海康威视提出:无监督图像分类的深度表征学习
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

本文作者: 黄维东
https://zhuanlan.zhihu.com/p/157849804
本文已由原作者授权,不得擅自二次转载

论文:https://arxiv.org/abs/2006.11480
最近因为工作原因,对半监督和无监督论文比较感兴趣,今天看到一篇讲图像分类无监督的文章"Unsupervised Image Classification for Deep Representation Learning",记录一下。
文章首先讲了下deep clustering 相比self-supervised learning而言是一个比较有前途的方向,但是做cluster的时候需要对embedding(feature map)做clustering对于数据集很大的情况下是非常消耗资源的(因为你需要把所有dataset对应的embedding都存起来),所以这篇文章主要就是提供了一个更加简单和优雅的框架来做这个事情,同时还分析了和deep clustering和contrastive learning的区别。
文章先引出deep clustering如何做的,其实思路也比较简单,就是用cnn取feature map作为clustering的依据,使用kmeans聚成K类,然后这K个类就是生成的label,再在CNN后面接output classifier(搞个全连接就够了)输出K类,训练学习,这里面有一个小细节就是output classifier和前面的cnn都是可以训练学习权重的(而文章方法接的是softmax layer就不需要学习权重了),这里面又重新强调了一下这个方法的缺点就是,训练所需内存开销和数据集是成正比的,不适合大数据场景。
