炼丹神器来了! 模型结构、训练日志、特征提取都能可视化,调参不慌了!
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

开发者在炼丹的过程中会不会遇到这些问题呢?比如说深度学习模型训练过程中盯 Log 盯得头晕眼花?复杂模型结构全靠脑补?网络各层效果无法评估?模型评估指标难以综合权衡?想必各位「炼丹师」、「调参侠」都中过招吧?莫慌,飞桨给大家「送解药」来了!

看到这里,有些小伙伴可能已经大概知道 VisualDL 是什么了,不知道的同学请继续往下看,反正花花绿绿的,至少比 log 看着养眼多了!
add_scalar(tag, value, step, walltime=None)add_image(tag, img, step, walltime=None)add_audio(tag, audio_array, step, sample_rate)模型文件拖拽上传

在命令行加入参数 --model 并指定模型文件路径(非文件夹路径),运行命令后即可启动:
visualdl --model ./log/model --port 8080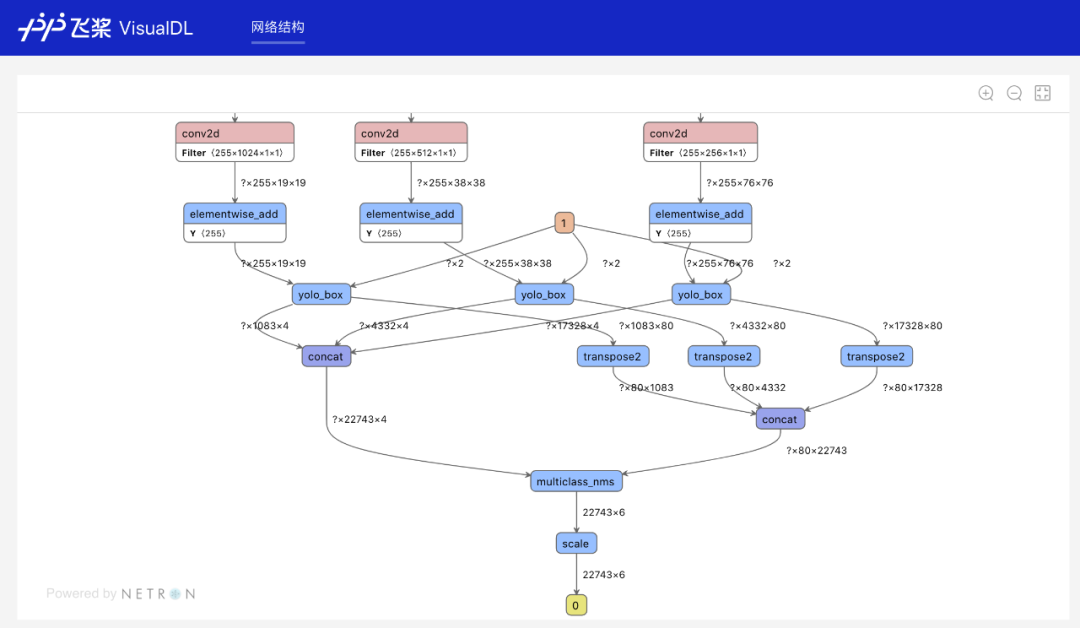
