浅谈卷积神经网络的模型结构
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文授权转载自:SIGAI
SIGAI特约作者
vicFigure 上海交通大学
研究方向:计算机视觉、机器学习
20世纪末,卷积神经网络就已经在MNIST手写体数字识别任务上展现出了优势,但由于数据量和硬件性能的限制,始终没有在其他任务中发挥作用。随着硬件计算能力,存储能力的提升,卷积神经网络在21世纪取得了爆发性的进展。同时训练数据量也在成百倍甚至千倍的增长,更促进了卷积神经网络的进步。从LeNet5,到AlexNet,经过了20年的探索,而从AlexNet开始之后的短短几年,VGG,GoogLeNet,ResNet,DensNet等结构纷纷涌现,不断刷新卷积神经网络在各种标准数据集上的精度,同时也拓宽了卷积神经网络的应用范围:从分类任务,物体识别,图像分割这些基本任务,拓展到人脸识别,人体关键点检测,三维重建等实际的应用场景。今天笔者就来浅谈一下最近几年卷积神经网络的经典结构。
AlexNet
AlexNet是2012年ILSVRC分类任务比赛的冠军,首次证明了卷积神经网络在更加复杂的分类任务(相比于MNIST和Cifar数据集)上有着极大的优势。AlexNet的结构特征如下:
第一,AlexNet网络由有5层卷积层,和3层全联接层构成,最后一个全联接层得到各类别概率。第二,AlexNet使用ReLU作为激活层,代替tanh,作者经过实验,发现ReLU激活层的网络相对于tanh,在cifar10数据集上收敛速度更快。此后ReLU便成为了卷积神经网络标准的激活函数,在后面的结构中依然使用ReLU激活函数。第三,AlexNet使用LRN(Local Response Normalization)作为归一化函数,如式1.1所示。第四,AlexNet使用了3个max pooling层来做下采样,同时第一层卷积的卷积核大小设定为11*11,滑动步长为4,也有下采样的作用。第五,AlexNet采用Dropout层来减少过拟合问题。
