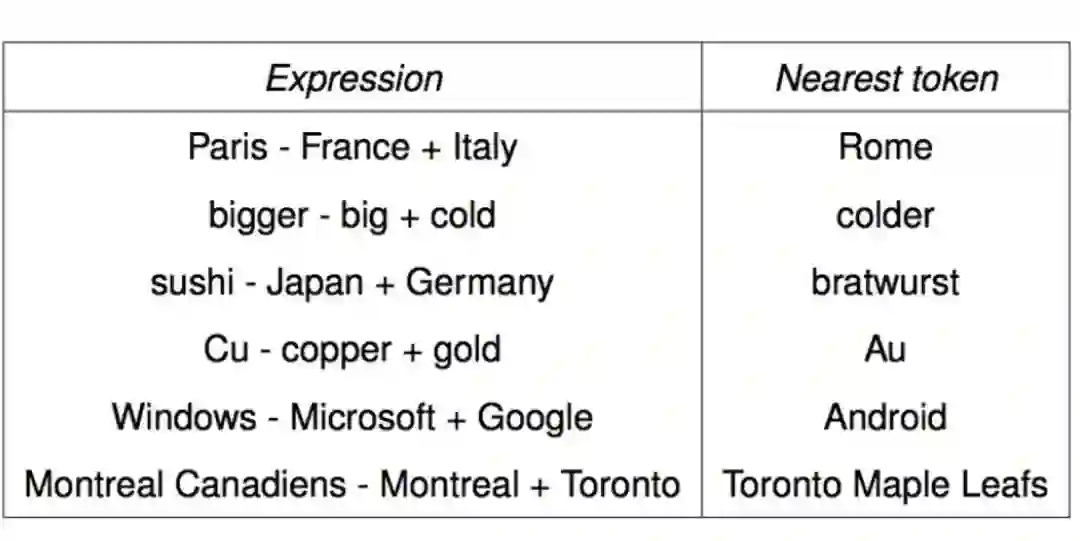
• 内部词向量评估的细节——词向量类比的一些问题




2. 类比评估和超参数
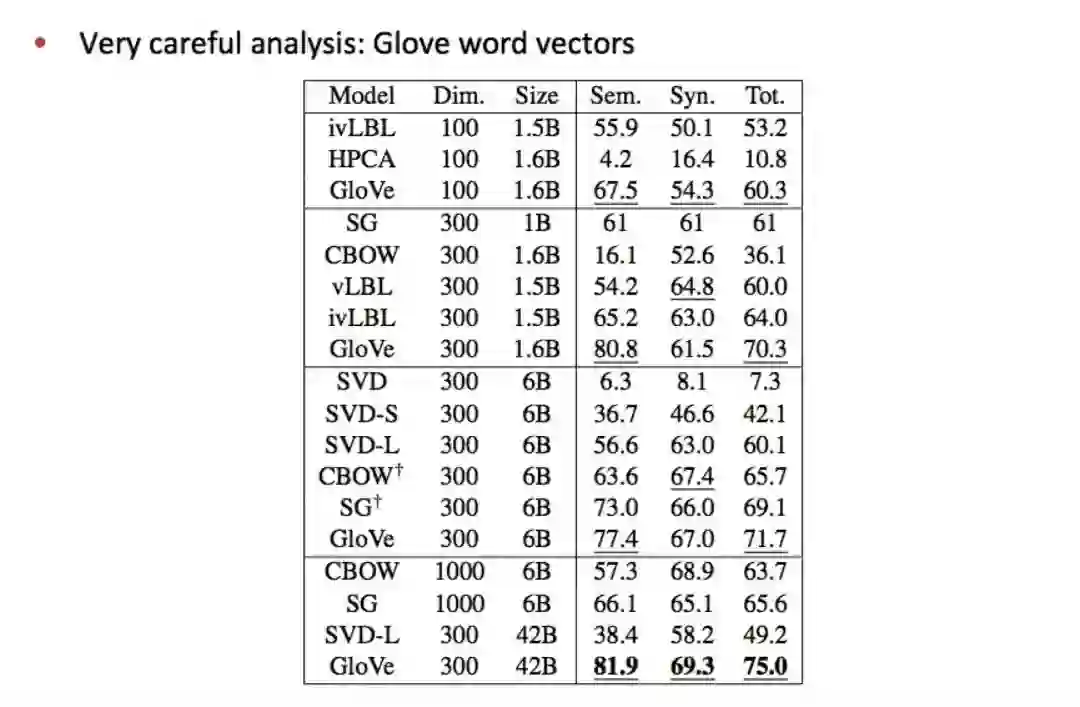
• 结果对比
在不同大小的语料上,训练不同维度的词向量,在语义和语法数据集上的结果如下:GloVe的效果显著地更好。另外,高维度效果并不一定好,而且数据量越多越好。
• 调参
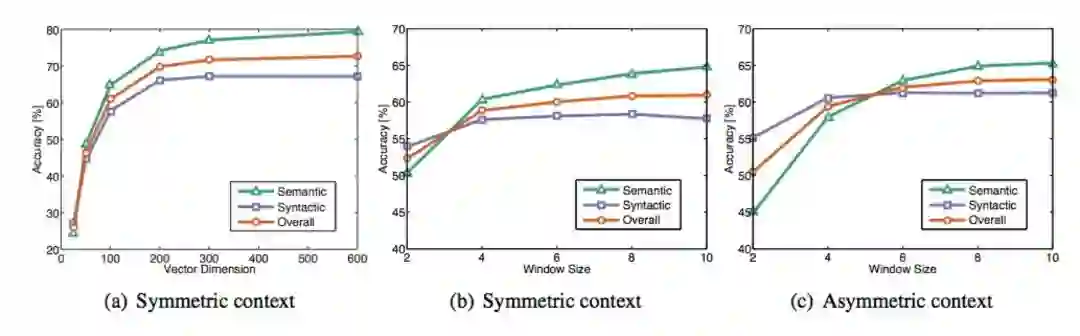
– 不对称的上下文(只对左边的单词)结果不太好
– 维度大约为300效果是最好的,但对于downstream的任务可能不同。
– 窗口大小为8的对称窗口对Glove向量效果挺好的。
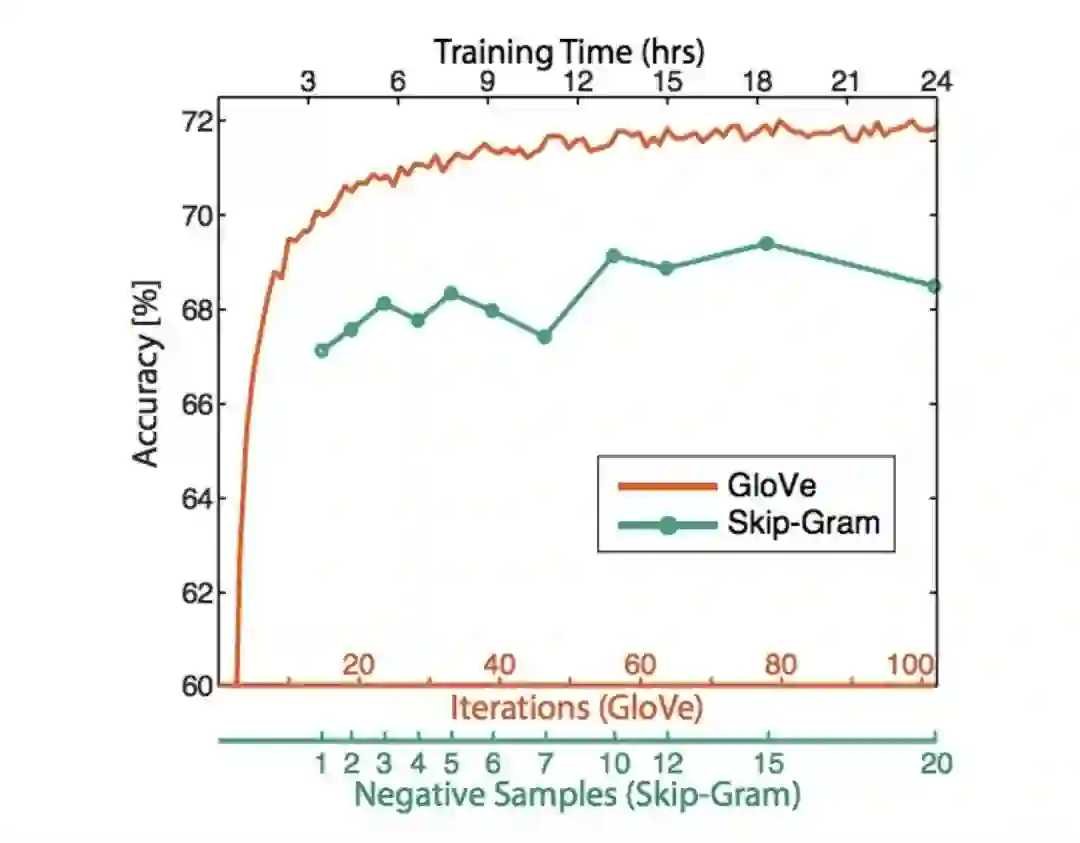
– 训练时间越长越好。如下图:
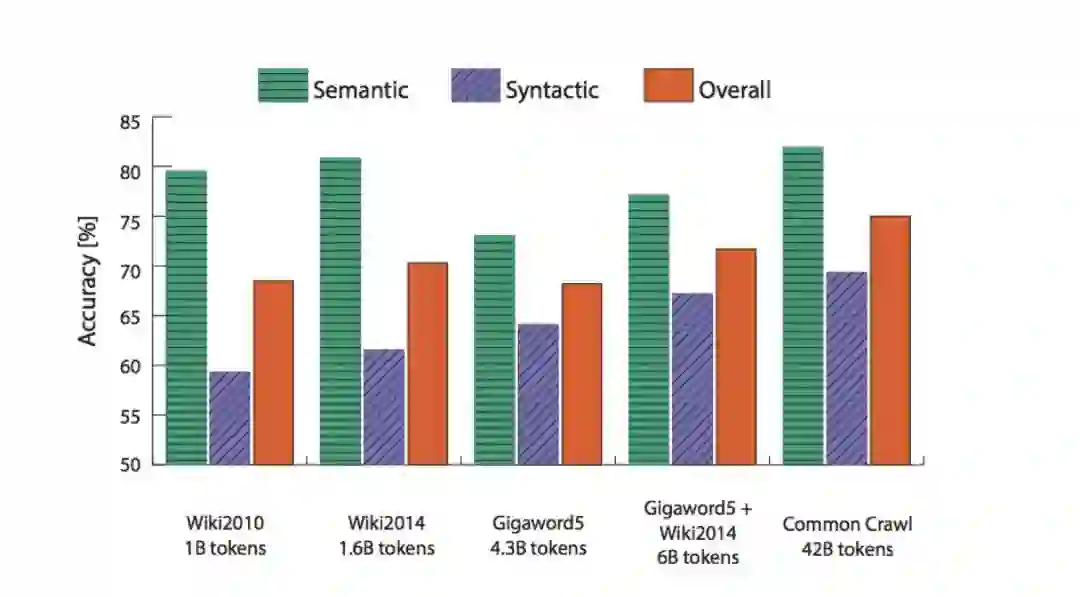
– 数据越多越好,维基百科比新闻文本更好!
3. 另一个数据集——WordSim353