然后文章开始引出他的做法,思路如下图所示,其实理解起来很简单,就是先用模型做inference生成label,然后拿这个label去训练模型,这两个阶段依次开展,直到整体收敛为止。这里面提到对这种做法最大的质疑点就是训练过程中很容易陷入局部最优点并且很难学习到有用的特征,文章提出解决这个问题的关键就是数据增强,在模型生成label的时候和训练的时候都需要加入数据增强,并且用到的是不同的增强方法。
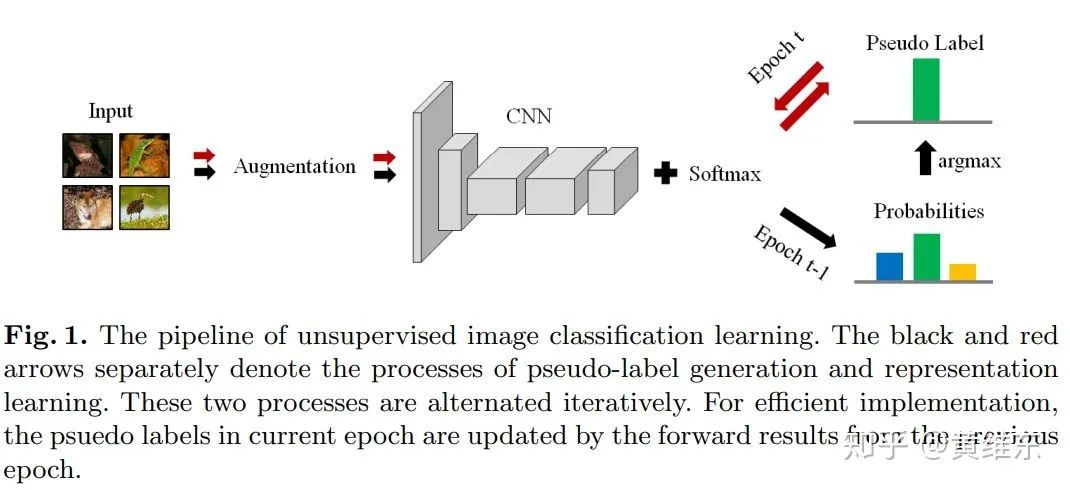
接着文章开始讨论和embedding clustering还有就是contrastive learning的关联。
从下图主要表示和embedding clustering的关联,将embedding clustering拆出三个关键要素,生成样本embedding/距离度量/聚类中心点生成,从这三要素角度来看的话,文章中的方法也可以拆开看同样具有这三个要素,样本embedding这块对应的是softmax layer的output,聚类数量就是分类的class num,而距离度量则是使用cross entropy,在如何聚类上面k-means是动态调整聚类中心然后根据距离聚类,再重新调整聚类中心依次进行,但是文章的方法和他最大的区别就是聚类中心是否会动态调整,文章认为kmeans中重要的是聚类中心调整,如何聚类并不重要,而文章中是固定聚类中心,只是去调整embedding的值来实现聚类,这里可以理解为是不是这样能够更好得学习如何做representation。
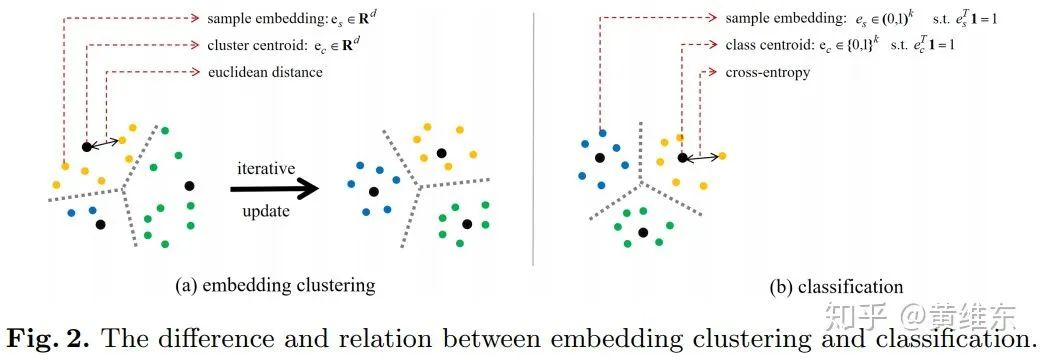