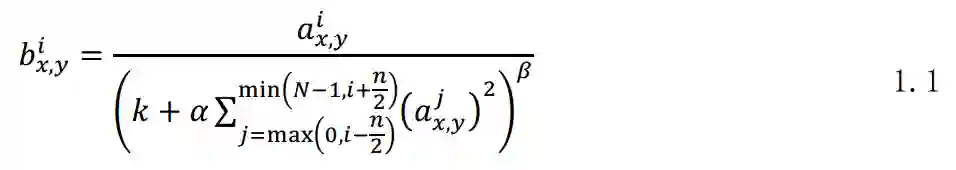
式中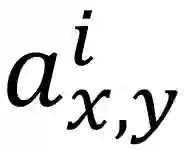
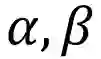
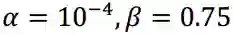
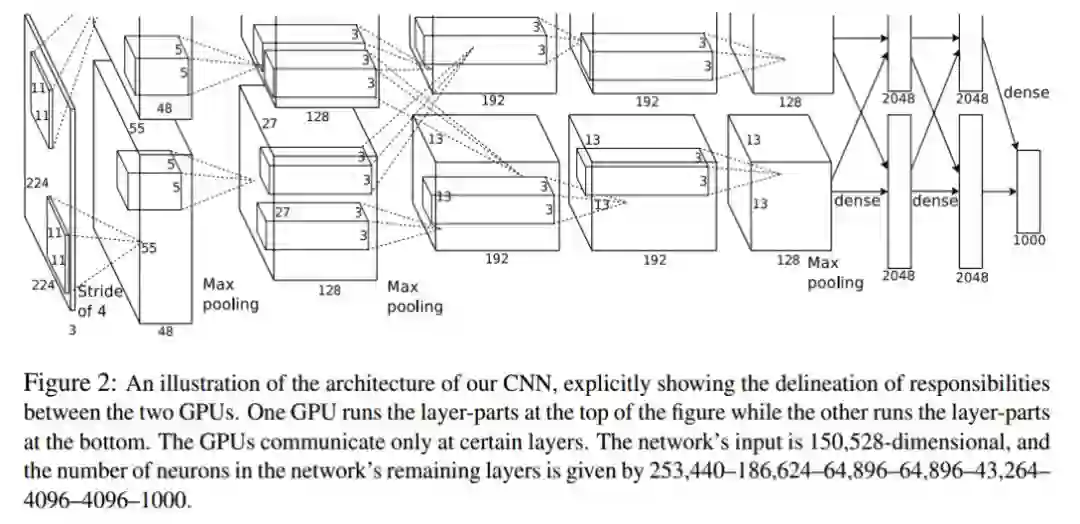
图1.1 AlexNet结构
总体来看,AlexNet结构是LeNet5的一个推广,在其基础上增加了更多的卷积层和全联接层通道,并通过多次下采样,使网络可以处理224*224的大尺度图片。AlexNet证明了卷积神经网络的能力,将卷积神经网络的研究再一次推向高潮。
VGG
VGG是2014年ILSVRC分类任务比赛的亚军,相比于AlexNet,VGG有着更复杂的网络结构,更多的网络参数和连接,其结构如图2.2所示,VGG的网络结构特点如下:
第一,VGG的第一个卷积层没有使用11*11或7*7这种大卷积核,作者经过分析,发现由3个3*3的卷积级联在一起,可以得到和7*7相同的感受野,而3个3*3卷积的参数几乎为1个7*7卷积参数的一半。第二,VGG中去除了LRN归一化层,作者经过实验(图2.2中A结构和A-LRN结构),发现LRN层并不能提高精度,反而增加了计算量,需要更多的计算存储单元。第三,VGG首先训练浅网络结构,然后利用训练好的浅层网络,初始化深层网络,网络深度逐步加深(图1.1中ABCDE的深度逐步增加),可以说VGG网络将模型初始化用到了极致。第四,在测试阶段,VGG最后的三层fc层均被替换成相同参数量的1*1卷积层,这样可以保证输入图片的尺度可以变化,不需要局限在224*224,最终输出的特征图直接做平均,即得到了最终的概率。

图2.1 VGG参数量
