编者按:自然语言处理的发展进化带来了新的热潮与研究问题。基于一系列领先的科研成果,微软亚洲研究院自然语言计算组将陆续推出一组文章,介绍机器推理(Machine Reasoning)在常识问答、事实检测、自然语言推理、视觉常识推理、视觉问答、文档级问答等任务上的最新方法和进展。上周我们介绍了机器推理系列的概览,本文是该系列的第一篇文章。
推理是自然语言处理领域非常重要且具有挑战性的任务,其目的是使用已有的知识和推断技术对未见过的输入信息作出判断(generate outputs to unseen inputs by manipulating existing knowledge with inference techniques)[1]。在本文中,我们以常识问答为应用,介绍机器推理在常识问答任务上的最新方法和进展。
当前,深度学习方法在诸多智能问答任务中取得了非常出色的效果[2],但是已有的方法通常仅对输入和输出之间的语义关系进行建模,并在分布相同或类似的测试数据上测试。一旦测试数据来自不同分布或所涉及的知识和领域超出训练数据的范畴[3],大多数问答系统的性能都会有大幅度的下降。这一定程度上反映了当前深度学习算法的成功其实是模式匹配能力的提升,而正确解答一个问题需要很多人类在回答问题时所使用的背景知识(如事实类知识、常识类知识等),有效地利用这些知识能够帮助模型进行推理,以及更好地应对未见过的问题(即举一反三)。
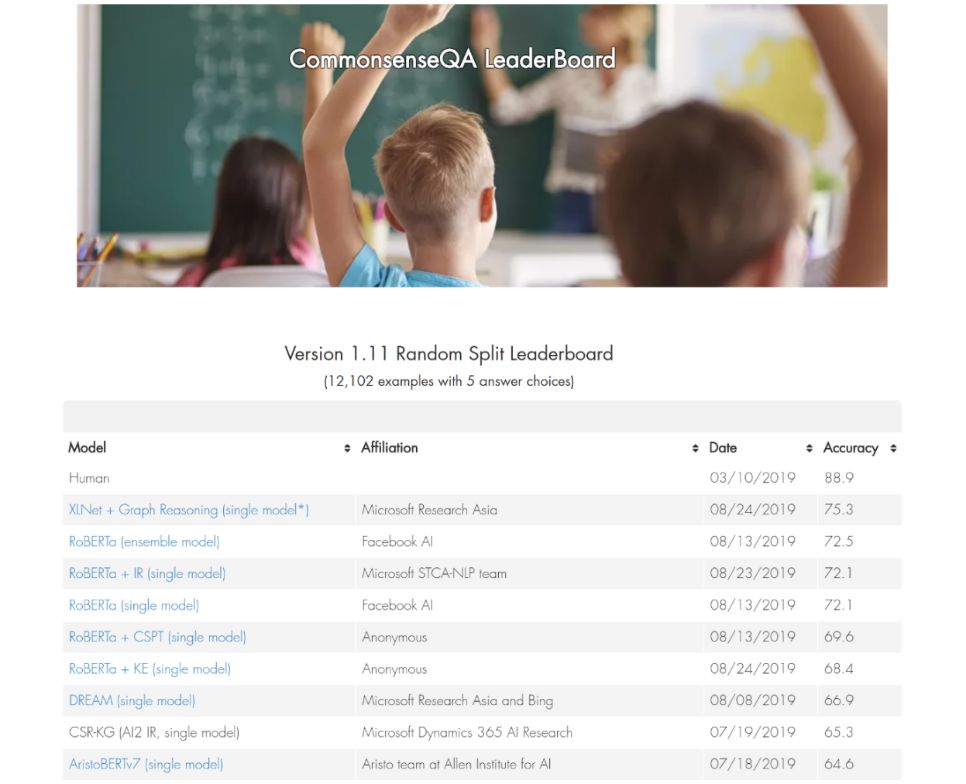
在本文中,我们介绍在常识问答任务中如何自动获取与样本相关的知识,获得输入和知识的语义表示,以及推断得出最后的结果。我们基于机器推理的方法(XLNet + Graph Reasoning)在以色列特拉维夫大学常识问答任务 CommonsenseQA 上取得了目前 state-of-the-art 的结果。
CommonsenseQA 任务排名结果:https://www.tau-nlp.org/csqa-leaderboard
图1:我们的方法(XLNet+Graph Reasoning)目前在以色列特拉维夫大学常识问答任务 CommonsenseQA 上排名第一