和contrastive learning的关系,这里不太详细讲了,主要原因也是因为我之前没太接触过contrastive learning,文章就提了下contrastive learning里面positive和negative的概念,在K分类问题中,选择第J类,其他类也可以做为negative对待,这样就和contrastive learning类似了
最后进入实验阶段,里面先说了两个比较关键的实现细节对效果影响大,(1)就是在训练初期,因为cnn模型在初始化阶段,这个时候很容易出现整个数据集有一个class都是空的情况,这种情况可以将有最多class的数据集随机分出一半给这个class,而这种一个class是空得情况主要发生在训练初期,训练中后期就不会出现了(2)需要控制class balance,所以需要做一些采样方法来保证,这个和传统的有监督训练中方法类似。
实验里面去评价无监督的效果主要通过两种方法,(1) 用一个线性分类器把无监督中间layer学习的representation作为输入,在有监督度的数据集训练查看效果(2) 使用transfer learning在其他任务中观察效果
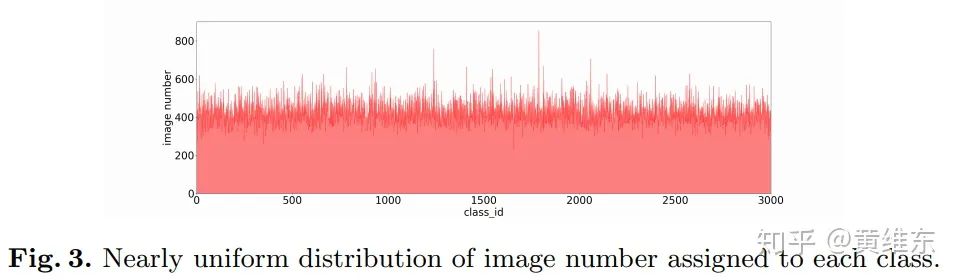
下面有两个图可视化的帮助理解文章方法的结果,图3拿训练好的模型看最后每个class的图片数量,可以看到非常均匀,这里推断是因为训练过程中用了class balance sampling的方法,第二个可以看到实际训练后已经把相似语义信息的图片分成同一个类别

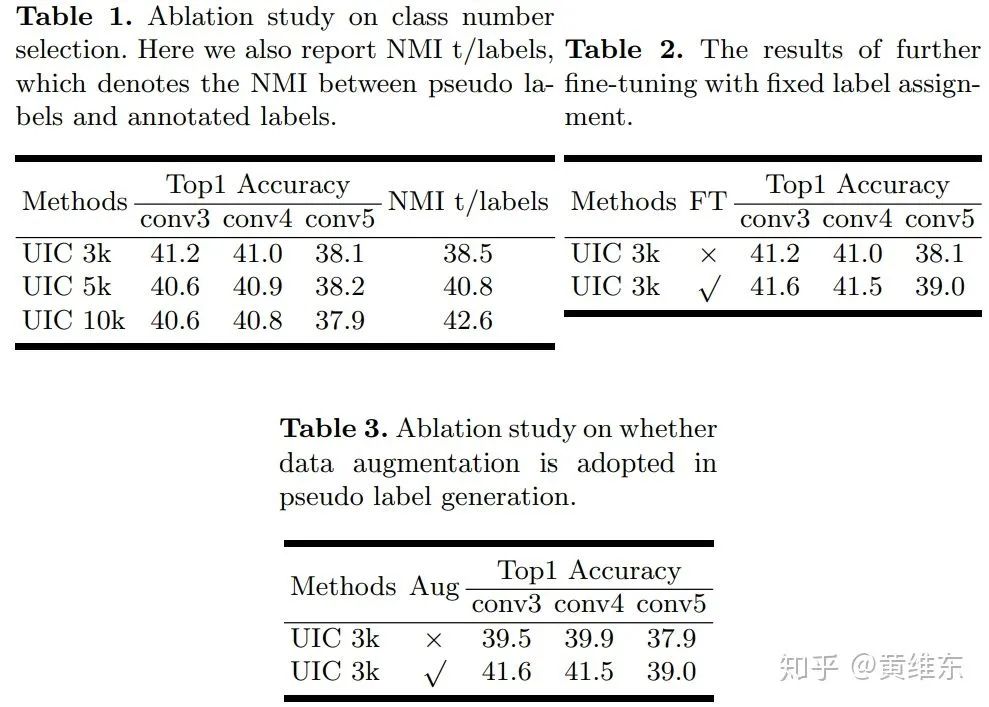
接着通过一个线性分类器观察class number/是否fine tuning/在生成样本的时候是否数据增强对实验结果的影响,如图所示,可以看到3k会比5k 10k好,有fine tuning会更好以及数据增强效果会更好
