综述 | 一文看尽三种针对人工智能系统的攻击技术及防御策略
选自EliE
作者:Elie Bursztein
机器之心编译
参与:Nurhachu Null、张倩
本文综述了三种针对人工智能系统的攻击技术——对抗性输入、数据中毒攻击及模型窃取技术,在每一种攻击的讨论中都加入了具体例子及防御策略,旨在为所有对利用人工智能进行反滥用防御感兴趣的人提供一个概述。
对分类器的高层次攻击可以分为以下三种类型:
对抗性输入:这是专门设计的输入,旨在确保被误分类,以躲避检测。对抗性输入包含专门用来躲避防病毒程序的恶意文档和试图逃避垃圾邮件过滤器的电子邮件。
数据中毒攻击:这涉及到向分类器输入对抗性训练数据。我们观察到的最常见的攻击类型是模型偏斜,攻击者以这种方式污染训练数据,使得分类器在归类好数据和坏数据的时候向自己的偏好倾斜。我们在实践中观察到的第二种攻击是反馈武器化(feedback weaponization),它试图滥用反馈机制来操纵系统将好的内容误分类为滥用类(例如,竞争者的内容或者报复性攻击的一部分)。
模型窃取技术:用来通过黑盒探测「窃取」(即复制)模型或恢复训练数据身份。例如,这可以用来窃取股市预测模型和垃圾邮件过滤模型,以便使用它们或者能够针对这些模型进行更有效的优化。
这篇文章依次探讨了每一类攻击,提供了具体的例子,并且讨论了可能的缓解方法。
这篇文章是关于如何使用人工智能构建鲁棒的反滥用保护系统系列文章中的第四篇,也是最后一篇。第一篇文章解释了为何 AI 是构建鲁棒的保护系统的关键,这种保护用来满足用户期望和日益提升的复杂攻击。在介绍完构建和启动一个基于 AI 的防御系统的自然过程之后,第二篇博文涵盖了与训练分类器相关的挑战。第三篇文章探讨了在生产中使用分类器来阻止攻击的主要困难。
这一系列文章是根据我在 RSA 2018 上的演讲写出来的。
声明:这篇文章旨在为所有对利用人工智能进行反滥用防御感兴趣的人提供一个概述,它是那些正在跳跃观望的人的潜在蓝图。因此,这篇文章侧重于提供一个清晰的高层次总结,有意不深入技术细节。也就是说,如果你是一名专家,我相信你会发现你以前没有听说过的想法、技术和参考资料,希望你会受到启发,并进一步探索它们。
对抗性输入
对手不断用新的输入/有效载荷来探测分类器,试图逃避探测。这种有效载荷被称为对抗性输入,因为它们被明确设计成绕过分类器。
