FaceBook at KDD 2020, 提出AutoCTR解决点击率预估中的网络结构自动寻优问题

导读:今天分享一下FaceBook在KDD 2020上的一篇关于推荐CTR预估中特征交互网络结构的自动寻优问题,推荐一读。

论文:Towards Automated Neural Interaction Discovery for Click-Through Rate Prediction
地址:https://arxiv.org/abs/2007.06434
摘要
CTR预估是推荐系统中一个非常重要的任务,同时NAS技术在发掘高效的神经网络结构上已经证实了它的能力,因此本文期待使用NAS在CTR预估任务上也能发挥它的潜在能力。由于1)多样的非结构化特征交互、2)异构的特征空间、3)超大规模的数据以及数据内在的随机性,使得我们想要构造、寻找以及对比多种网络结构的想法变得异常困难。
为了解决上述问题,本文提出了AutoCTR的框架,通过将简单有效的表示交互模块化为组件,并将这些组件放入一个有向无环图的空间中,AutoCTR可以自动探索、学习到最有效的网络交互结构。我们在多个离线数据集上验证了AutoCTR相对于人工设计的网络结构的有效性,并且在多个数据集之间有一定的泛化与迁移能力。
背景
CTR预估当中深度神经网络的设计,传统的做法是花很大的精力在设计显式地特征交互模块,然后将它与隐式的特征交互学习模块MLP组合成为最终的模型。但是除了简单粗暴的堆砌策略,如何更有效地联合学习显式和隐式的特征交互仍然是一个未被解决的问题。譬如说,已有的工作显示钻石的MLP结构可能会比三角形或者矩形形状的MLP结构更高效。这就促使我们去探索更具体适用的MLP结构来获得更强大的隐式交互学习能力。
神经网络结构搜索(NAS)技术在CV和NLP领域得到了广泛应用,它可以通过数据驱动的方式自动发现最优的深度学习网络结构。但是,在CTR任务上使用NAS在寻找最优的网络结构面临着比较大的挑战。首先,CTR任务中的特征通常是异构的、高维稀疏的非结构化数据;其次,CTR任务当中的网络结构子单元也是多样而且无规律的,导致了网络结构的搜索空间也是非结构化的;然后,工业界的CTR任务往往是数以十亿计的训练数据,要求了NAS的搜索过程是时间与空间复杂度上是高效的;最后,CTR任务当中不同的网络结构在实际结果上可能非常相近,因此要求NAS过程需要足够敏感和有区分度。
为了解决上述问题,本文提出了AutoCTR的框架来自动探索发现CTR预估任务中最优的神经网络结构。本文的主要贡献点如下:
通过抽象总结了CTR预估任务中通常使用的操作,设计了虚拟积木以及一个层级化的搜索空间;
提出了一个learning-to-rank的策略来处理不同的搜索目标之间的平衡,包括时效性、准确性以及网络结构的复杂度;
进一步地通过譬如降维预估等一系列的组合策略提升了网络结构搜索的速度;
层级化搜索空间设计
一个理想的搜索空间需要包含足够的不同的网络结构同时能够包含所有人工设计的网络结构。我们设计了一个里、外两级的层级化的搜索空间,通过抽象、总结了现有人工设计的CTR预估任务中的表示结构为虚拟积木,并且将它们改造成一个有向无环图。里层的搜索空间由超参积木构成,譬如MLP中的节点数、层数等;外层的搜索空间则是积木之间如何进行连接。
如下图所示是设计的搜索空间的一个概要示意图。假设稠密特征是一个拼接起来的向量,稀疏特征是通过Embedding表查找后的低维矩阵。积木会连接起来构成一个有向无环图,并且每一个积木都可以使用原始特征输入以及前面积木的输出。最终的积木是一个线性变换,同样它也可以使用所有的原始特征输入以及前面积木的输出。值得注意的是,为了简化搜索空间我们没有考虑相对没那么重要的超参,譬如稀疏特征的Hash尺寸、稀疏特征的Embedding大小以及其他诸如优化器等训练方面的超参。
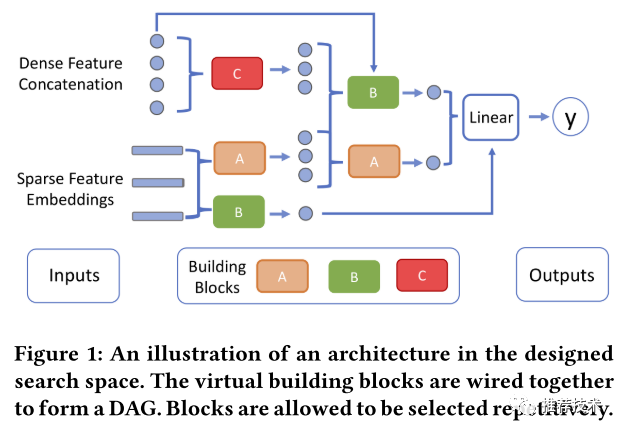
虚拟积木抽象化