同时在线性分类器上和其他无监督方法都对比了一下,可以看出效果和deep cluster会相对比较接近,比self-supervised方法要好很多
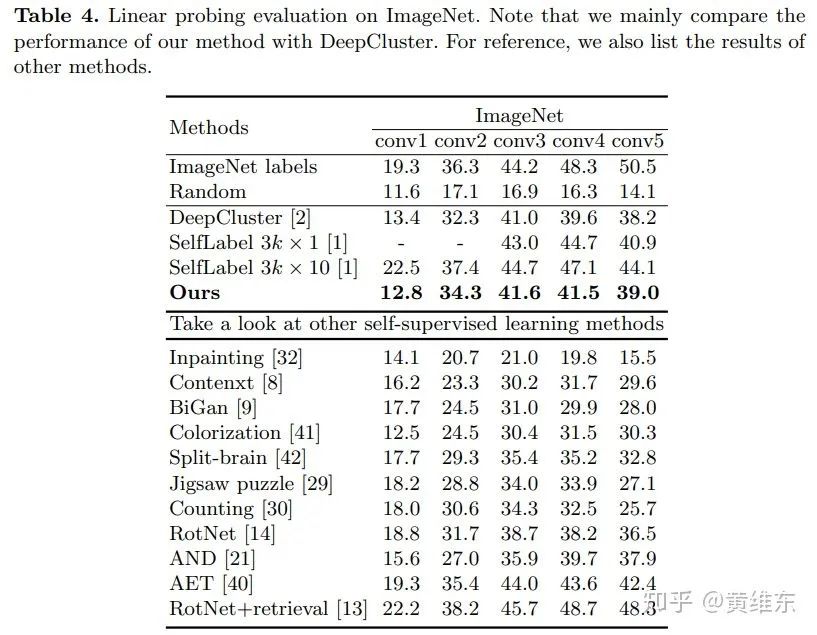
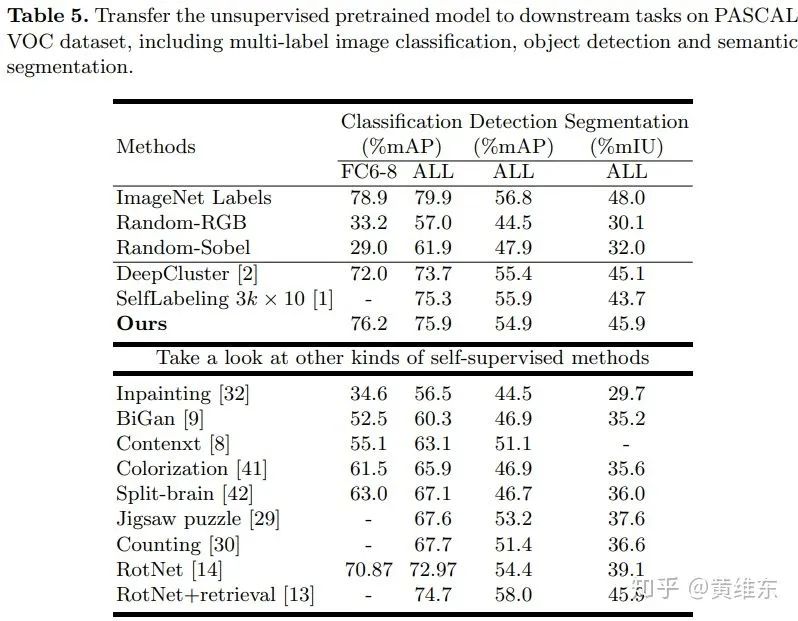
然后文章在transfer to downstream task上面做了实验对比,比如说在一些图像分类、检测和分割场景上面使用fine tuning来对比效果,可以看到和clustering的方法效果差不多,比self-supervised的方法要好很多
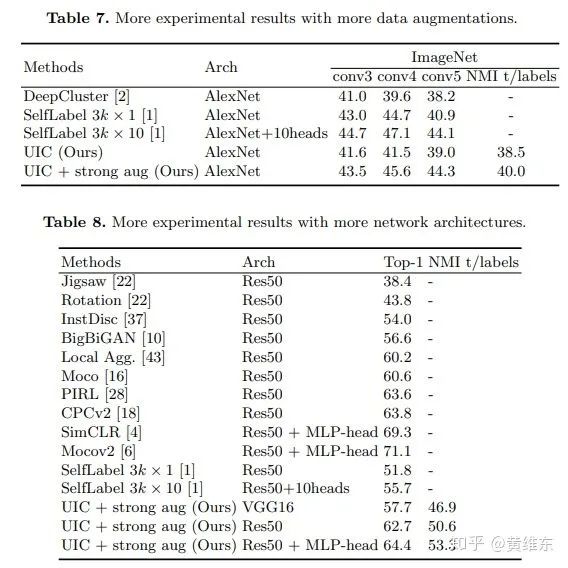
最后文章和deep cluster还做了一些更深入的实验对比,比如说做更多的数据增强,采用其他网络结构,这里提下在table8中比simCLR和MoCov2效果还是要差,但是文章强调了下simCLR和MoCov2需要训练轮数>>500epochs,计算复杂度较大,所以效果不如他,后面又解释了下,说如果自己训练更久,做更多数据增量以及多多调参应该也可以继续提升的。
下载
在CVer公众号后台回复:CVPR2020,即可下载CVPR2020 2020代码开源的论文合集
在CVer公众号后台回复:ECCV2020,即可下载ECCV 2020代码开源的论文合集
重磅!CVer-无监督&弱监督交流群成立
扫码添加CVer助手,可申请加入CVer-无监督&弱监督 微信交流群,旨在交流无监督、弱监督、半监督、自监督等方向。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如无监督+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
整理不易,请给CVer点赞和在看!