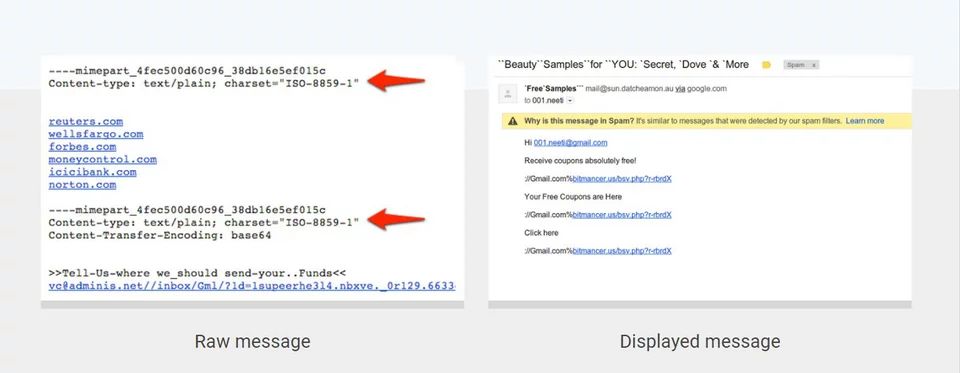
这是一个对抗输入的具体例子:几年前,一个聪明的垃圾邮件发送者意识到,如果同一个 multipart 附件在一封电子邮件中出现多次,Gmail 将只显示上图屏幕截图中可见的最后一个附件。他将这一知识武器化,增加了不可见的第一个 multipart,其中包含许多著名的域,试图逃避检测。此攻击是称为关键字填充的攻击类别的一个变体。
一般来说,分类器迟早会面临两种对抗性输入:变异输入,这是为避开分类器而专门设计的已知攻击的变体;零日输入,这是在有效载荷之前从未见过的。让我们依次探究每一种对抗性输入。
变异输入
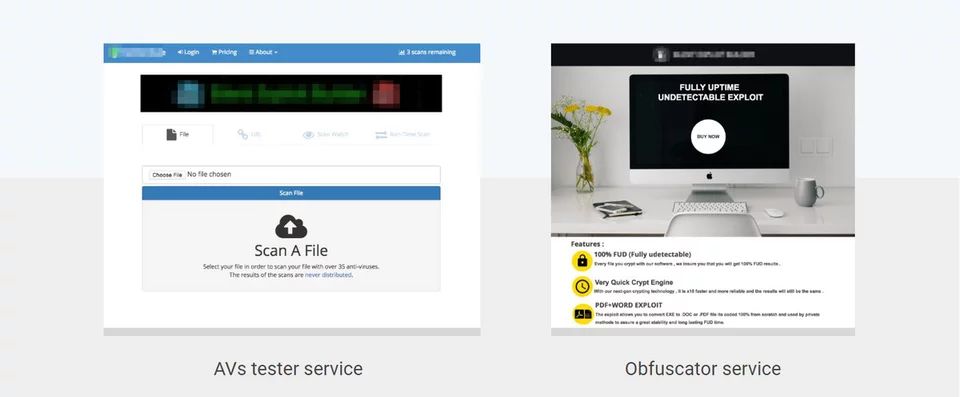
在过去的几年里,我们看到地下服务爆炸式增长,这种服务旨在帮助网络犯罪分子制造不可探测的有效载荷,在秘密世界中最有名的是 FUD(完全不可探测的) 有效载荷。这些服务从允许针对所有防病毒软件测试有效负载的测试服务,到旨在以使恶意文档不可检测的方式混淆恶意文档的自动打包程序。上面的截图展示了两个这样的服务。
专门从事有效载荷制造的地下服务的重新出现凸显了这样一个事实:
攻击者主动优化攻击,以确保最小化分类器检测率。
因此,必须开发检测系统,使攻击者难以进行有效负载优化。下面是三个关键的设计策略来帮助实现这一点。
1. 限制信息泄露

这里的目标是确保攻击者在探查你的系统时获得尽可能少的收获。保持反馈最小化并尽可能延迟反馈是很重要的,例如避免返回详细的错误代码或置信度值。
2. 限制探测
此策略的目标是通过限制攻击者针对你的系统测试有效负载的频率来降低攻击者的速度。通过限制攻击者对你的系统执行测试的频率可以有效降低他们设计有害有效负载的速度。
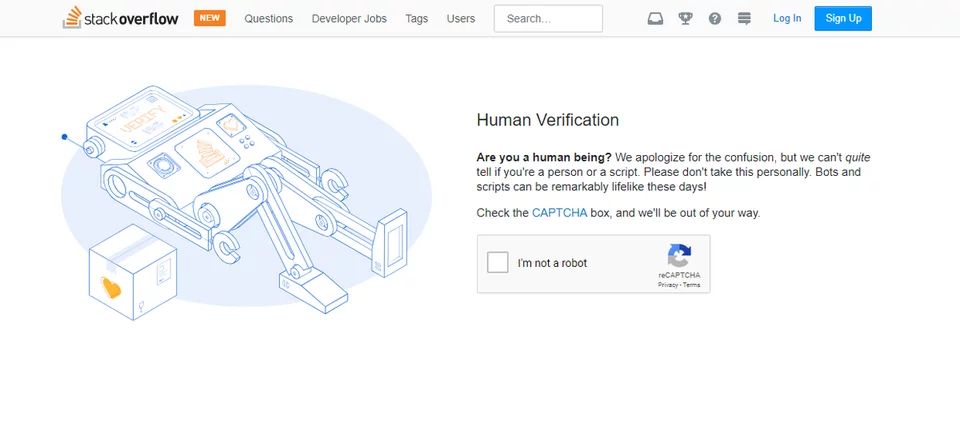
这一策略主要是通过对稀缺资源(如 IP 和帐户)实施速率限制来实现的。这种速率限制的典型例子是要求用户解决验证码,验证他是否发布的太频繁,如上所示。
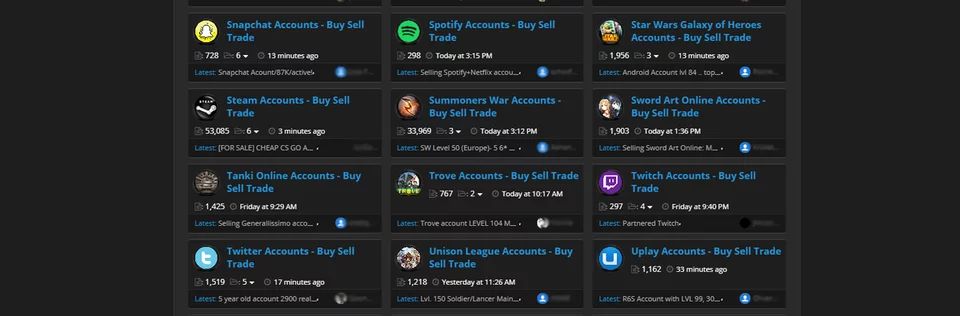
这种主动限制活动率的负面影响是,它会鼓励不良行为者创建假账户,并使用受损的用户计算机来分散他们的 IP 池。业内广泛使用限速是非常活跃的黑市论坛兴起的一个主要驱动因素,在这些论坛中,账户和 IP 地址被常规出售,如上面的截图所示。