VGG模型的参数量接近AlexNet的3倍(其参数量如图2.1所示),大部分参数集中在第一个fc层,因为经过之前的特征提取网络,第一个fc层输入特征图尺度为7*7,所以第一个fc层的参数量为512*7*7*4096,占VGG19(E结构)总参数量的70%,这也是AlexNet参数量大的原因。与VGG同年的GoogLeNet则使用avg_pooling(Network in Network最先提出),先将7*7的特征图变为1*1,极大地减少了模型参数,后面的经典结构中也都普遍采用了avg_pooling的方法。
实际上,去除掉fc层的VGG网络有着很强的学习能力,而且参数量也下降到了可以接受的程度,因此Faster-RCNN等网络仍然采用VGG的卷积层结构作为基础网络骨架。
除了以上结构上的特点外,VGG作者在图片尺度、随机裁剪(图像预处理)方面进行了大量的实验,为后面卷积神经网络的工作提供了经验性的提示。笔者在这里就不在赘述,如果大家有兴趣,可以翻阅VGG原始论文。
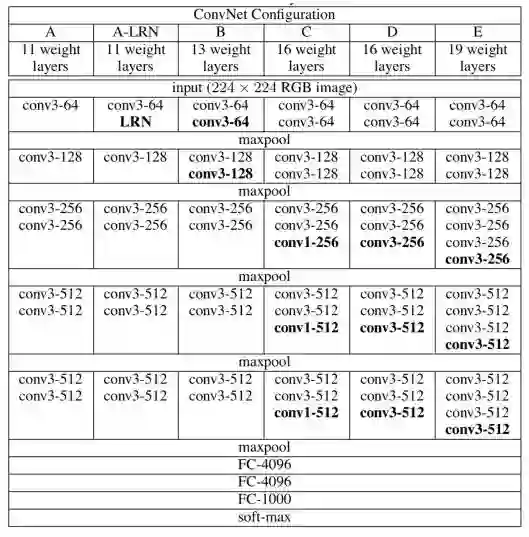
图2.2 VGG网络结构
GoogLeNet
说完VGG,不得不谈起与VGG同年竞争的GoogLeNet,2014年的ILSVRC分类任务比赛可以说是竞争极其激烈的一年,VGG亚军,GoogLeNet荣获冠军
GoogLeNet的参数量仅为AlexNet的1/12,其分类精度却比AlexNet高很多。在ILSVRC分类任务中,GoogLeNet使用7个模型集成,每张图片做144个随机裁剪的方法,达到了比VGG更高的分类精度,但7个模型的参数量依然小于VGG。相比于VGG,GoogLeNet在网络结构上进行了大量的实验,最终确定的模型基本结构称为Inception V1,如图3.1所示(因为后续谷歌团队又在此基础上,提出了Inception V2,V3,以及Inception-Residual结构),最终Inception V1确定为图3.1(b)
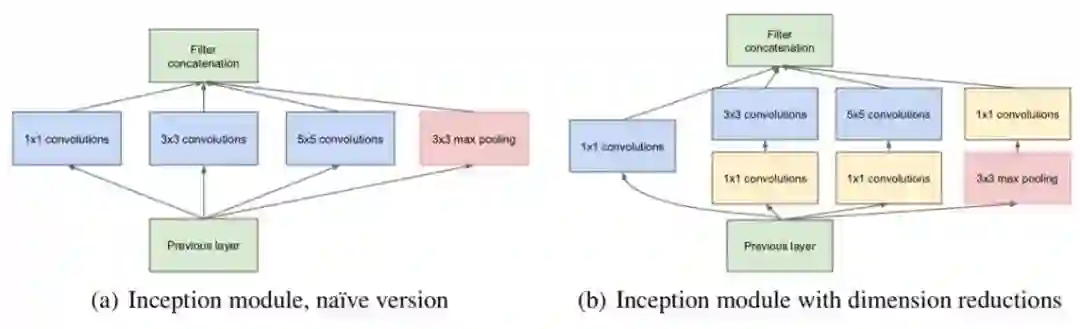
图3.1 Inception V1结构
GoogLeNet团队首先抓住了卷积神经网络的痛点之一:参数多层数深的网络不容易训练,很可能造成参数冗余,而且精度的提升与参数的增加往往不成比例,于是作者考虑,能否将连接稀疏化,同时保留卷积和全联接层的张量数据结构(因为稀疏卷积的运算效率并不高)
