【专栏】觉得 GAN 不好理解?GANLab 将GAN的训练过程可视化给你看
来源:专知
【导读】Generative Adversarial Network (GAN) 是当下最热门的研究领域之一。它主要包括了两个部分,即生成器 generator 与判别器 discriminator。生成器主要用来学习真实图像分布从而让自身生成的图像更加真实,以骗过判别器。判别器则需要对接收的图片进行真假判别。如果你对上述描述有些困惑, 没关系,Minsuk Kahng 等同学,近日在计算机视觉顶级期刊TVCG上,发布了一款新工具 GANLab,可以让你轻松理解 GAN 的训练过程。
论文
GAN Lab: Understanding Complex Deep Generative Models using Interactive Visual Experimentation
作者
Minsuk Kahng, Nikhil Thorat, Polo Chau, Fernanda Viégas, and Martin Wattenberg.
期刊
IEEE Transactions on Visualization and Computer Graphics
GANLab网址
https://poloclub.github.io/ganlab/
整理报道
huaiwen
首先让我们一睹为快,到底 GAN 是怎么训练的:
视频内的 GANLab 工具,分为几个功能区:
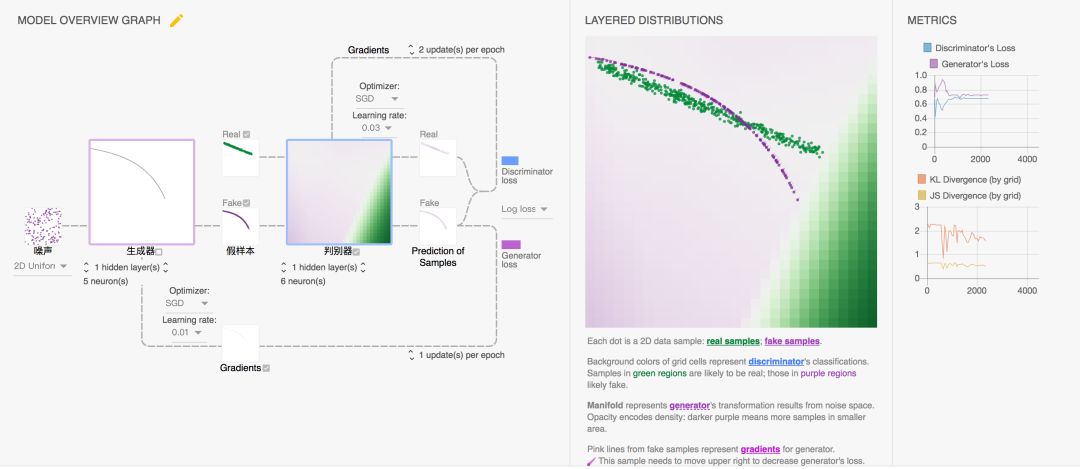
左侧的网络区, 包含了这个 GAN 的网络结构,和生成过程。中间的展示区,展示了,生成器生成的假样本(图中紫色),在不断拟合真样本(图中绿色)的过程, 同时,展示区,还通过背景颜色的不同,展示了判别器,对各个样本的判别结果:紫色背景,表示判别为假; 绿色背景表示判别为真。