3. 集成学习
最后但同样重要的是,结合各种检测机制,使攻击者更难绕过整个系统。使用集成学习将基于声誉的检测方法、人工智能分类器、检测规则和异常检测等不同类型的检测方法结合起来,提高了系统的鲁棒性,因为不良行为者不得不同时制作避免所有这些机制的有效载荷。

例如,如上面的截图所示,为了确保 Gmail 分类器对垃圾邮件制造者的鲁棒性,我们将多个分类器和辅助系统结合在一起。这样的系统包括声誉系统、大型线性分类器、深度学习分类器和其他一些秘密技术。
深度神经网络对抗攻击实例
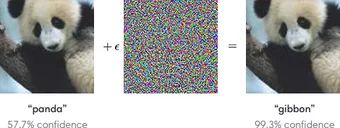
如何制作欺骗深度神经网络(DNN)的对抗例子是一个非常活跃的相关研究领域。现在,创建难以察觉的扰动,彻底骗过 DNN 是一件小事,如上面从论文《Explaining and Harnessing Adversarial Examples》(https://arxiv.org/abs/1412.6572)截取的图片所示。
最近的研究 (https://arxiv.org/abs/1711.11561) 表明,CNN 容易受到对抗性输入攻击,因为他们倾向于学习表面的数据集的规则性,而不是很好地泛化和学习不太容易受到噪声影响的高级表征。
这种攻击会影响所有 DNN,包括基于增强学习的 DNN (https://arxiv.org/abs/1701.04143 ),如上面视频中所强调的。要了解更多关于此类攻击的信息,请阅读 Ian Goodfellow 关于此主题的介绍文章,或者开始尝试 Clever Hans 的实验 (https://github.com/tensorflow/cleverhans)。
从防御者的角度来看,这种类型的攻击已经被证明(到目前为止)是非常有问题的,因为我们还没有有效的方法来防御这种攻击。从根本上说,我们没有一种有效的方法让 DNN 为所有输入产生良好的输出。让他们这样做是非常困难的,因为 DNN 在非常大的空间内执行非线性/非凸优化,我们还没有教他们学习泛化良好的高级表征。你可以阅读 Ian 和 Nicolas 的深度文章(http://www.cleverhans.io/security/privacy/ml/2017/02/15/why-attacking-machine-learning-is-easier-than-defending-it.html)来了解更多关于这个的信息。