add_histogram(tag, values, step, walltime=None, buckets=10)add_pr_curve(tag, labels, predictions, step=None, num_thresholds=10)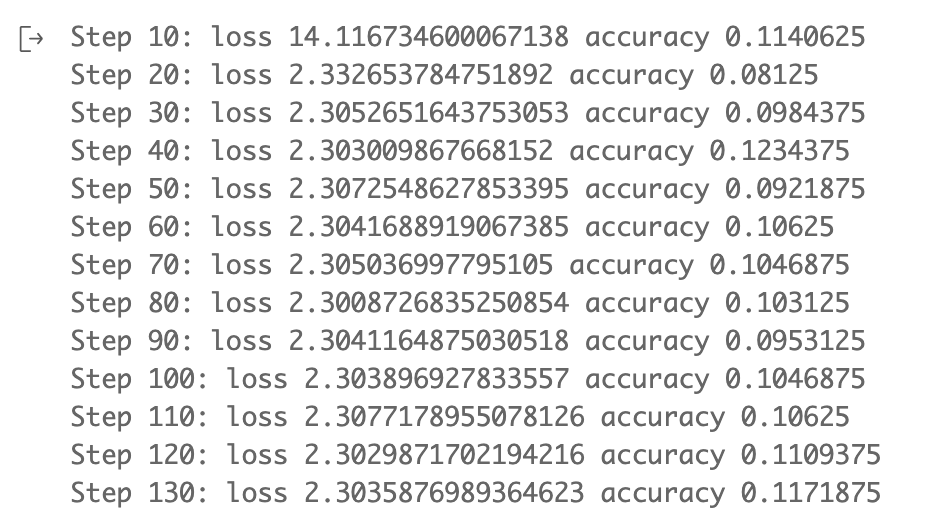
#使用VisualDL的第一步是在训练脚本中添加如下代码创建日志文件,用于记录训练中产生的数据。
from visualdl import LogWriter
log_writer = LogWriter("./paddle_lenet_log")
# 使用标量(Scalar)记录Loss、Accuracy参数,用于观察其变化趋势
writer.add_scalar(tag="train/loss", step=step, value=cost)
writer.add_scalar(tag="train/acc", step=step, value=accuracy)
# 使用数据样本分析功能记录每批次第一张数据,用于查看图像数据
img = np.reshape(batch[0][0], [28, 28, 1]) * 255
writer.add_image(tag="train/input", step=step, img=img)
# 使用直方图功能记录所有参数,用于查看weight、bias在训练步数中的分布变化
for param in params:
values = fluid.global_scope().find_var(param).get_tensor()
writer.add_histogram(tag='train/{}'.format(param), step=step, values=values)
# 记录PR曲线查看不同阈值下的精度和召回率
labels = np.array(batch)[:, 1]
for i in range(10):
label_i = np.array(labels == i, dtype='int32')
prediction_i = pred[:, i]
writer.add_pr_curve(tag='train/class_{}_pr_curve'.format(i),
labels=label_i,
predictions=prediction_i,
step=step,
num_thresholds=20)
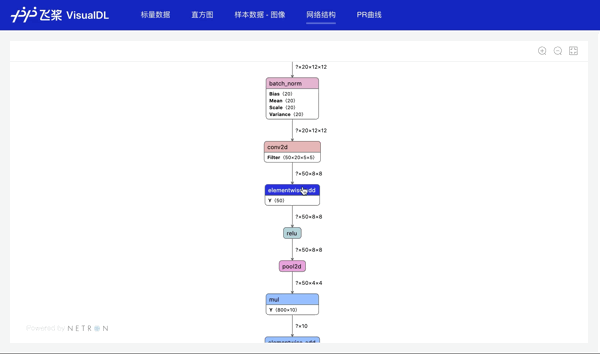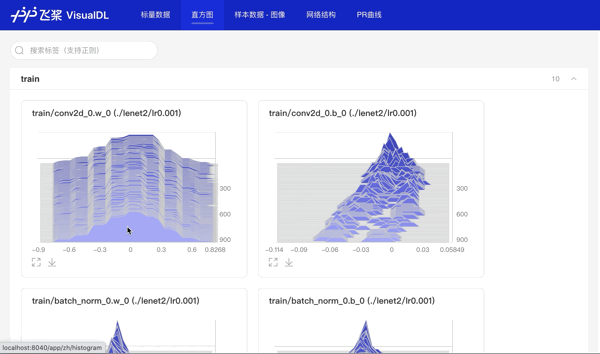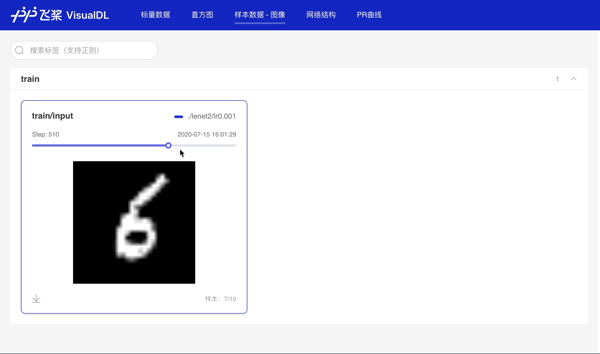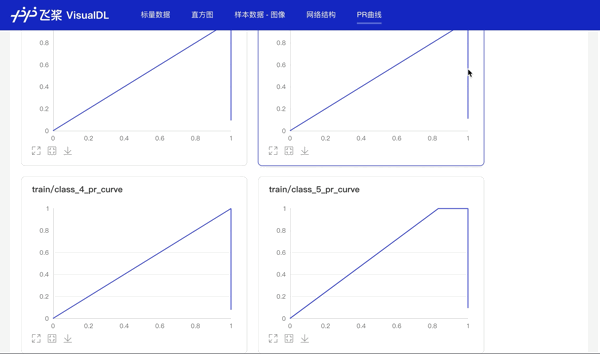
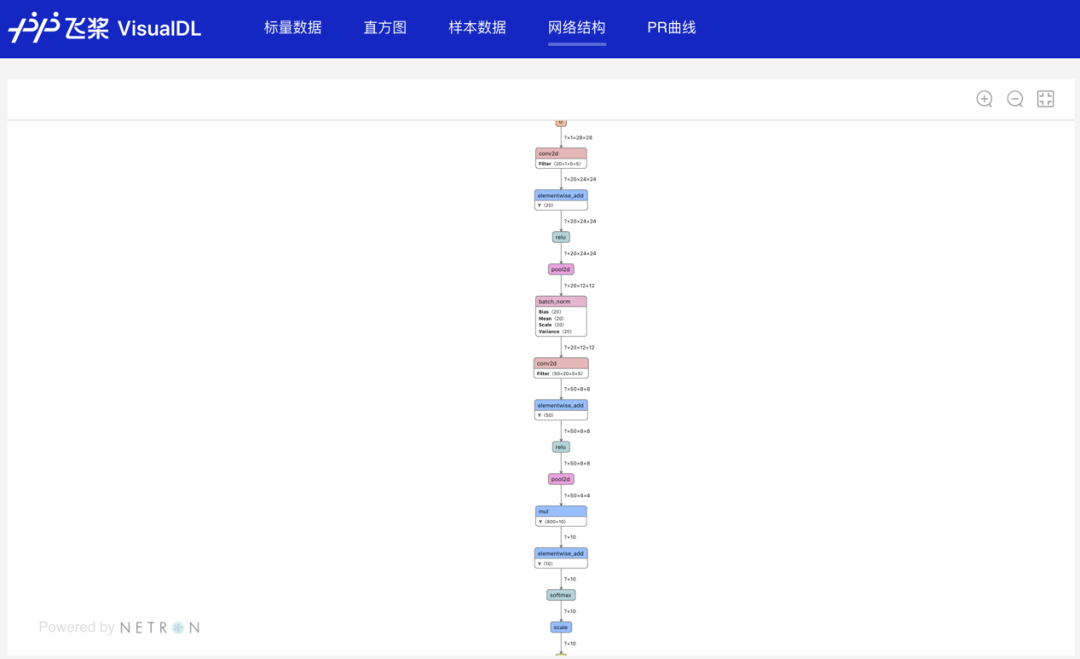
