【EMNLP2020】一种多层对多层的BERT蒸馏方法
点击上方,选择星标或置顶,每天给你送干货
阅读大概需要8分钟
跟随小博主,每天进步一丢丢


日前,神州泰岳AI研究院与中科院深圳先进技术研究院合作推出的“BERT-EMD一种蒸馏BERT的方法”被自然语言处理(NLP)方向的国际学术会议EMNLP 2020收录。

一年一度的全球学术大会EMNLP是计算机语言学和自然语言处理领域最受关注的国际学术会议之一,由国际语言学会(ACL)旗下SIGDAT组织。其中,会议涵盖的语义理解、文本理解、信息提取、信息检索和机器翻译等多项技术主题,是当今学术界和工业界备受关注的热点方向。据悉,EMNLP 2020共收到有效投稿3114篇,录用754篇,录用率为24.82%。在即将召开的EMNLP学术会议上将展示自然语言处理领域的前沿研究成果,这些成果也将代表着相关领域和技术细分中的研究水平以及未来发展方向。
由神州泰岳AI研究院与中科院深圳先进技术研究院合作推出的BERT-EMD相较于以前工作蒸馏BERT的方式,有效地解决了人工指定蒸馏学习层次对应关系的弊端,在GLUE Benckmark上,我们提出的知识蒸馏的方法不使用数据增强技术,6层模型有着12层BERT相当的结果,另外我们的方法不需要研究者手动指定层次映射关系,目前在GLUE Benckmark已超过其他蒸馏模型(如TinyBERT, BERT-PKD等)。下文中梳理了 BERT-EMD的压缩方法。
论文链接:https://arxiv.org/abs/2010.06133
代码:https://github.com/lxk00/BERT-EMD
正文
BERT-EMD
借助EMD实现多对多层映射的BERT压缩方法
简介 …
在 NLP 领域,BERT一经出现就吸引了所有人的目光。此后根据BERT推出了 XLNET、RoBERTa、ALBERT、T5、Megatron-LM、Turning-NLP 等性能卓越的改进模型。但是这些模型体积愈发庞大,从 BERT-large 的 3.4 亿参数到 Turing-NLP 参数规模的 170 亿参数。单个样本计算一次的开销动辄上百毫秒,很难应用到实际生产中。BERT蒸馏技术应运而生,解决了模型大小和推理速度的问题,而且使用该技术的模型大小并没有明显的下降。