零日输入
另一种可以完全抛弃分类器的明显的对抗性输入是新的攻击。新的攻击不常发生,但知道如何应对仍然很重要,因为它们可能具有相当大的破坏性。
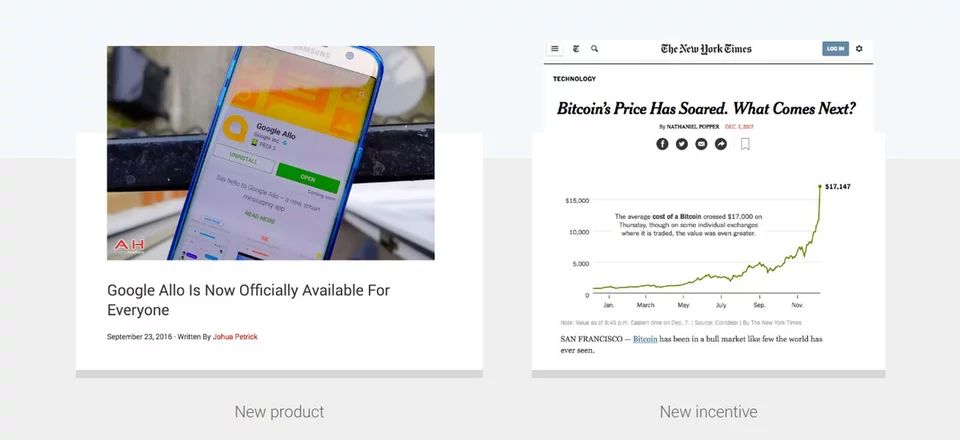
尽管出现新攻击有许多不可预测的潜在原因,但根据我们的经验,以下两种事件可能会触发新攻击的出现:
新产品或功能推出:本质上,增加功能会为攻击者打开新攻击面,有利于它们快速进行探查。这就是为什么新产品发布时提供零日防御是必要的(但很难)。
增加奖励 :虽然很少讨论,但许多新的攻击激增是由攻击媒介推动的,变得非常有利可图。这种行为最近的一个例子是,针对 2017 年底比特币价格飙升,滥用 Google Cloud 等云服务来挖掘加密数字货币的行为有所抬头。
随着比特币价格飙升至 1 万美元以上,我们看到新的攻击风起云涌,企图窃取 Google 云计算资源用于挖掘。稍后我将在这篇文章中介绍我们是如何发现这些新攻击的。

总之,Nassim Taleb 形式化的黑天鹅理论(Black swan theory)适用于基于人工智能的防御,就像它适用于任何类型的防御一样。
不可预测的攻击迟早会抛弃你的分类器并将产生重大影响。
然而,不是因为你无法预测哪些攻击会抛弃你的分类器,或者这样的攻击什么时候会攻击你,而你无能为力。你可以围绕这类袭击事件进行规划,并制定应急计划来缓解这种情况。在为黑天鹅事件做准备时,这里有几个可以探索的方向。
1. 制定事件响应流程
首先要做的是开发和测试事件恢复过程,以确保在措手不及时做出适当反应。这包括但不限于:在调试分类器时,有必要的控件来延迟或停止处理,并知道调用哪个。
Google SRE(站点可靠性工程)手册有一章关于事件管理(https://landing.google.com/sre/book/chapters/managing-incidents.html),还有一章关于应急响应 ( https://landing.google.com/sre/book/chapters/emergency-response.html)。