# 使用save_inference_model保存模型结构至“./model”目录,便于训练后使用模型结构(Graph)功能查看模型网络结构
fluid.io.save_inference_model(dirname='./model', feeded_var_names=['img'],target_vars=[predictions], executor=exe)visualdl--logdir ./paddle_lenet_log --port 8080writer.add_scalar(tag="train/loss", step=step, value=cost)
writer.add_scalar(tag="train/acc", step=step, value=accuracy)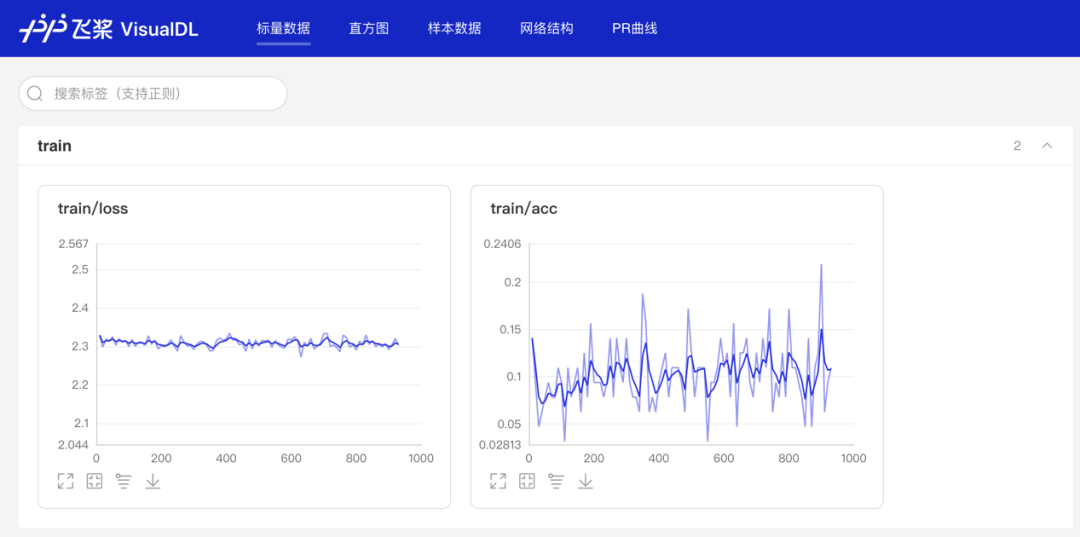
# 使用数据样本分析功能记录每批次第一张数据,用于查看图像数据
img = np.reshape(batch[0][0], [28, 28, 1]) * 255
writer.add_image(tag="train/input", step=step, img=img)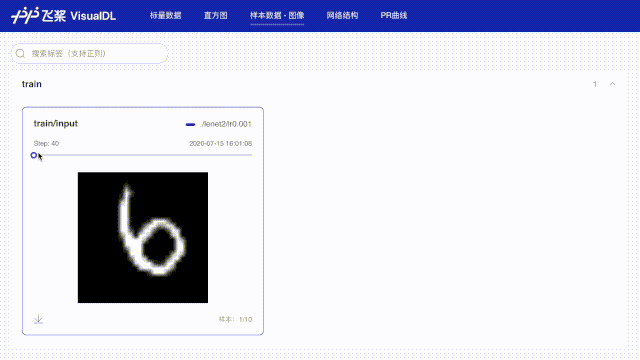