机器学习如何分布式?看CMU这份「分布式机器学习原理与策略」AAAI2021教程,附221页ppt
通过可组合和自动化的并行ML系统简化分布式ML

ML规模化常常被低估。在多台机器上训练一个ML模型(最初是针对单个CPU/GPU实现的)到底需要什么?一些痛点是: (1) 需要编写许多新代码行来将代码转换为分布式版本; (2)需要大量调整代码以满足系统/统计性能,这是模型开发的附加过程; (3)决定使用哪些/多少硬件资源来训练和部署模型; (4) 从组织的角度出发,在许多用户和作业之间实现资源共享自动化,以满足用户的需求,同时使资源利用率最大化,成本最小化。
在本教程中,我们将介绍自动化分布式ML基础设施的改进技术。本教程涵盖了对ML并行化至关重要的三个领域: (1)对并行ML构建块进行编组和标准化; (2) ML并行表示和软件框架; (3)自动ML并行化的算法和系统,以及在共享集群上ML作业的资源分配。通过揭示ML程序的独特特征,并通过剖析成功案例来揭示如何利用它们,我们为ML研究人员和实践者提供了进一步塑造和发展SysML领域的机会。
听众应该熟悉ML和DL的基础知识。了解TensorFlow、PyTorch和分布式ML技术也有帮助,但不是必需的。
https://sites.google.com/view/aaai-2021-tutorial-ah9/home
讲者:

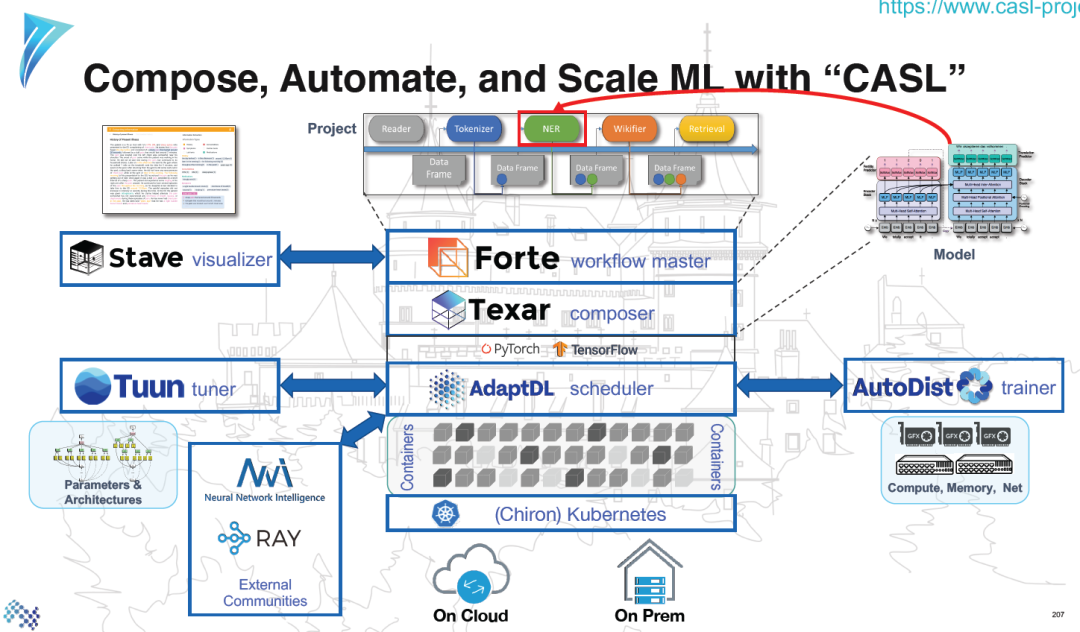
教程预览
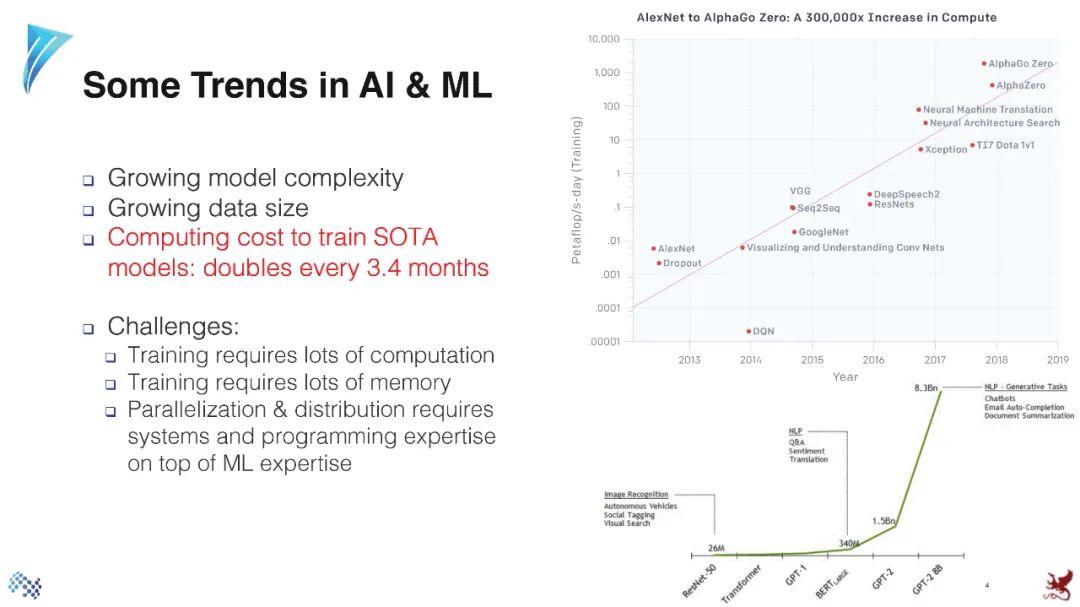