有关更加以网络安全为中心的文档,应该查看 NIST (National Institute of Standards and Technology)网络安全事件恢复指南(https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-184.pdf)。最后,如果你更愿意看一段对话,请看一下「Google 如何运行灾难恢复培训 (DiRT) 程序」的视频 (https://www.usenix.org/conference/lisa15/conference-program/presentation/krishnan),以及「Faceboook 如何做出事件响应」的视频(https://www.usenix.org/node/197445)。
2. 使用迁移学习来保护新产品
明显的关键困难是你没有过去的数据来训练你的分类器。缓解这一问题的一种方法是利用迁移学习,它允许你重用一个域中已经存在的数据,并将其应用到另一个域。
例如,如果你处理图像,你可以利用现有的预先训练好的模型(https://keras.io/applications/),而如果你处理文本,你可以使用公共数据集,比如Toxic Comment的 Jigsaw 数据集。
3. 利用异常检测
异常检测算法可以用作第一道防线,因为从本质上说,新的攻击将产生一组从未遇到过的异常,这些异常与它们如何使用你的系统有关。

引发一系列新反常现象的新攻击的历史性案例是针对马萨诸塞州 WinFall 彩票游戏的麻省理工赌博集团攻击(https://www.theatlantic.com/business/archive/2016/02/how-mit-students-gamed-the-lottery/470349/)。
早在 2005 年,多个赌博集团就发现了 WinFall 彩票系统的一个缺陷:当累积奖金在所有参与者之间平分时,你每买一张 2 美元的彩票,平均就能挣 2.3 美元。每次资金池超过 200 万美元时,这种被称为「roll-down」的分裂就会发生。
为了避免与其他团体分享收益,麻省理工学院的团体决定提前三周大规模买断彩票,从而引发一场减持行动。很明显,这种从极少数零售商手中购买的大量彩票造成了彩票组织察觉到的大量异常现象。