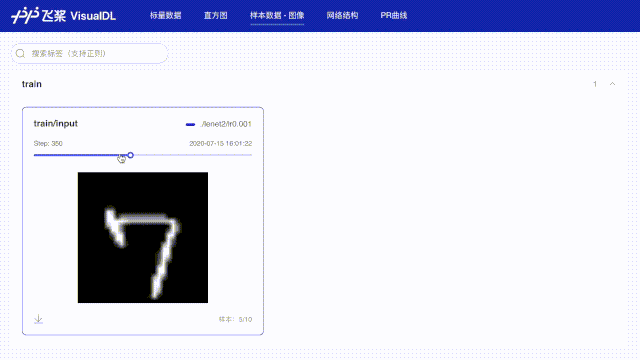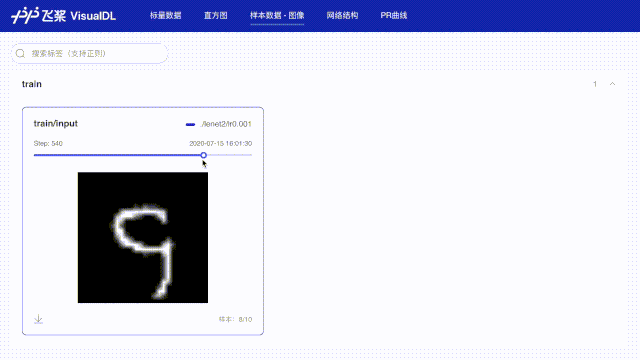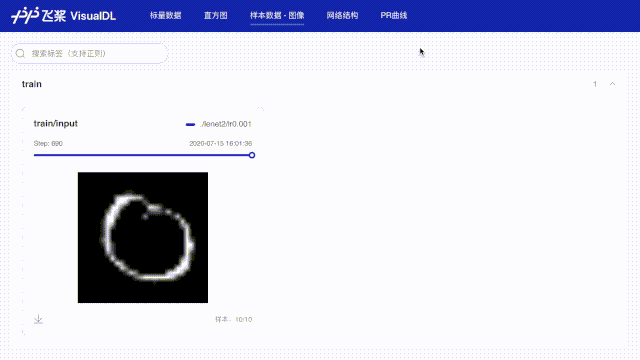
for param in params:
values = fluid.global_scope().find_var(param).get_tensor()
writer.add_histogram(tag='train/{}'.format(param), step=step,
values=values)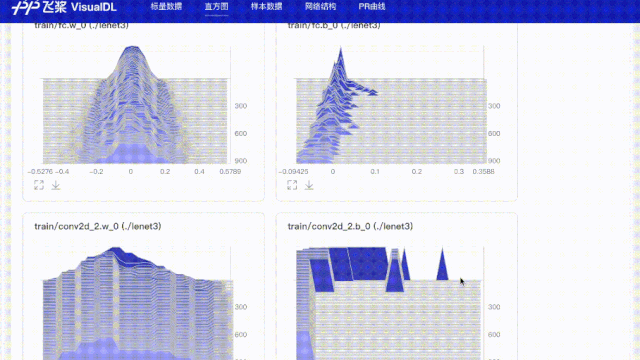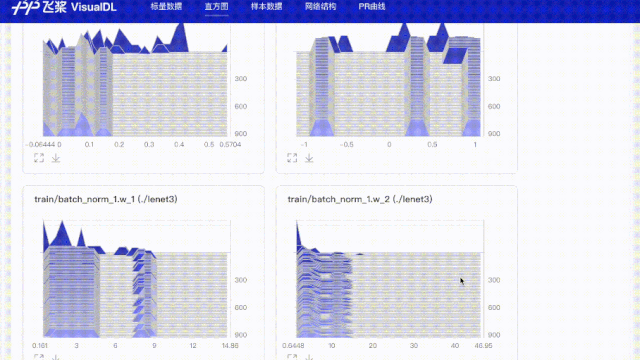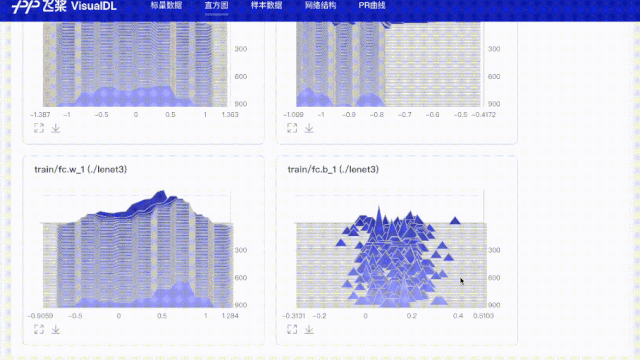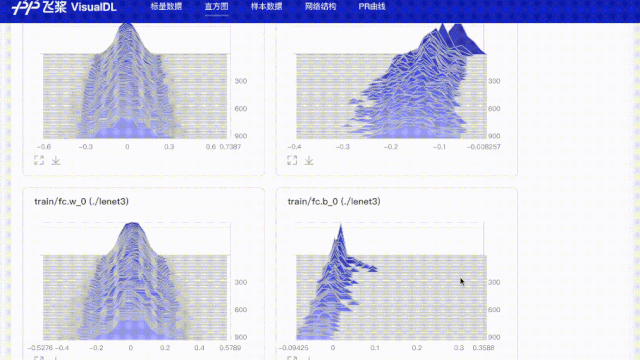
#创建日志文件,储存当lr=0.001时训练结果
log_writer = LogWriter("paddle_lenet_log/lr0.001")
#创建日志文件,储存当lr=0.03时训练结果
log_writer = LogWriter("paddle_lenet_log/lr0.03")
#创建日志文件,储存当lr=0.05时训练结果
