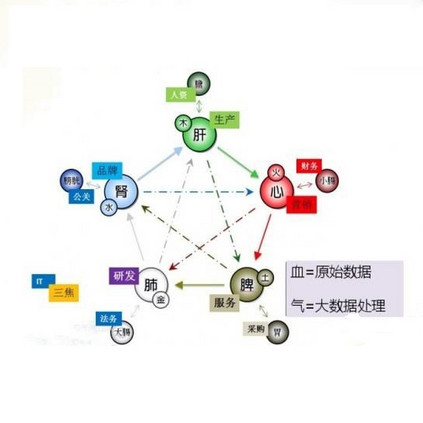
云大数据和计算技术周报(第43期)
本期会给大家奉献上精彩的:大数据处理过程与模式、卷积神经网络、Apache Flink、Kylin的Cube、HBase、列式存储。全是干货,希望大家喜欢!!!
#大数据和云计算技术社区#希望通过坚持定期分享能帮助同学在大数据学习道路上尽一份微博之力。相信长期坚持认真阅读周报的同学,在技术的道路上一定会日益精进!感谢编辑们的长期坚持!也请同学们继续打赏,支持社区,支持编辑们持续奉献高质量知识!
#大数据和云计算技术社区#长期招募有兴趣参与社区编辑和运营的同学,欢迎扫描文末二维码联系(参与社区工作,收获知识和进步,还有红包哦)。
特别提醒,文末有惊喜!
以下是正文,限于众编辑水平有限,不保证大家都喜欢。
在当前这个数据爆炸的时代,随着ICT技术的不断发展和进步,大数据已经不简简单单是数据量大,而是对大量数据的分析,只有通过分析才能获取更多智能的、深入的、有价值的信息。
https://mp.weixin.qq.com/s/_a2WJWg2ZizMNwOZI91UHQ

CNN(卷积神经网络)算法的核心其实还是BP(误差反向传播)算法,不同传统BP各层直接大多采用全连接,CNN一般有输入层,卷积层,激励函数,池化层,全连接层。理论上这些层可以组合,例如可以有多个池化或者全连接等。这篇文章讲清楚了基本的算法原理,值得一看。我用MNIST数据集做过实验,基本上对手写数字的识别可以达到98.5%以上,识别不对的基本肉眼也可能会出错。至于CNN为什么这么厉害,讲真,我还没有搞清楚,但是它就是这么厉害。
https://mp.weixin.qq.com/s/3DmZ19FJvsKVcknepfN2_w

本文将深入分析Flink的一些关键技术与特性,希望能够帮助读者对Flink有更加深入的了解,对其他大数据系统开发者也能有所裨益。
https://mp.weixin.qq.com/s/ppuRyUylRi6UvIiXNg5-DA

在众多SQL On Hadoop的解决方案中,Kylin采用了Cube的思路来加速多维分析型查询,Cube是传统数据仓库常用的一种技术,本文简单讨论Kylin多维分析的原理以及Kylin的缺点。
https://mp.weixin.qq.com/s/Wz4ggtO-gTEziBA19dfhcw

本文首先介绍了HBase 与传统关系数据库的区别,接着从功能模块以及内部架构方面介绍了HBase运行机制,最后告诉我们HBase实际应用场景以及如何通过Phoenix实现对HBase的SQL查询,深入浅出地透析了HBase内部之美。
https://www.ibm.com/developerworks/cn/analytics/library/ba-cn-bigdata-hbase/index.html

列式存储的优势一方面体现在存储上能节约空间、减少 IO,另一方面依靠列式数据结构做了计算上的优化。本文将着重介绍列式存储的数据组织方式,包括数据的布局、编码、压缩等。
https://mp.weixin.qq.com/s/AazI239iJfIKKV6BppTblw

中国建设银行(CBC):"存不存?"
中国银行(BC):" 不存!"
中国农业银行(ABC):"啊?不存?"
中国工商银行(ICBC):"爱存不存!"
民生银行(CMSB):"存嘛,傻B! "
招行银行(CMBC):"存嘛,白痴 !"
国家开发银行(CDB):"存点吧!”
兴业银行(CIB):"存一百!"
北京市商业银行(BCCB):"白存,存不?"
汇丰银行(HSBC):"还是不存!”
邮储银行(PSBC):怕死别存!
亲,你在哪家存?

致谢:
魏宏斌、薛述强、刘彬、刘超、廖程鹏、董言、吕西金、朱洁、蓝随、黄文辉

猜你喜欢
加入技术讨论群
《大数据和云计算技术》社区群人数已经3000+,欢迎大家加下面助手微信,拉大家进群,自由交流。

喜欢QQ群的,可以扫描下面二维码:
欢迎大家通过二维码打赏支持技术社区(英雄请留名,社区感谢您,打赏次数超过108+):