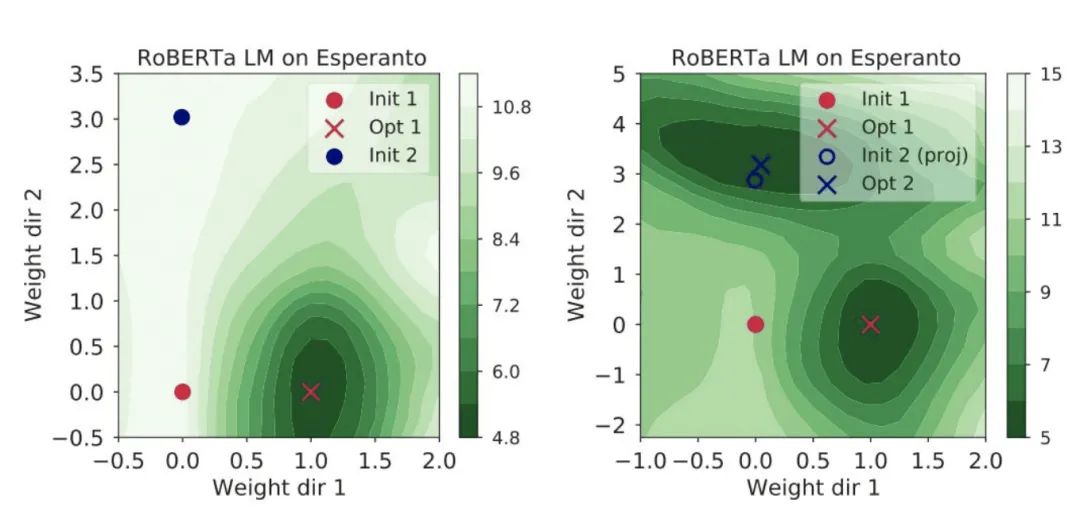
黄线是训练时候跟着梯度在损失面上走出来的损失曲线,蓝线和红线是从不同的初始点到最终模型拉一根直线投射到损失面上的损失曲线。可以看到,这条损失曲线是单调递减的。这篇文章 Analyzing Monotonic Linear Interpolation in Neural Network Loss Landscapes (https://arxiv.org/abs/2104.11044) 管这个特性叫“单调线性插值”。文章发现从不同的初始值可以走到同一个模型,殊路同归,而且模型符合单调线性插值,如左图。而这个情况文章 Linear Mode Connectivity and the Lottery Ticket Hypothesis (https://arxiv.org/abs/1912.05671) 也说了,随机初始化位置不同,模型经常就会掉到同一个局部极小值,而这个趋势在训练很早期就已经确定了。有时候不同的初始值会走到不同的模型,这种情况如果你从init1到opt2拉一根直线去投射,就不是单调的了,也很好理解,因为要翻过一个小山坡,这个情况是右图:
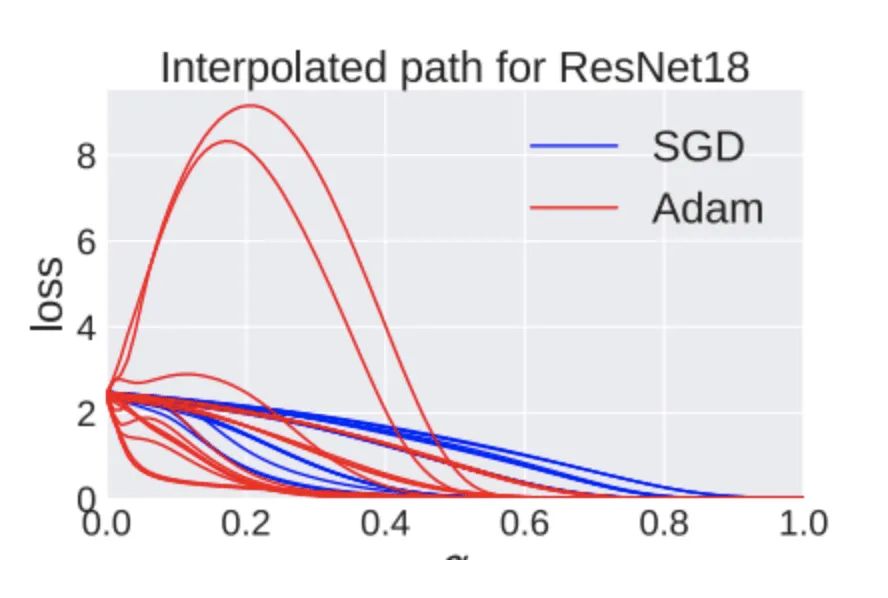