近一年来,知识蒸馏(Knowledge Distillation)作为一种常用的模型压缩方法逐渐成为BERT蒸馏的研究热点分支。最初针对BERT模型的蒸馏学习是利用教师和学生网络的输出logits计算蒸馏损失,然而这样不能学到Transformer 中间层的信息。随后的研究通过对教师 BERT 模型中所有Transformer层的first token,attention,hidden parameter输出等进行蒸馏,将大 BERT 的中间层信息迁移到小模型上,学习到的学生模型有了更好的表现。这种方法最近也成为了BERT蒸馏的主流方法。包括PKD-BERT到TinyBERT,MobileBERT,都是采用指定层对应学习的方式进行蒸馏。
然而为了压缩模型大小,学生模型的层次数量一般小于教师BERT模型的层次数量,因此中间层的学习不能做到层次一一对应。目前的BERT蒸馏方法均使用跨层映射的方法(Skip),其层次映射函数为, 其中为教师,学生模型的指定层次,为教师,学生模型的层数。举例而言,如果教师模型有12层,对应的学生模型有4层,具体对应为 student 第 1 层 transformer 对应 teacher 第 3 层,第 2 层对应第 6 层,第 3 层对应第 9 层,第 4 层对应第 12 层。
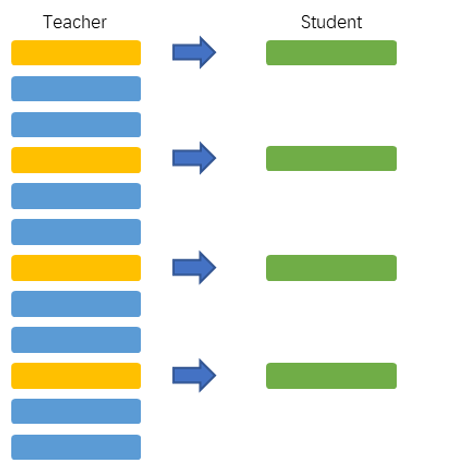
图 1 跨层映射策略
该指定方法获得了不错的效果,但存在如下问题:该蒸馏过程中部分层次的信息必然被舍弃。不同任务可能需要学习不同层次的知识,这种强制指定不一定适应所有任务。
我们的方法解决了这两个问题,无需进行层次对应指定,且能够实现多层对多层的蒸馏学习。我们的主要贡献如下:
1.我们提出了先进的多层对多层的BERT蒸馏方法,BERT的中间层以自适应和整体的方式进行学习;
2.我们引入EMD方法衡量学生模型和教师模型之间的差异;
3.我们提出了一种Cost Attention 机制,在蒸馏学习中建模不同隐含层的重要程度;
4.在GLUE任务上进行的大量实验表明,BERT-EMD的性能优于最新的BERT蒸馏方法。
模型实现细节 …
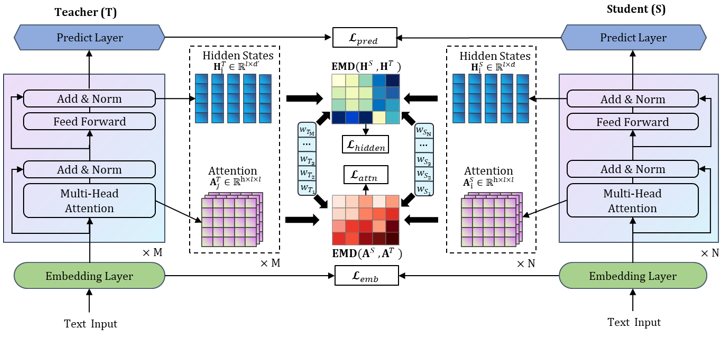
图 2 模型
与TinyBERT类似,我们的方法同样包括logits,hidden parameter,embedding和attention的蒸馏。下面我们分别介绍:


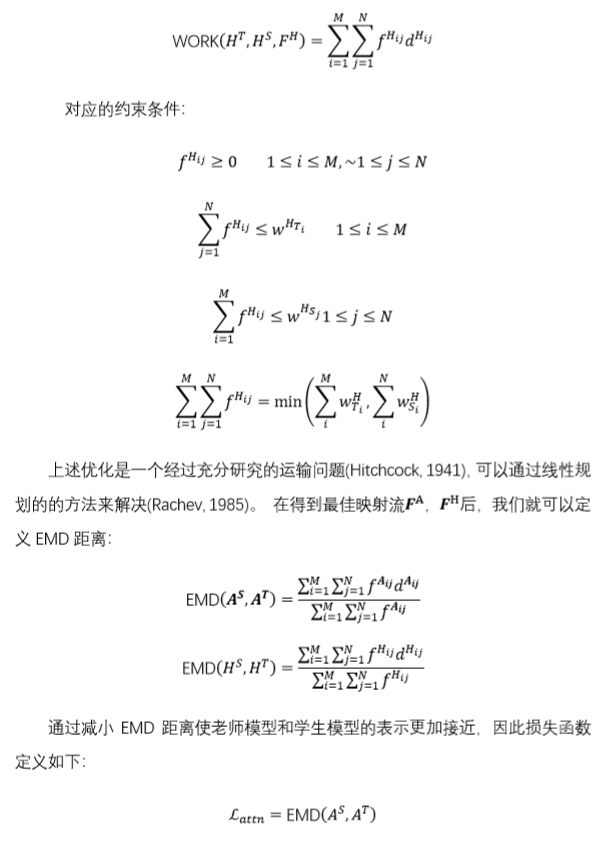


实验结果 …