• 词向量距离及其与人工标注的相关性。
• 示例数据集:Wordsim353:
http://www.cs.technion.ac.il/~gabr/resources/data/wordsim353/


• 相关性评估
– 词向量的距离及其与人工标注的相关性
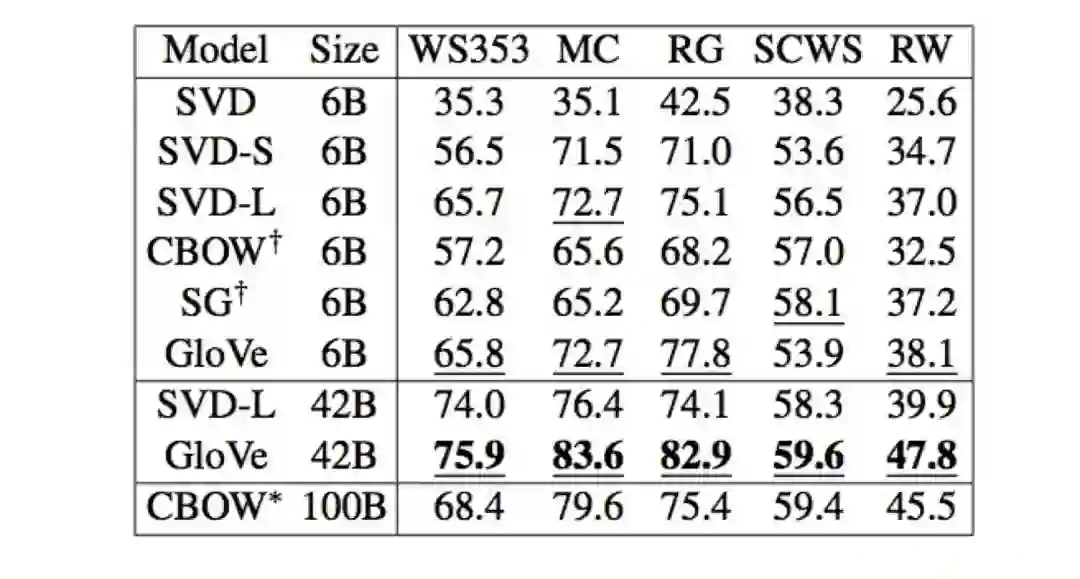
– Glove论文上的一些想法已经被证明也可以改进skipg-gram (SG) 。 (e.g. sum bothvectors)
4. 关于歧义(ambiguity)以及如何消除
• 你可能希望一个向量能捕获这样的两种信息(run=动词和名词),但是实际上向量被拉向两个不同的方向。
• 关于歧义的描述,参考论文:ImprovingWord Representations Via Global Context And Multiple Word Prototypes (Huang etal. 2012)