我们在 CommonsenseQA 数据集上开展研究,任务是给定1个自然语言问题和5个候选答案作为输入,要求输出正确的答案。
与已有的数据集不同,该数据集在构建过程中已经保证每个候选答案都和问题中的词汇具有语义关联,因此正确回答该数据集中的问题需要有效利用问题和候选答案的相关背景知识,更多关于数据集的细节请参考论文[4]。
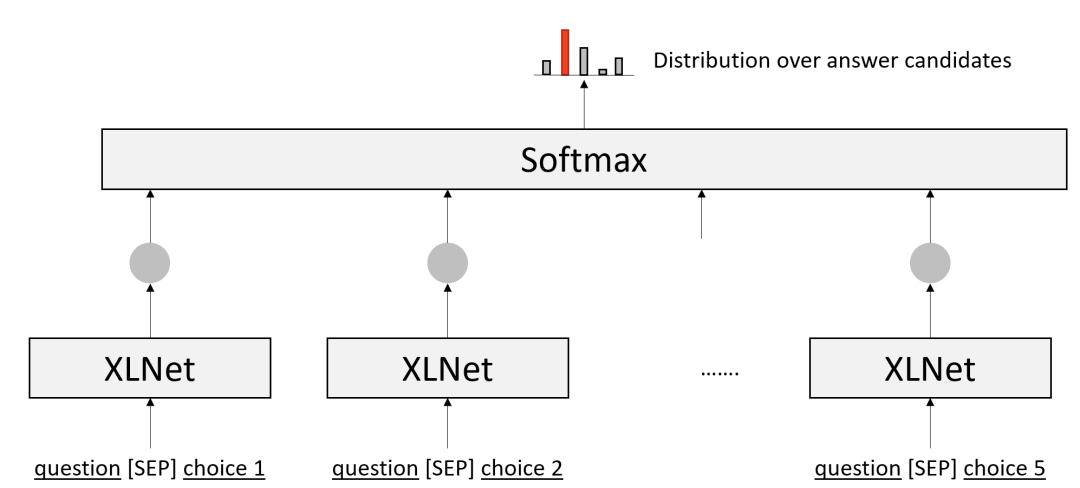
我们在预训练模型(如BERT、XLNet)的基础上构建了一个基线算法,如图2所示。
首先利用 XLNet[5] 预训练模型计算问题和每个候选答案的语义相关程度,然后使用 softmax 层计算各个候选答案正确的概率。
虽然该基线系利用了预训练模型中蕴含的知识[5],经验上也很有效,但预训练模型中的知识既不可控制也不可解释。
同时,正确回答一个问题所需的知识可能来自多个信息源,并同时包括结构化和非结构化的知识、事实类和常识类的知识。
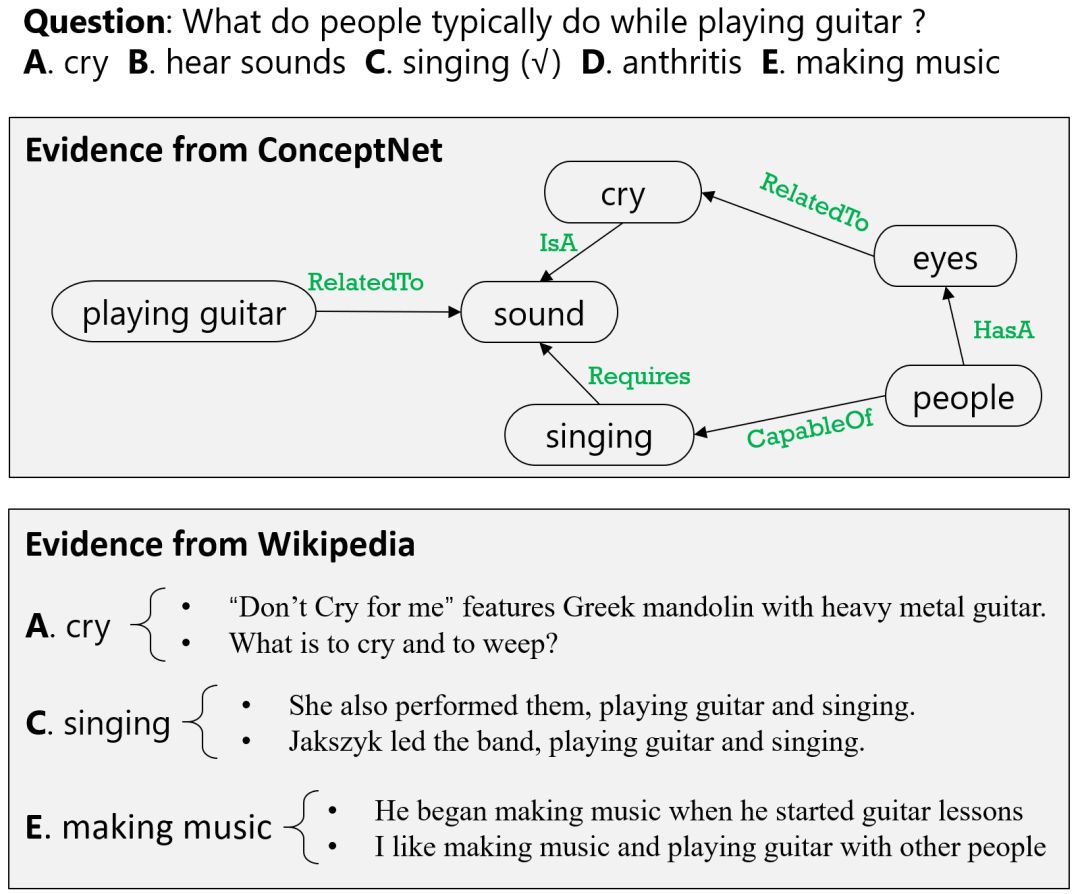
以图3为例,利用来自 ConceptNet 的结构化常识知识可以帮助我们选择 A 和 C;
利用来自 Wikipedia 的非结构化文本信息可以帮助我们选择 C 和 E。
因此,我们希望即保留预训练模型的优势,同时从多个信息源中自动地获取与输入相关的知识,最终通过推断模型获得正确的答案。
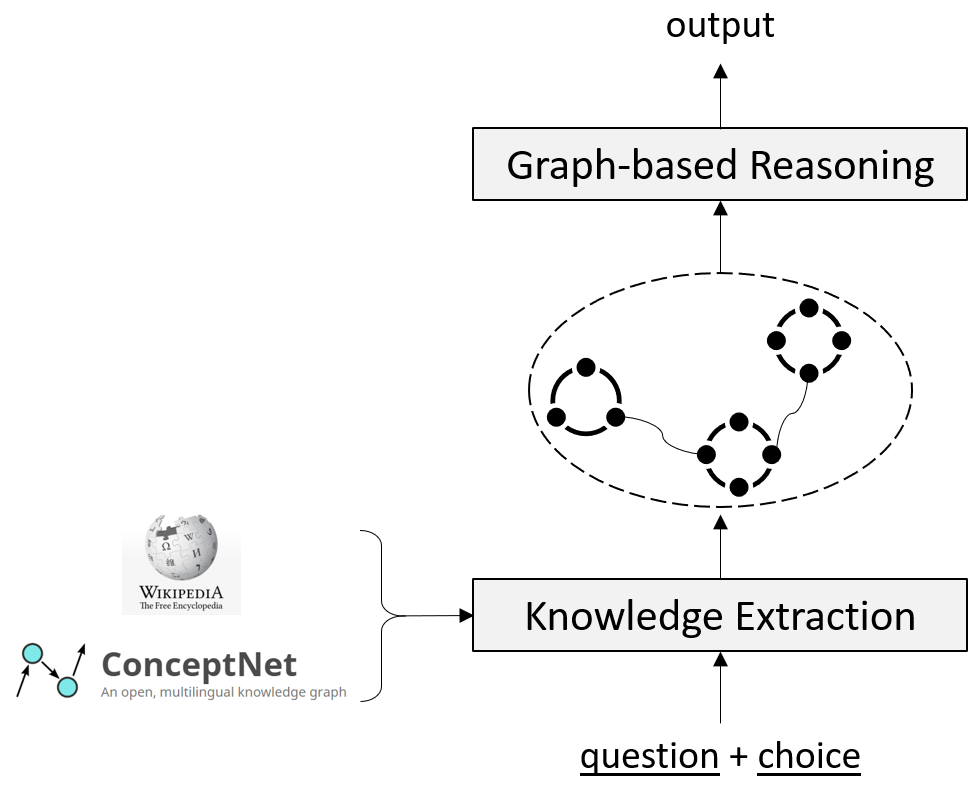
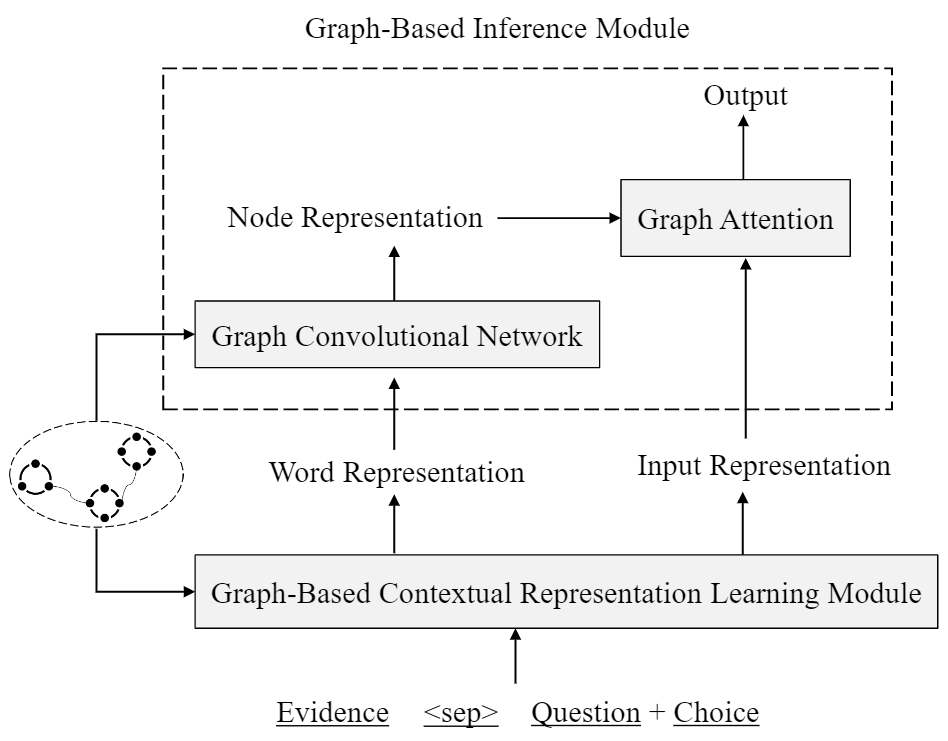
如图4所示,我们的推理模型包括两个模块,即知识抽取模块和基于图的推理模块。
在知识抽取模块,我们从多个数据源获取与输入(问题和每个候选答案的组合)相关的知识。
具体地,我们同时利用结构化常识知识库 ConceptNet 和 Wikipedia 文档。
在 ConceptNet 中,我们获取从问题词语到候选答案词语的路径,例如问题中包含了词语“playing guitar”,通过“playing guitar”-RelatedTo-“sound”-IsA-“cry”我们即获得了一条问题到选项“cry”的路径。