log_writer = LogWriter("paddle_lenet_log/lr0.05")
#创建日志文件,储存当lr=0.08时训练结果
log_writer = LogWriter("paddle_lenet_log/lr0.08")
#创建日志文件,储存当lr=0.1时训练结果
log_writer = LogWriter("paddle_lenet_log/lr0.1")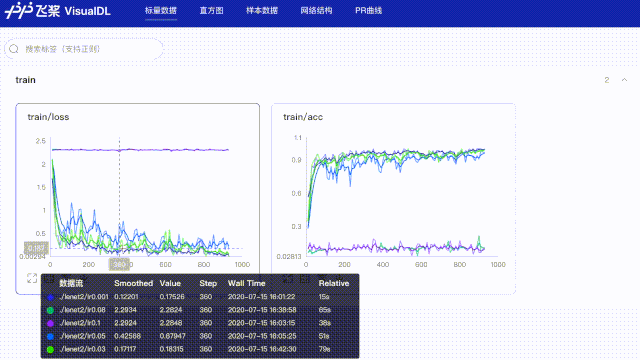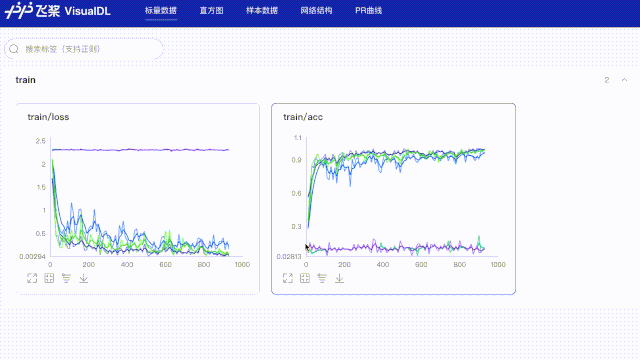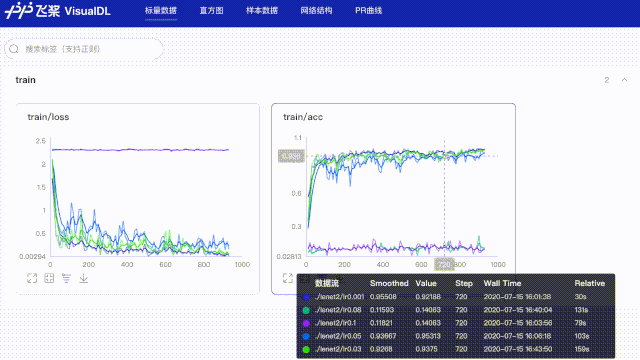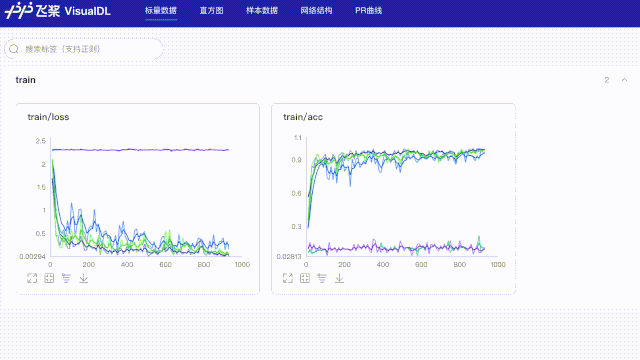
labels = np.array(batch)[:, 1]
for i in range(10):
label_i = np.array(labels == i, dtype='int32')
prediction_i = pred[:, i]
writer.add_pr_curve(tag='train/class_{}_pr_curve'.format(i),
labels=label_i,
predictions=prediction_i,
step=step,