最近,正如本文前面提到的,当比特币价格在 2017 年疯狂上涨时,我们开始看到一大批不良行为者试图通过免费使用 Google cloud 实例进行挖掘,从这一热潮中获益。为了免费获取实例,他们试图利用许多攻击媒介,包括试图滥用我们的免费层、使用被盗信用卡、危害合法云用户的计算机以及通过网络钓鱼劫持云用户的帐户。
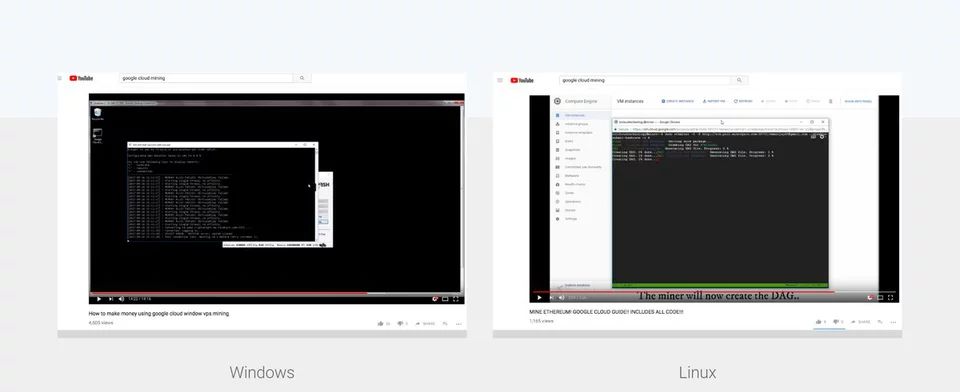
很快,这种攻击变得非常流行,以至于成千上万的人观看了 YouTube 上关于如何在 Google cloud 上挖掘的教程(这在正常情况下是无利可图的)。显然,我们无法预料恶意挖矿会成为如此巨大的问题。
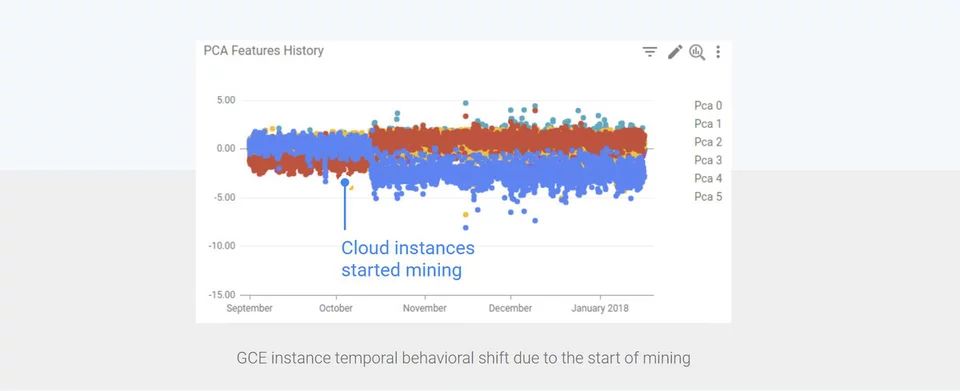
幸运的是,当异常发生时,我们已经为 Google Cloud 实例准备了异常检测系统。正如预料的那样,从我们的异常检测系统仪表板上直接获取的上图中可以看出,当实例开始挖掘时,它们的时间行为发生了巨大的变化,因为关联的资源使用与未妥协的云实例所显示的传统资源使用有着根本的不同。我们能够使用这种移位检测来遏制这种新的攻击媒介,确保涉及到的云平台和 GCE 客户端保持稳定。
数据中毒
分类器面临的第二类攻击涉及试图毒害你的数据以使你的系统行为出错的对手。
模型偏斜
第一种中毒攻击称为模型偏斜,攻击者试图污染训练数据,以移动分类器对好、坏输入归类的学习边界。例如,模型偏斜可以用来试图污染训练数据,欺骗分类器将特定的恶意二进制文件标记为良性。
具体例子
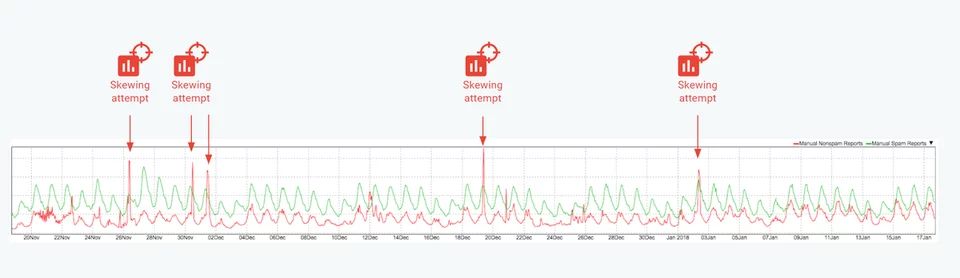
在实践中,我们经常看到一些最先进的垃圾邮件制造者团体试图通过将大量垃圾邮件报告为非垃圾邮件来使 Gmail 过滤器偏离轨道。如图所示,2017 年 11 月底至 2018 年初,至少有 4 次大规模恶意行动试图歪曲我们的分类器。
因此,在设计基于 AI 的防御时,你需要考虑以下事实:
攻击者积极地试图将学到的滥用和合理使用之间的界限转移到对他们有利的位置。
缓解策略
为了防止攻击者歪曲模型,可以利用以下三种策略:
使用合理的数据采样:需要确保一小部分实体(包括 IP 或用户)不能占模型训练数据的大部分。特别是要注意不要过分重视用户报告的假阳性和假阴性。这可能通过限制每个用户可以贡献的示例数量,或者基于报告的示例数量使用衰减权重来实现。