在 Wikipedia 中,我们首先利用 Elasticsearch 搭建了句子级的检索系统,随后把问题和候选答案当做查询去系统中检索相关的句子。
从 ConceptNet 中获取的知识天然具有结构信息,可以把词语看做节点,把关系看做连接词语的边。
Wikipedia 中的抽取结果虽然为句子,但多个证据之间存在着内在的联系,为了获取句子内部和句间的结构化知识,我们使用语义角色标注(SRL)对每个句子进行分析,并对多个句子的抽取结果建立边的连接(如使用 argument 的词语共现程度)。
由此,我们从每个知识源中获得了结构化的与输入相关的知识。
在获得了与当前输入相关的知识之后,我们提出了如图5所示的基于图的推理模型。
具体地,我们首先利用图的结构信息学习得到包含更丰富语义结构的词向量表示,我们的实现方式是在 XLNet 的基础上利用图的结构重新定义词语之间的距离。
直觉上,在图结构中语义相近的词语的距离较近。
在获得了每个词语的表示(contextual word representation)后,我们进一步利用图的结构信息在图结构的层面做推断。
图中每个节点的表示不只取决于该节点内词语的表示,同时也受图中邻居节点表示的影响,因此我们使用了图卷积神经网络计算图的表示,并最终使用基于图表示的注意力机制进行信息整合。
从表1中可以看出,本文提出的两个基于图的方法均在基线模型上有提高,两者融合会获得进一步的提升。
更多细节请参考我们的论文:Graph-based Reasoning over Heterogeneous External Knowledge for Commonsense Question Answering。
论文地址:
https://arxiv.org/abs/1909.05311(点击“阅读原文”即可访问)
本文介绍了基于机器推理的方法在常识问答任务中的应用,我们同时从结构化和非结构化数据源中抽取知识,并创新地提出了融合图信息的词向量学习方法和基于图的推断方法,该方法在以色列特拉维夫大学常识问答任务 CommonsenseQA 上取得了 state-of-the-art 的结果。
下期预告
:
机器推理系列文章的下一期将介绍机器推理在事实检测任务中的应用。
敬请期待机器推理方法在更多推理任务上的应用!
[1] Ming Zhou, Nan Duan, Shujie Liu, Heung-Yeung Shum. Progress in Neural NLP: Modeling, Learning and Reasoning. Accepted by Engineering, 2019.
[2] 段楠,周明. 《智能问答》. 高等教育出版社,2018.
[3] Robin Jia, Percy Liang. Adversarial examples for evaluating reading comprehension systems. Empirical Methods in Natural Language Processing (EMNLP), 2017.
[4] Talmor, A.; Herzig, J.; Lourie, N.; and Berant, J. 2019. Commonsenseqa: A question answering challenge targeting commonsense knowledge. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics, 4149–4158.
[5] Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le. XLNet: Generalized Autoregressive Pretraining for Language Understanding. Arxiv: 1906.08237
[6] Fabio Petroni, Tim Rocktaschel, Patrick Lewis, Anton Bakhtin, YuxiangWu, Alexander H. Miller, Sebastian Riedel. Language Models as Knowledge Bases? Arxiv:1909.01066