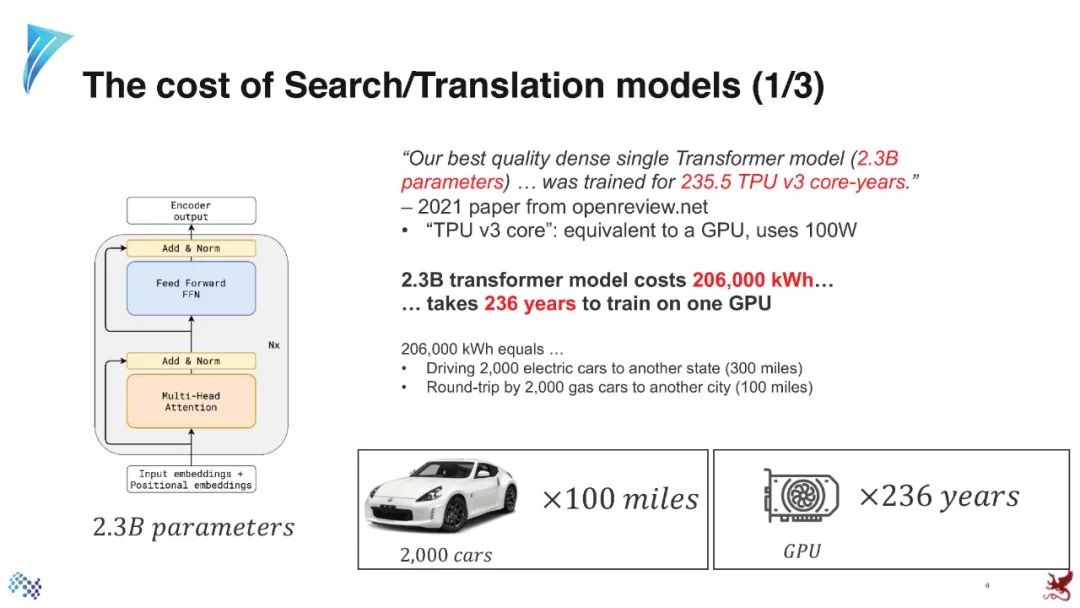
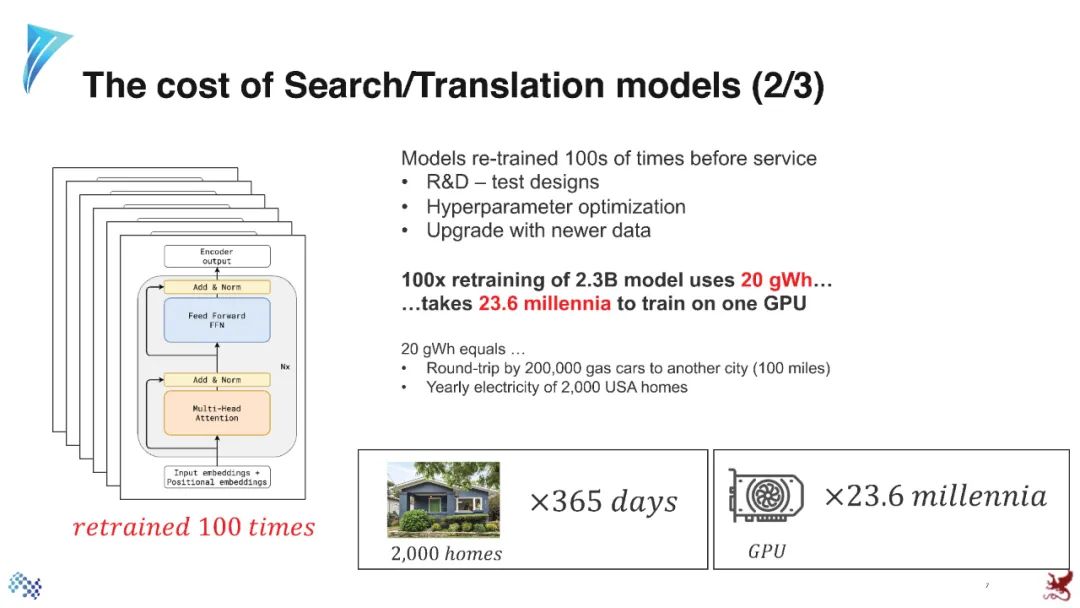