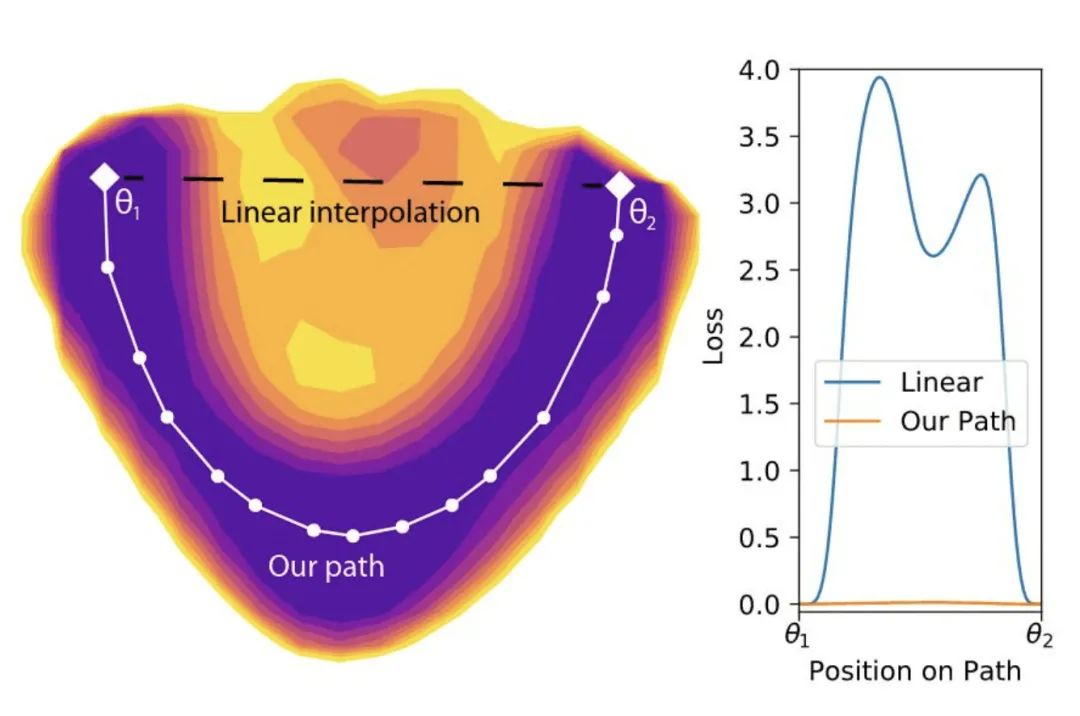
这很好理解,但这却不是真相的全部。文章 Essentially No Barriers in Neural Network Energy Landscape * (https://arxiv.org/abs/1803.00885)* 发现,这些极小值之间是可以通过一段一段的直线连接起来的:
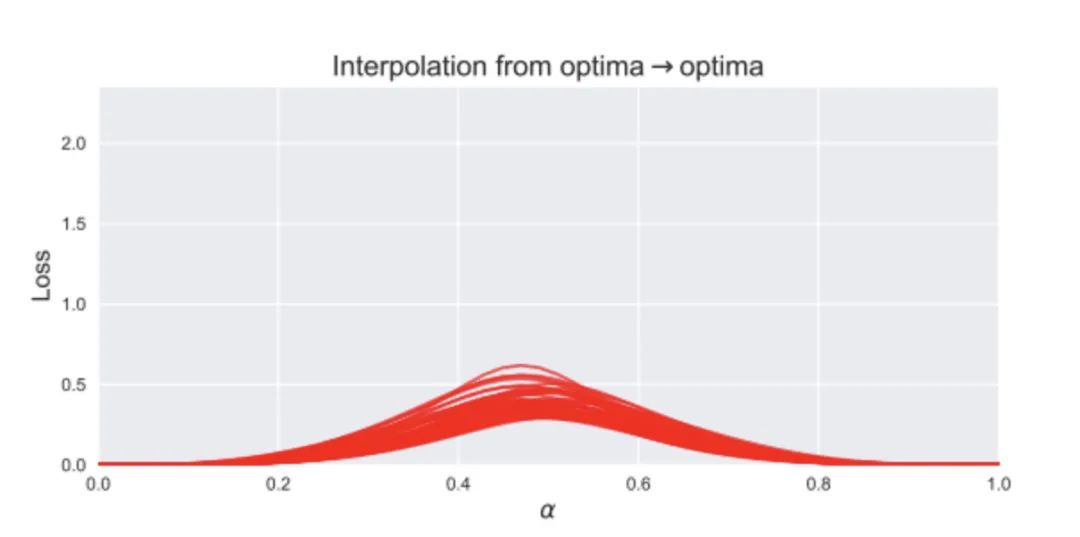
如果你直接走直线,就是越过山坡,会跌宕起伏,但如果使用文章中的优化方法,绕着走,肯定可以到达另一个极小值。也就是说,局部极小值之间都可以通过线段连接起来,而且一路上损失都很低(上图右边那条黄线,沿着山谷走,损失一直很低,一直都保持极小值状态)。而文章 On Connected Sublevel Sets in Deep Learning (https://arxiv.org/abs/1901.07417) 则证明,如果使用分段线性激活函数,比如ReLu,那么这个神经网络模型的所有局部极小值其实都是连在一块儿的,他们其实都属于同一个全局最小值。文章 Landscape Connectivity and Dropout Stability of SGD Solutions for Over-parameterized Neural Networks (https://arxiv.org/abs/1912.10095) 告诉我们,神经网络参数量越大,局部极小值之间的连接性越强。