在整个过程中,生成器努力地让生成的图像更加真实,而判别器则努力地去识别出图像的真假,这个过程相当于一个二人博弈,随着时间的推移,生成器和判别器在不断地进行对抗,最终两个网络达到了一个动态均衡:生成器生成的图像接近于真实图像分布,而判别器识别不出真假图像,对于给定图像的预测为真的概率基本接近 0.5(相当于随机猜测类别)。
但实际训练过程中,判别器和生成器之间的平衡很难掌控,比如,如下就是一个判别器学的过强的例子:

为此,我们可以细致的调节参数,GANLab 可以自由设置参数:
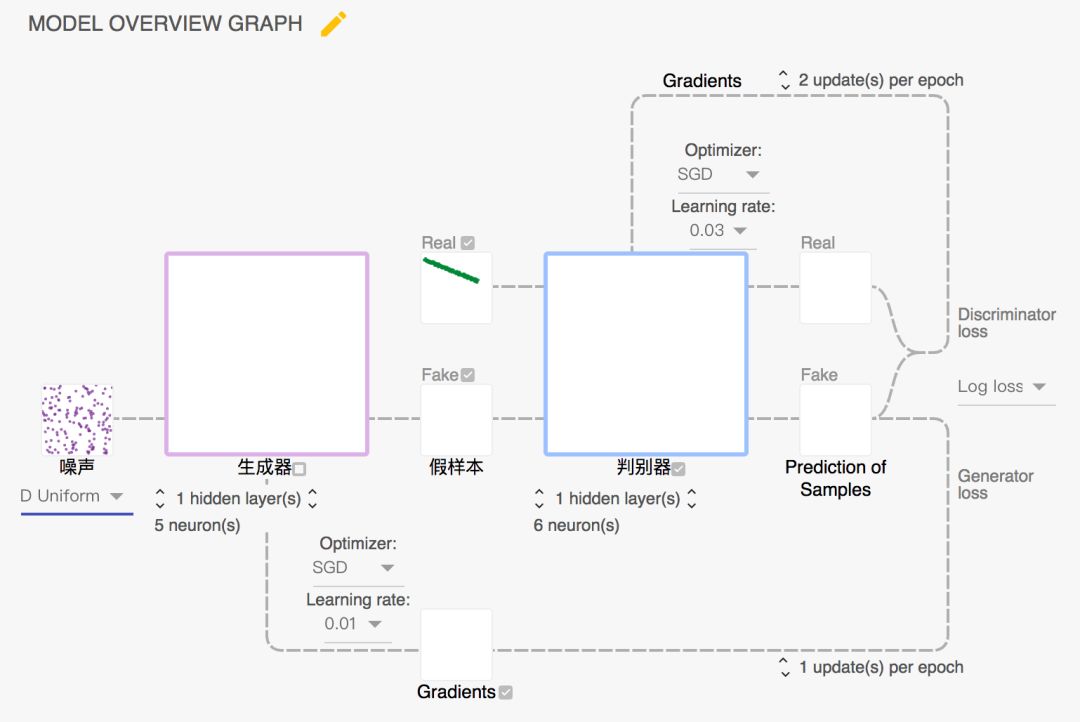
如图所示,我们可以调整噪声的生成方式, 生成器的隐层个数, 优化方法, 学习率,判别器隐层个数机器优化方法等等。
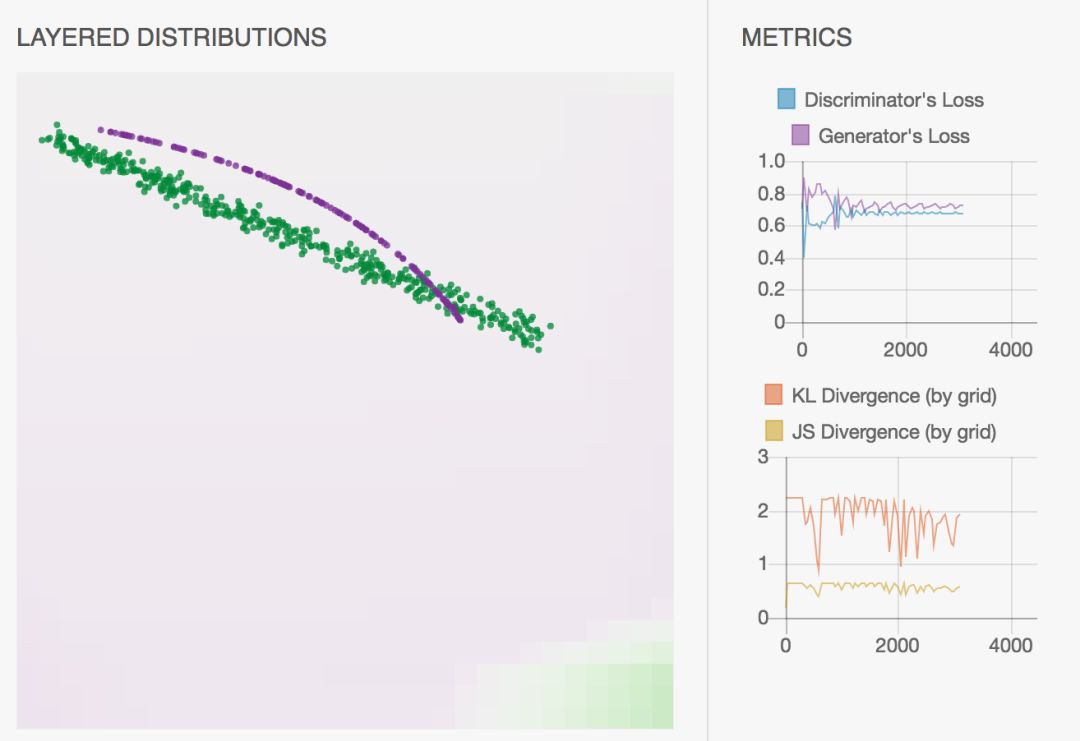
GANLab 的最右边,是 Metrics 量表区,展示一些学习过程中的 Loss 情况;一般来说,这些Loss 信息,并不能用来判断 GAN 到底收敛与否。具体情况, 大家可以自行尝试, 相信你会对 GAN 有一个全新的认知。
☞ OpenPV平台发布在线的ParallelEye视觉任务挑战赛
☞【学界】OpenPV:中科院研究人员建立开源的平行视觉研究平台
☞【学界】ParallelEye:面向交通视觉研究构建的大规模虚拟图像集
☞【CFP】Virtual Images for Visual Artificial Intelligence
☞【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞【学界】Ian Goodfellow等人提出对抗重编程,让神经网络执行其他任务
☞【学界】六种GAN评估指标的综合评估实验,迈向定量评估GAN的重要一步
☞【资源】T2T:利用StackGAN和ProGAN从文本生成人脸
☞【学界】 CVPR 2018最佳论文作者亲笔解读:研究视觉任务关联性的Taskonomy
☞【业界】英特尔OpenVINO™工具包为创新智能视觉提供更多可能
☞【学界】ECCV 2018: 对抗深度学习: 鱼 (模型准确性) 与熊掌 (模型鲁棒性) 能否兼得





