手绘图解 | 机器学习最常见的30个基本概念

来源:大数据DT
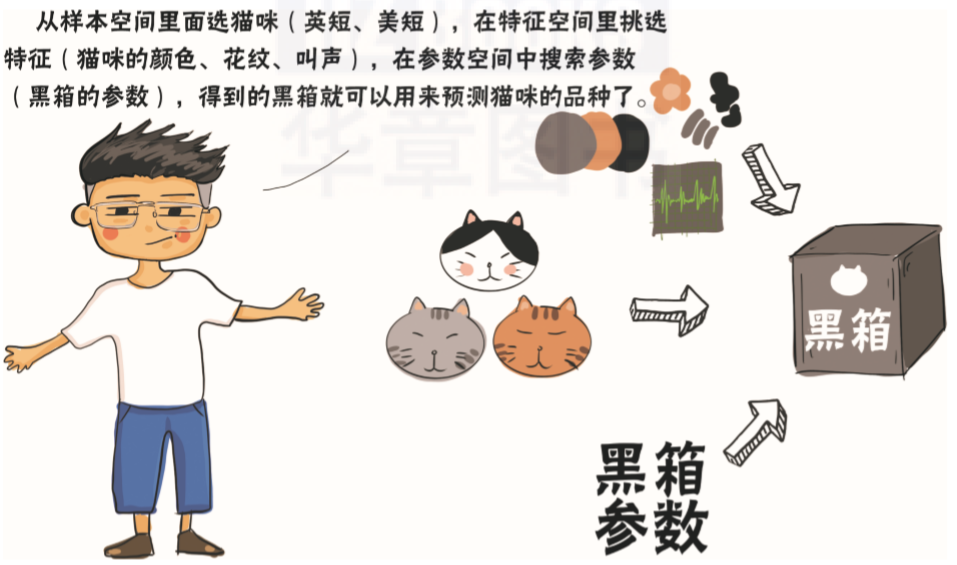
特征(Feature):一个具体事物的属性描述,由属性向量表示。第j个记录xj的属性向量可以表示为:xj=(xj(1),xj(2),…,xj(i),…,xj(n)), j=1,2,…,N, xj∈X。
其中每个xj(i)为一个特征维度上的取值。
标记(Label):又称样本标签,用于描述事物某个特性的事项。
标记值:标记的取值。在二分类问题中,取值通常为0和1。
标记空间(输出空间):所有标记的集合,记为Y。
样例(Sample):又称样本。拥有了对应标记的记录,由(记录,标记)对表示。例如,第j个样例可以表示为:(xj,yj), j=1,2,…,N, xj∈X,yj∈Y
-
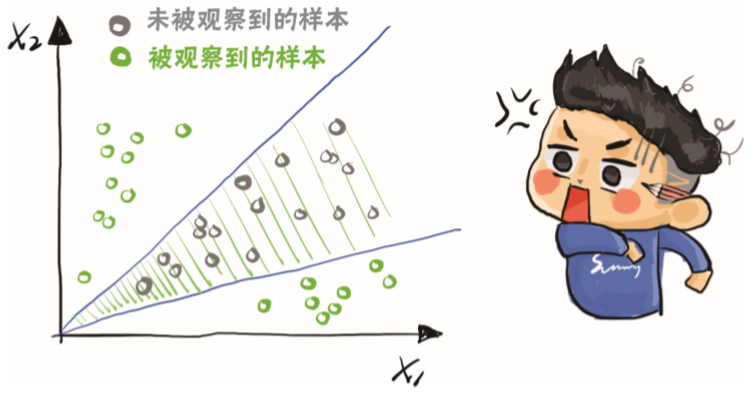
监督学习 是指在一个申请评分卡建模中,已经明确知道样本集中每个用户的标签,即随便取一个人出来,都可以知道他的逾期状态。 -
无监督学习 是指在建模时,完全没有当前样本集的任何标签信息,即完全不知道哪些人是逾期的。 -
而半监督学习介于两者之间,对于当前的样本集,知道其中一部分样本的标签,另一部分则不知道其是否已逾期。
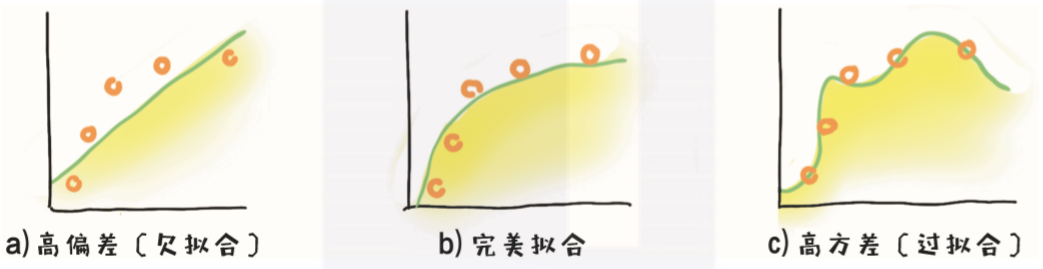
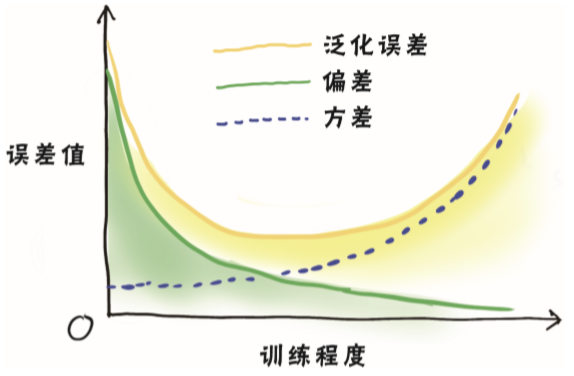
偏差度量了模型的期望预测与真实结果的偏离程度,也就是模型本身的拟合能力;
方差度量了同样大小的训练集的变动所导致的学习能力的变化,也就是数据扰动所造成的影响;
而噪声则刻画了问题本身的拟合难度。
——END——



登录查看更多
相关内容

Arxiv
3+阅读 · 2018年1月30日


相关VIP内容
相关资讯