• 消歧的中心思想是通过对上下文的聚类分门别类地重新训练。参考论文:Improving Word Representations Via Global Context And Multiple WordPrototypes (Huang et al. 2012)

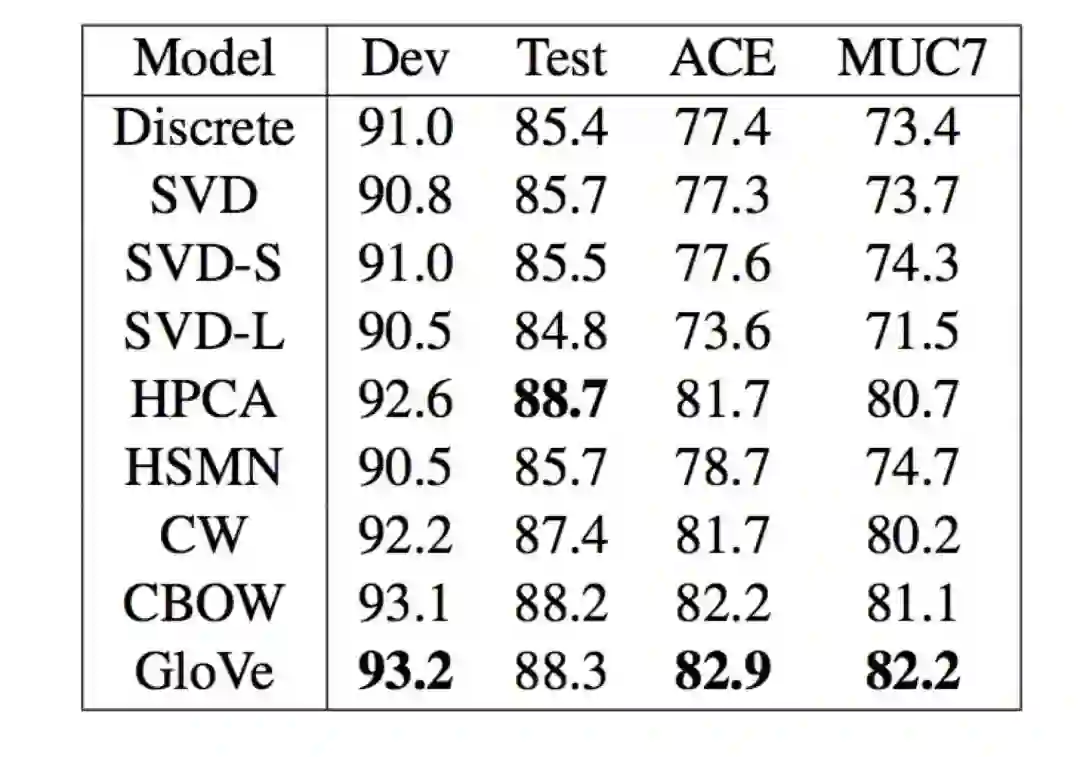
5. 外部词向量评估(Extrinsicword vector evaluation)
• 一个good词向量应用的实例:named entity recognition(命名实体识别),如下图所示:GloVe效果依然更好,但从数据上来看只好那么一点点。
从下节课开始我们将讲述如何在神经网络模型中使用词向量!
从下节课开始我们将讲述如何在神经网络模型中使用词向量!
建议阅读资料:
1. 论文:GloVe: Global Vectors for Word Representation
[https://nlp.stanford.edu/pubs/glove.pdf]
2. 论文:Improving Distributional Similarity with Lessons Learned from Word Embeddings
[http://www.aclweb.org/anthology/Q15-1016]
3. 论文:Evaluation methods for unsupervised word embeddings
[http://www.aclweb.org/anthology/D15-1036]
请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),
后台回复“NLPS” 就可以获取 2018年斯坦福CS224n课程PPT下载链接~
更多教程资料请访问:专知AI会员计划
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取

[点击上面图片加入会员]
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~
请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知