GoogLeNet结构如图3.2所示,其特点如下:
第一,Inception结构有4个分支,包括1*1卷积,3*3卷积,5*5卷积,以及下采样分支,这种不同卷积核尺度的分支可以提供不同的感受野,最终各个分支的特征图级联在一起得到Inception结构的输出。而图3.1(b)中3*3,5*5分支中的1*1卷积则是为了压缩特征图的空间尺度,进一步减少参数量。
第二,Inception结构中每个卷积后都会经过ReLU激活。
第三,GoogLeNet在fc层之前,采用global average pooling的方法,将特征图空间尺度压缩为1*1,然后仅用1层fc结构,输出为各类别的概率。
第四,GoogLeNet同样适用dropout层,减少过拟合问题。
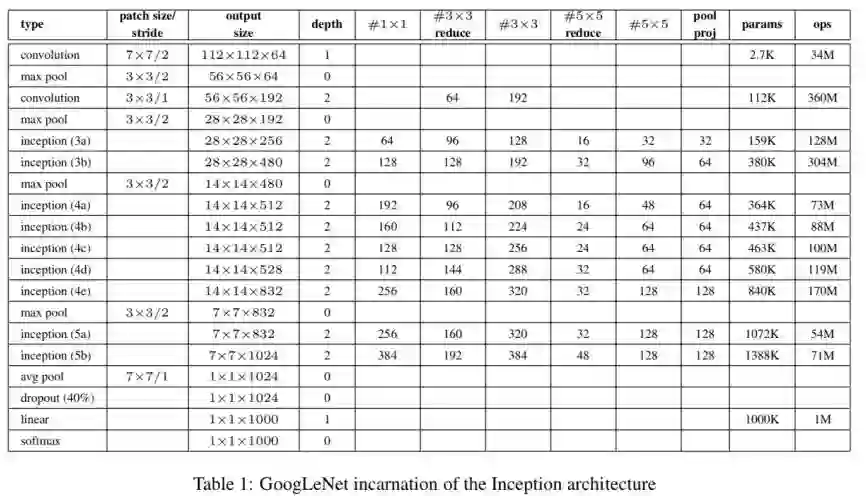
图3.2 GoogLeNet网络结构
进一步,(不知是不是收到了VGG的启发,笔者瞎猜),GoogLeNet团队将5*5的分支变成2个3*3卷积级联,减少了参数量,于是得到了InceptionV2结构,如图3.3所示。再进一步,如果将3*3卷积拆分成1*3和3*1两个卷积,又可以在保留原始感受野的基础上,减少参数量,如图3.4所示,然而经过实验,作者发现对于非对称的Inception结构,当输入特征图尺度在12~20之间,且n取7时(并非3),效果是最好的。
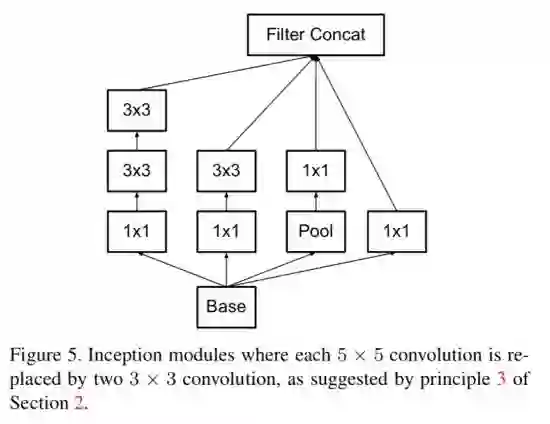
图3.3 Inception V2基本结构
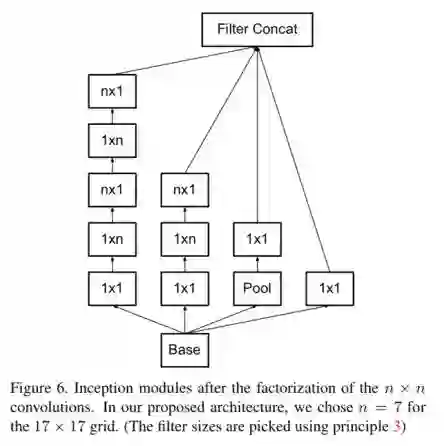
图3.4 非对称Inception V2结构
同时,作者提出了4个网络设计原则:
第一,尽量避免瓶颈结构,channel剧烈减少,尤其是在浅层部分(然而ResNet用实验打破了这个原则)
第二,可以增加Inception的宽度(更多的特征图),有助于学习到更多更好的特征
第三,在深层部分,引入瓶颈结构,不会降低太多精度,同时有助于快速训练