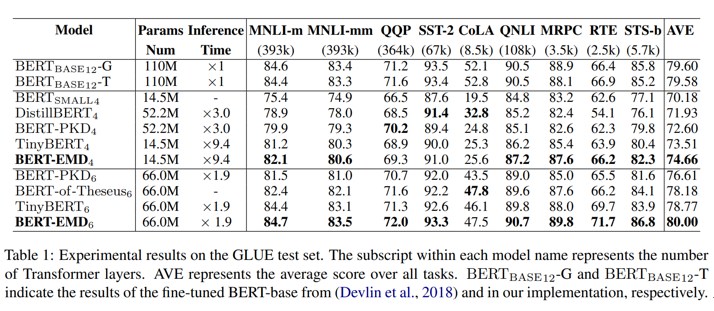
我们对比了BERT Small,DistillBERT,BERT-PKD,TinyBERT,可以看到4层和6层的BERT-EMD均好于这些压缩方法。在未引入数据增强的情况下,6层的BERT-EMD甚至MNLI,QQP,QNLI,MRPC,RTE,STS-b这几个数据集上超过了BERT-base,同时比BERT-base快约一倍。
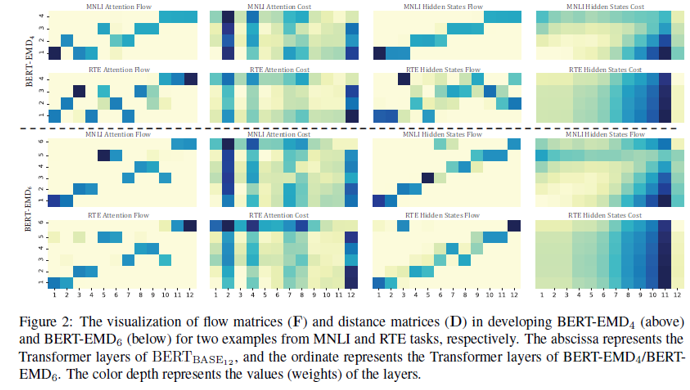
根据图2的结果,我们有几个关键的观察结果。首先,在压缩Transformer时,不同的任务可能会更倾向于不同的教师层。矩阵的对角线位置对于MNLI任务几乎总是很重要的,它与传统跳层的映射策略呈现相似的趋势。但是,对于RTE任务,每个学生Transformer层都可以向任何教师Transformer层学习。先前的映射方法无法充分利用教师网络。另外从结果中也可以看出,BERT-EMD在RTE数据集上的提升比MNLI要大。
团队介绍 …
杨敏,中国科学院深圳先进技术研究院副研究员(博士生导师),中科院深圳先进院得理法律人工智能联合实验室主任,中国科学院青年创新促进会成员。长期从事人工智能、自然语言处理、数据挖掘相关研究并取得了一系列研究成果,在相关领域的CCF-A类国际学术会议和JCR Q1期刊上发表高水平学术论文80余篇。
李健铨、刘小康硕士毕业于天津大学量子智能与语言理解实验室,就职于神州泰岳AI研究院深度学习实验室,在自然语言处理方向合作发表论文6篇,获得AI专利授权8项,申请发明专利55项。负责研发的产品“泰岳语义工厂”获得第九届(2019)年吴文俊人工智能科技进步奖(企业技术创新工程项目)。
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套! ![]()
![]()
![]()
后台回复【五件套】
下载二:南大模式识别PPT ![]()
后台回复【南大模式识别】
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心
。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。
记得备注呦
推荐两个专辑给大家: 专辑 | 李宏毅人类语言处理2020笔记 专辑 | NLP论文解读 专辑 | 情感分析
整理不易,还望给个在看!