我们在抽象构建虚拟积木时候的考虑,一方面是功能性上各个积木需要互补,并且能接受包含稠密与稀疏特征的输入;另外一方面是计算复杂度上要简单。因此我们设计了诸如MLP、点积DP、FM、外积以及自注意力等积木,本文我们将主要介绍MLP、DP、FM三种积木的构建与适配,其他类型的抽象积木则还有待更多的探索。
搜索模块
在AutoCTR的层次化搜索空间中主要包含如下的几个部分:
积木类型:MLP、FM以及DP;
原始输入特征的选择:每一个积木都可以针对原始输入特征进行四种可能的选择(仅稠密特征、仅稀疏特征、都选以及都不选);
积木之间的连接:每一个积木都可以接受在它之前的任意积木的输出;
积木补充超参:本文中我们只考虑了MLP的隐层节点数量。
为了方便引入不同的搜索算法,我们将积木的构建进行向量化。每一个积木都被表示为四维的向量:[积木类型,原始输入特征选择,积木之间的连接,积木补充超参]。其中积木类型与原始输入特征选择是one-hot编码向量,积木之间的是multi-hot编码向量,积木补充超参是数字。可以看出这样的搜索空间设计可以包含大量的不同结构的可能性,同时它能够覆盖多种之前人工设计的CTR预估结构譬如DeepFM、DLRM、IPNN以及WDL等。
多目标进化搜索算法
本文使用的搜索算法实际上是进化算法与learning-to-rank的一个融合。选择进化算法是因为它足够简单,并且可以有效地平衡探索与利用(EE)。搜索过程里的循环可以分为三阶段:父结构选取、引导变换以及幸存节点选取,如下图所示。在每一次循环当中,我们借助基于排序的特征来进行幸存者选取来更新新一轮固定数量的候选集;然后,我们根据设计好的离散概率分布选取父类结构;最后,根据选取的父类结构通过变化产生一系列的邻居节点并引入一个learning-to-rank的机制来选取生成的邻居节点中最合适的。
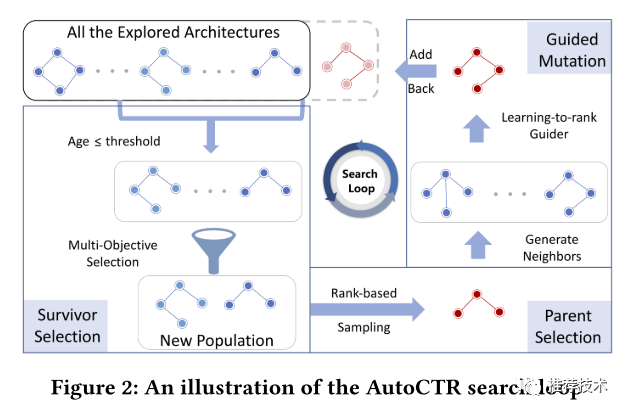
多目标幸存者选择
为了保持相当数量的多样化网络结构,本文设计了一个幸存者选择指标 f 来衡量网络结构的幸存值,主要考虑fitness、age和模型复杂度。“fitness” 这里指的是探索到的结构的表现,用来保证探索能力;“age” 反映的则是结构探索次序;模型复杂度则主要是为了限制整体的计算复杂度。
基于排序的父结构选择
父结构选择的目的是为了从幸存者选择步骤之后的挑选。本文引入设计了一个基于旅行者算法的排序算法。主要基于如下的考虑:
CTR预测任务中的不同网络结构在logloss或者AUC的指标表现上经常非常接近,而且在不同数据集上的表现也差异很大;
已有的工作已经证实了排序和旅行者算法在敏感性和多样性方面的有效性;
传统的旅行者算法通常是先随机选择固定数量的候选集然后再从中挑选最好的,这可能存在一定的问题导致有一些候选集完全没有机会被选择为父结构。
引导变化
当父结构选定后,最后一步便是基于父结构探索衍生出一系列的后代。一个比较简单的办法就是选定父结构后随机地选择和修改里面的组件。现有的工作已经证明了基于学习的排序算法在引导变化过程中的高效,本文提出了一个叫做Learning-to-Hyperrank的算法流程:
首先,基于已有探索的数据训练一个引导变化模型;
其次,围绕父结构随机生成一系列的邻居作为后代候选结构;
最后,使用引导变化模型挑选出最好的作为后代结构。
性能加速
NAS中最严峻的挑战实际上是网络训练的高时间复杂度,Low-fidelity性能预估与参数继承是常见的两种加速的办法但是也会有可能引入额外的bias,因此本文针对CTR预估上的性能加速也提出了一系列的策略,譬如数据降采样、减少Hash大小以及热启动Embedding等。
实验结果
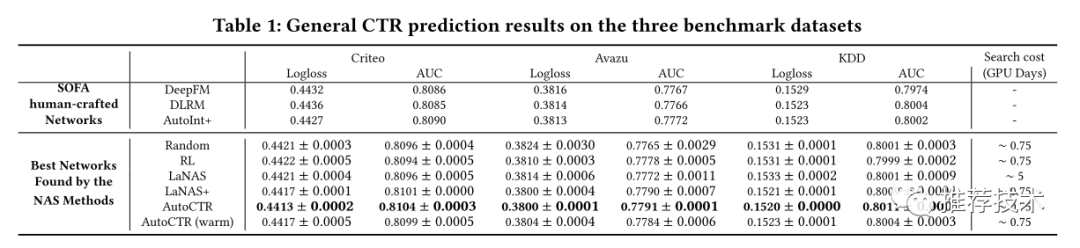
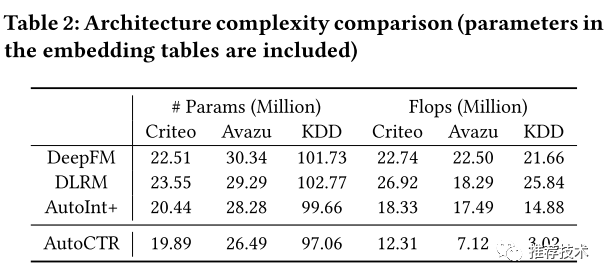
实验结果不用多解释,在多项数据集上可以达到效果最好的同时最节省网络参数量。
参考文献
1. Towards Automated Neural Interaction Discovery for Click-Through Rate Prediction
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