第四,网络的宽度与深度需要平衡
基于上述4个原则,作者进一步提出了深层的Inception结构(实验发现输入特征图尺度约等于8时,效果最好),如图3.5所示。
于是在GoogLeNet的基础上,作者基于图3.3,3.4,3.5所示的三种Inception结构,搭建得到了新的网络,在增加少量计算量的基础上,进一步提升了GoogLeNet的精度。
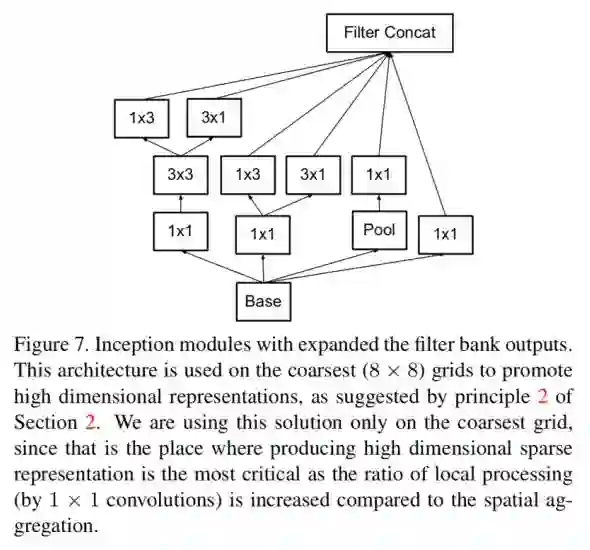
图3.5 深层Inception结构
ResNet
ResNet是ILSVRC2015年分类任务的冠军,作者首先通过堆叠vgg的基本模块(3*3卷积和ReLU激活层)得到20层网络和56层网络在Cifar10和ImageNet上进行了训练,发现56层网络的精度远没有20层效果好,基于此,作者提出了shortcut连接,即在某层特征图加上之前层的特征图,如图4.1左侧所示,最终形成bottleNeck结构如图4.1右侧所示。
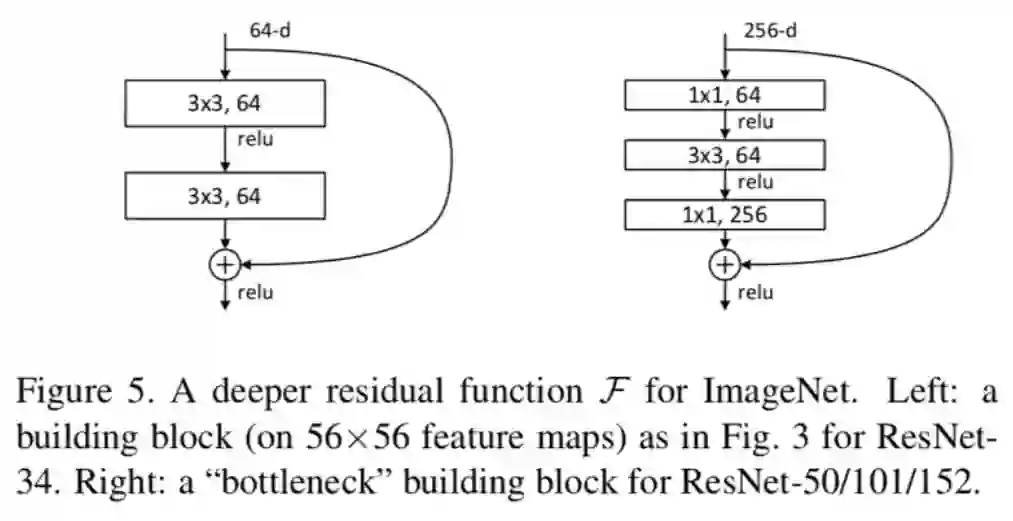
图4.1 bottleNeck结构
之所以叫bottleNeck,是因为首先用1*1卷积,将特征图通道数压缩到原先的1/4,然后过3*3的卷积,最后再用1*1卷积将特征图通道数还原成原来的大小(或者是原本通道数的2倍)。ResNet就可以根据图4.1中的结构进行堆叠,得到不同层数的网络,一些经典的ResNet结构如图4.2所示
此外,作者采用了BN归一化,采用“卷积-BN-ReLU”的基本卷积单元,对于bottleNeck输入特征图与输出特征图不变的模块,shortcut分支采用直连的方法,否则,作者在shortcut分支加入一层卷积层(卷积+BN),得到的输出再与另一个分支的输出特征图相加,再过ReLU激活
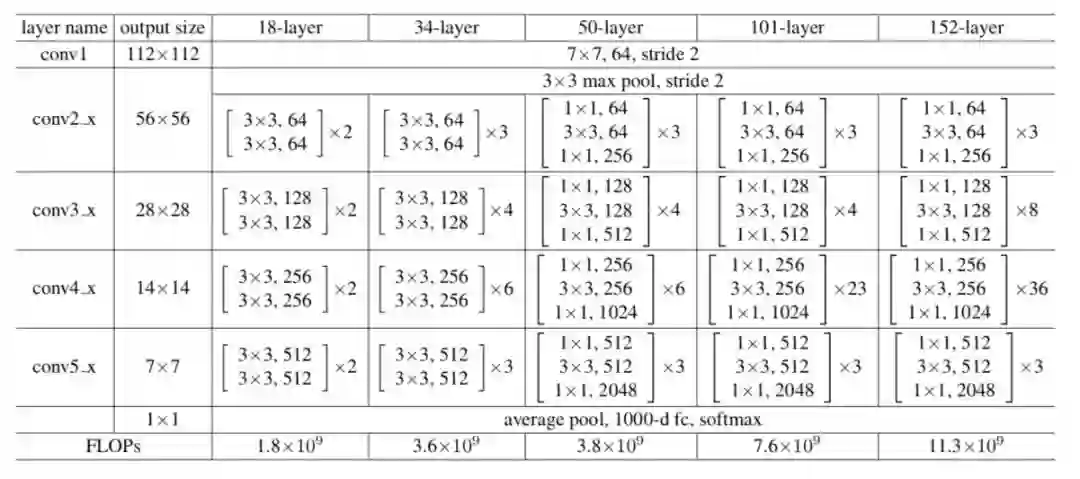
图4.2 ResNet结构