将新训练的分类器与前一个分类器进行比较以估计发生了多大变化。例如,可以执行 dark launch,并在相同流量上比较两个输出。备选方案包括对一小部分流量进行 A/B 测试和回溯测试。
构建标准数据集,分类器必须准确预测才能投入生产。此数据集理想地包含一组精心策划的攻击和代表你的系统的正常内容。这一过程将确保你能够在武器化攻击对你的用户产生负面影响之前,检测出该攻击何时能够在你的模型中产生显著的回归。
反馈武器化
第二类数据中毒攻击是将用户反馈系统武器化,以攻击合法用户和内容。一旦攻击者意识到你正在出于惩罚的目的以某种方式使用用户反馈,他们就会试图利用这一事实为自己谋利。
具体例子
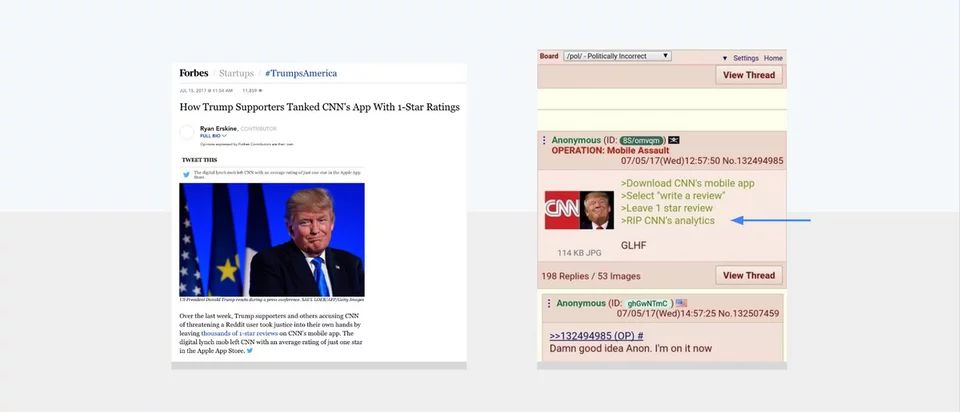
我们在 2017 年目睹的最令人震惊的将用户反馈武器化的尝试之一是一群 4chan 用户,他们决定通过留下数千个 1 星评级破坏 CNN 在应用商店的排名。
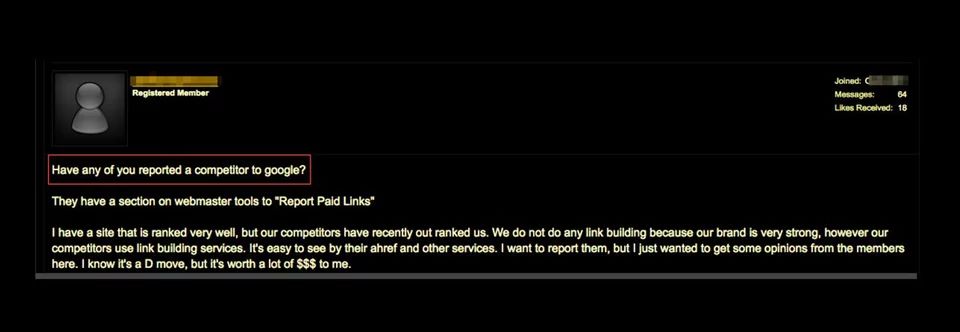
反馈武器化之所以被坏人积极利用,有很多原因,包括:试图压制竞争、进行报复、掩盖自己的行踪。上面的截图展示了一个黑市帖子,讨论了如何使用 Google 来击败竞争对手。
因此,在构建系统时,你需要在以下假设下工作:
任何反馈机制都将被武器化以攻击合法用户和内容。
缓解策略
在缓解反馈武器化的过程中,需要记住以下两点:
不要在反馈和惩罚之间建立直接循环。相反,在做出决定之前,确保评估反馈真实性,并将其与其他信号结合起来。
不要以为受益于滥用内容的所有者对此负有责任。举例来说,不是因为一张照片得到了数百个假的「赞」所有者才买下它。我们已经看到无数袭击者为了掩盖他们的踪迹或试图让我们惩罚无辜用户而榨取合法内容的案例。
模型窃取袭击
如果不提及旨在恢复训练期间使用的模型或数据信息的攻击,这篇文章将是不完整的。这种攻击是一个关键问题,因为模型代表了有价值的知识产权资产,这些资产是根据公司的一些最有价值的数据进行训练的,例如金融交易、医疗信息或用户交易。
确保接受过用户敏感数据(如癌症相关数据等)训练的模型的安全性至关重要,因为这些模型可能被滥用,泄露敏感用户信息 ( https://www.cs.cornell.edu/~shmat/shmat_oak17.pdf )。
攻击
模型窃取的两个主要攻击是:
模型重建:这里的关键思想是攻击者能够通过探测公共 API 来重新创建模型,并通过将其用作 Oracle 来逐步完善自己的模型。最近的一篇论文(https://www.usenix.org/system/files/conference/usenixsecurity16/sec16_paper_tramer.pdf)表明,这种攻击似乎对大多数人工智能算法有效,包括支持向量机、随机森林和深度神经网络。
成员泄露:在这里,攻击者构建影子模型,使他能够确定给定的记录是否用于训练模型。虽然此类攻击无法恢复模型,但可能会泄露敏感信息。
防御
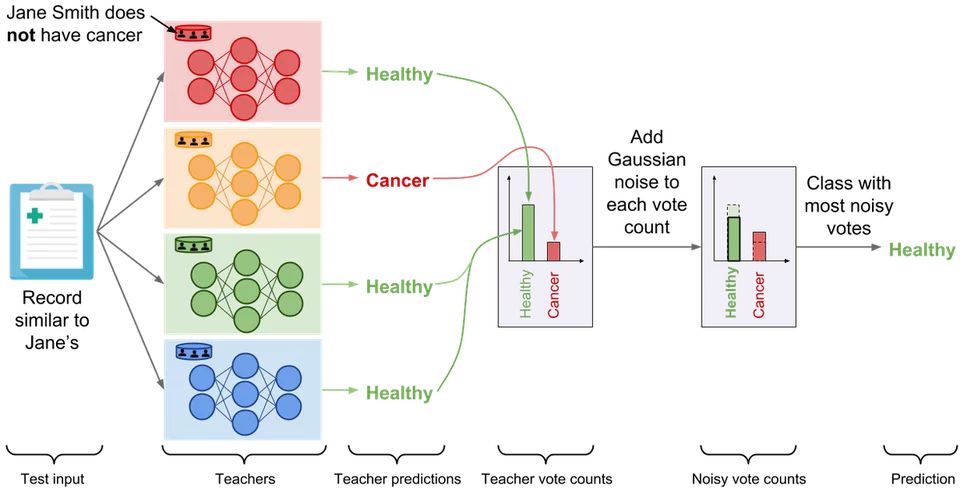
最著名的防御模型窃取攻击的方法是 PATE ( https://arxiv.org/abs/1802.08908),这是一个由 Ian Goodfellow 等人开发的隐私框架。如上图所示,PATE 背后的关键思想是对数据进行划分,并训练多个组合在一起的模型来做出决策。这一决策随后被其他不同隐私系统的噪声所掩盖。
要了解更多有关差分隐私的信息,请阅读 Matt 的介绍文章(https://blog.cryptographyengineering.com/2016/06/15/what-is-differential-privacy/)。要了解更多关于 PATE 和模型窃取攻击的信息,请阅读 Ian 关于此主题的文章(http://www.cleverhans.io/privacy/2018/04/29/privacy-and-machine-learning.html)。
结论
是时候结束这一系列关于如何利用人工智能打击欺诈和滥用的长文了。本系列的主要收获(详见第一篇文章)是:
AI是构建满足用户期待的保护机制和应对愈加复杂的攻击的关键。
正如这篇文章和前两篇文章所讨论的那样,要使这项工作在实践中发挥作用,还有一些困难需要克服。但是,既然 AI 框架已经成熟并有很好的文档记录,那么在你的防御系统中开始使用 AI 是再好不过的时候了,所以不要对这些挑战望而却步。

原文链接:https://elie.net/blog/ai/attacks-against-machine-learning-an-overview
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com