num_thresholds=20)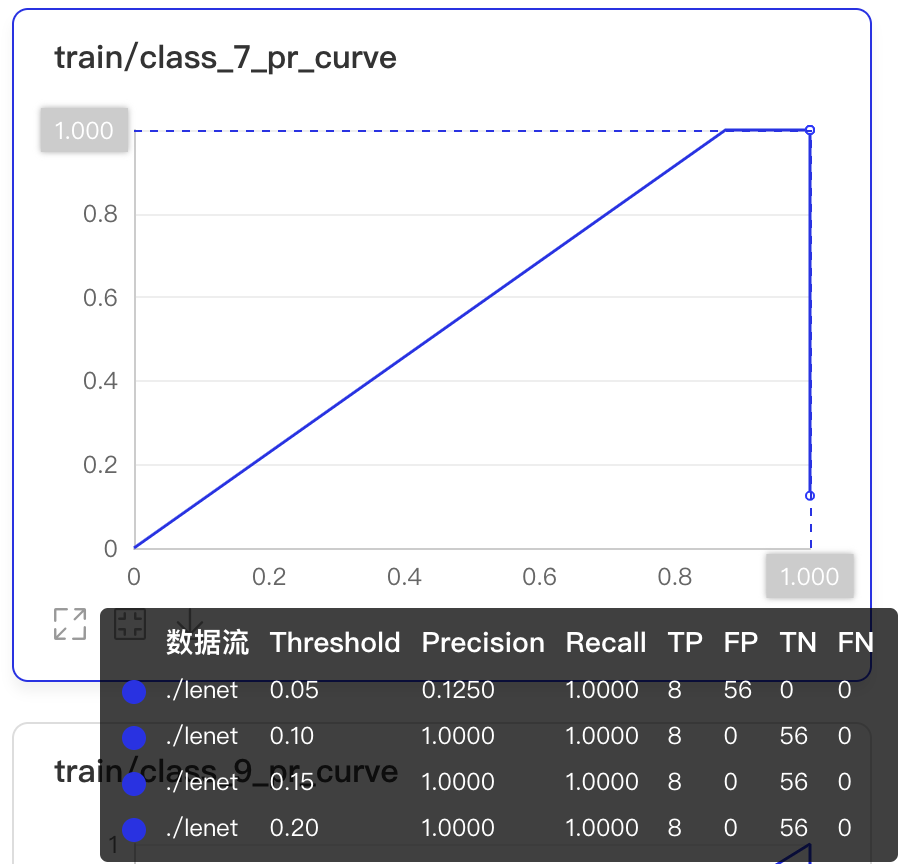
https://aistudio.baidu.com/aistudio/projectdetail/622772
https://aistudio.baidu.com/aistudio/projectdetail/502834
高兼容性:全面支持飞桨、ONNX、Caffe 等市面主流模型结构可视化,广泛支持各类用户实现可视化分析。
生态支持全面:与飞桨的多个套件、工具组件以及 AI 学习和实训社区 AI Studio 全面打通,为开发者们在飞桨生态系统中提供最佳使用体验。
飞桨官网地址:https://www.paddlepaddle.org.cn
VisualDL 官网地址:https://www.paddlepaddle.org.cn/paddle/visualdl
GitHub:https://github.com/PaddlePaddle/VisualDL
Gitee: https://gitee.com/paddlepaddle/VisualDL
GitHub: https://github.com/PaddlePaddle/Paddle
Gitee: https://gitee.com/paddlepaddle/Paddle
整理不易,请给CVer点赞和在看!