作者经过大量实验,证明了ResNet的结构可以完美解决之前“层数越深,效果越差”的问题。从某种意义上,ResNet出现后,卷积神经网络将“深度”变为了可能。ResNet提出之后,也有大量的论文来研究讨论为什么ResNet可以解决上述问题,而且也有论文从不同角度证明Shortcut的结构有很强的学习能力。
DenseNet
DenseNet进一步将shortcut结构发展到了极致,提出了DenseBlock的结构,在一个DenseBlock中,每个中间层的特征图输出都会连接到后面的层的特征图,而DenseNet与ResNet最大的不同之处就是:ResNet中两个分支采用加法的方式进行融合,而DenseNet中多个分支采用级联(在通道维度上拼接在一起)的方式融合。DenseBlock的结构如图5.1所示。
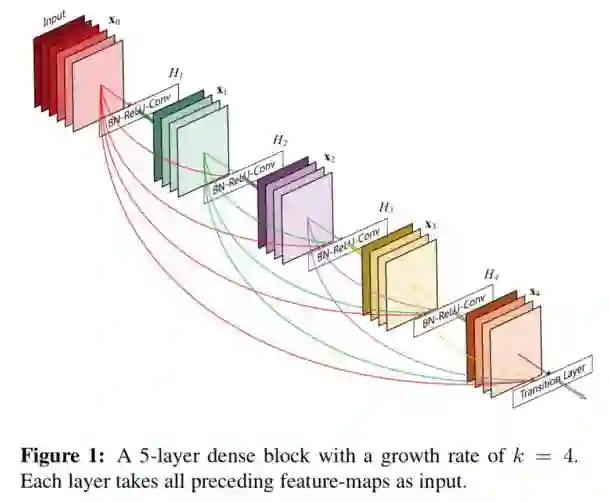
图5.1 DenseBlock
图中不同颜色表示不同中间层的输出特征图,最后的Transition Layer则是由BN+卷积层构成,其目的是为了对最后级联起来的特征图做信息交流和融合,同时控制DenseBlock的输出特征图数,整体DenseNet的网络结构如图5.2所示,DenseNet的参数量相比于ResNet进一步减少,但其精度更高。然而值得注意的一点是,虽然DenseNet的参数量很小,但其计算量依然比较大。
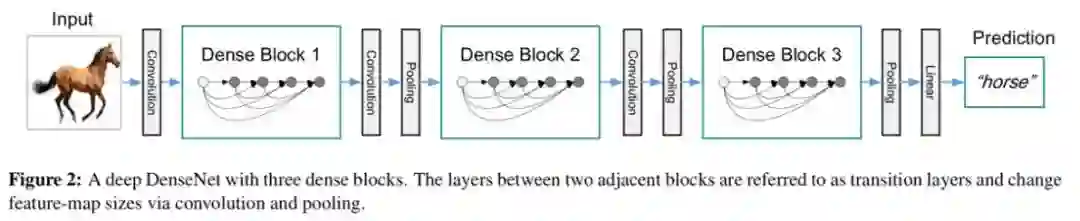
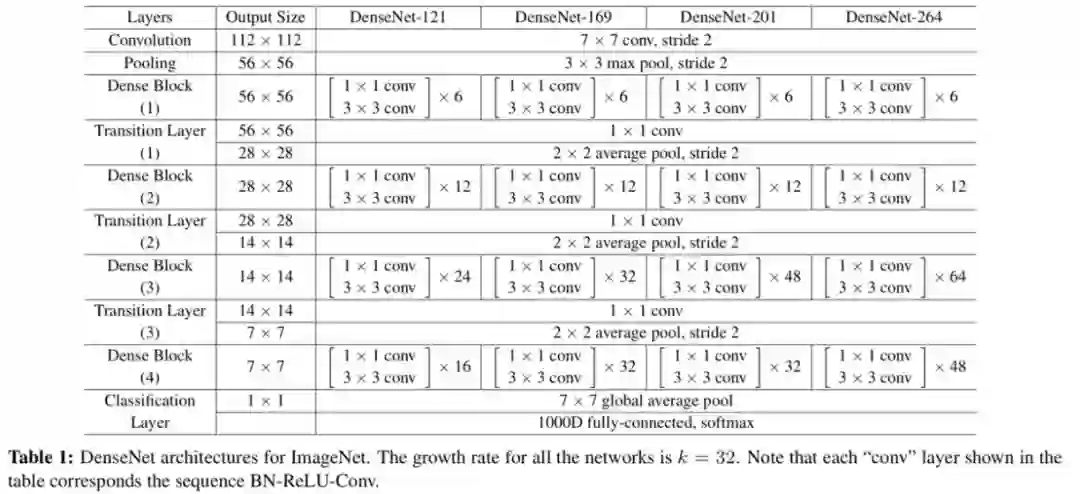
图5.2 DenseNet
总结
从2012年始,卷积神经网络的模型结构开始了飞速的发展,笔者仅仅谈到了几个经典的网络结构,但同样还有一些小而精巧的网络结构没有涉及,比如MobileNet,ShuffleNet等,还有一些根据特殊应用场景设计的网络结构,如Yolo等。此外,当前的研究者并不满足于用人工的方式探索有效的网络结构,NAS(网络结构搜索)问题也越来越成为研究的热点,相信未来会有更多高效的网络结构,而经典永远都是经典,即使长江后浪推前浪,其设计的精髓和实验依然值得后来人细细品味。
参考文献
[1] Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks[C]//Advances in neural information processing systems. 2012: 1097-1105.
[2] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[J]. arXiv preprint arXiv:1409.1556, 2014.
[3] Szegedy C, Liu W, Jia Y, et al. Going deeper with convolutions[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2015: 1-9.
[4] Szegedy C, Vanhoucke V, Ioffe S, et al. Rethinking the inception architecture for computer vision[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 2818-2826.
[5] He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778.
[6] Huang G, Liu Z, Van Der Maaten L, et al. Densely connected convolutional networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 4700-4708.
CVer学术交流群
扫码添加CVer助手,可申请加入CVer-目标检测交流群、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测和模型剪枝&压缩等群。一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡)

▲长按加群

▲长按关注我们
麻烦给我一个在看!