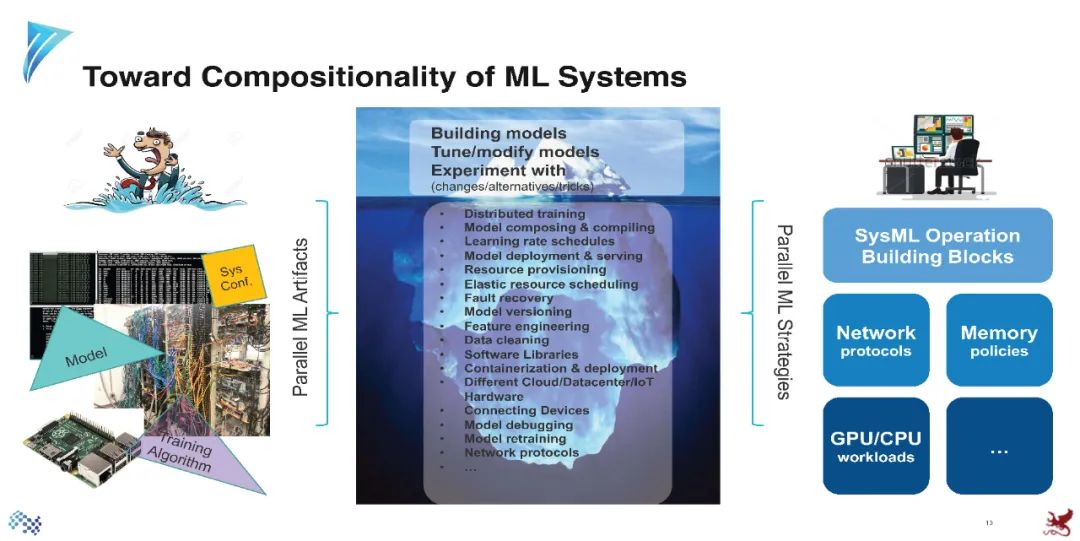





参考资料:
【CMU-zhanghao博士论文】机器学习并行化:自适应、可组合与自动化,附229页pdf与答辩视频
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“DML221” 可以获取《机器学习如何分布式?看CMU这份「分布式机器学习原理与策略」AAAI2021教程,附221页ppt》专知下载链接索引



登录查看更多
相关内容
Arxiv
0+阅读 · 2021年5月3日
Arxiv
9+阅读 · 2018年1月27日


相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2021年5月3日
Arxiv
9+阅读 · 2018年1月27日