神经网络损失面的全貌
那么综合以上各种论文的结论,基本可以描绘出神经网络损失面的全貌,应该长这样:
极小值都处于同一个高度,属于同一个全局最小值,而且互相之间是连在一起的。那么很容易想到了,如果你往这个沙盘随机扔弹子,是不是更容易掉到那种特别宽的flat minima?没错,文章 The large learning rate phase of deep learning:the catapult mechanism (https://arxiv.org/abs/2003.02218) 发现,使用大的学习率更容易掉到平坦的极小值(flat wide minima),也就是说,学习率一大,相当于在这些山之间乱跳,当然更容易掉到flat wide minima咯。大胆猜测,根据Lottery Ticket假设那篇论文描述的现象,这里面每一个小山都是一个sub-network另外还有很多研究表现resnet和mish激活函数可以让损失面更平滑,而Relu会让极小值变得很尖很崎岖。

 回答一
回答一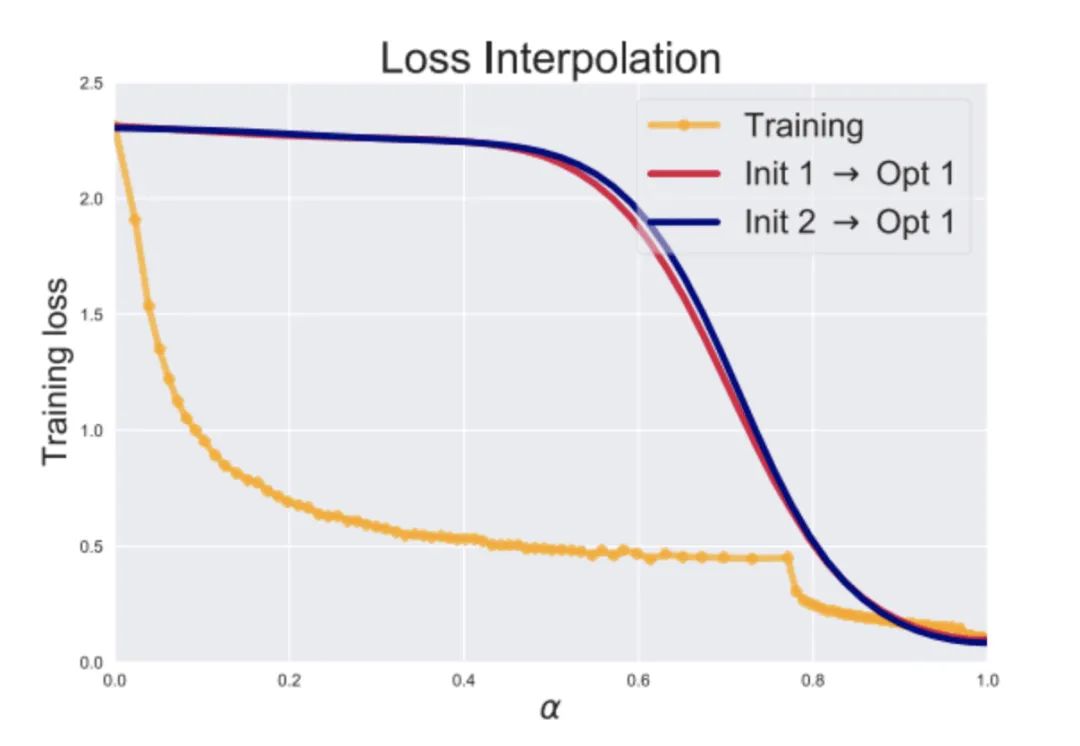


 后台回复关键词【
后台回复关键词【



