【机器学习】想了解机器学习?这 3 种算法你必须要知道
源 | Dzone 译 | OSC
假设有一些数据相关的问题亟待你解决。在此之前你听说过机器学习算法可以帮助解决这些问题,于是你想借此机会尝试一番,却苦于在此领域没有任何经验或知识。 你开始谷歌一些术语,如“机器学习模型”和“机器学习方法论”,但一段时间后,你发现自己完全迷失在了不同算法之间,于是你准备放弃。
朋友,请坚持下去!
幸运的是,在这篇文章中我将介绍三大类的机器学习算法,针对大范围的数据科学问题,相信你都能满怀自信去解决。
在接下来的文章中,我们将讨论决策树、聚类算法和回归,指出它们之间的差异,并找出如何为你的案例选择最合适的模型。
有监督的学习 vs. 无监督的学习
理解机器学习的基础,就是要学会对有监督的学习和无监督的学习进行分类,因为机器学习中的任何一个问题,都属于这两大类的范畴。
在有监督学习的情况下,我们有一个数据集,它们将作为输入提供给一些算法。但前提是,我们已经知道正确输出的格式应该是什么样子(假设输入和输出之间存在一些关系)。
我们随后将看到的回归和分类问题都属于这个类别。
另一方面,在我们不知道输出应该是什么样子的情况下,就应该使用无监督学习。事实上,我们需要从输入变量的影响未知的数据中推导出正确的结构。聚类问题是这个类别的主要代表。
为了使上面的分类更清晰,我会列举一些实际的问题,并试着对它们进行相应的分类。
示例一
假设你在经营一家房地产公司。考虑到新房子的特性,你要根据你以前记录的其他房屋的销售量来预测它的售价是多少。你输入的数据集包括多个房子的特性,比如卫生间的数量和大小等,而你想预测的变量(通常称为“目标变量”)就是价格。预测房屋的售价是一个有监督学习问题,更确切地说,是回归问题。
示例二
假设一个医学实验的目的是预测一个人是否会因为一些体质测量和遗传导致近视程度加深。在这种情况下,输入的数据集是这个人的体质特征,而目标变量有两种:
1 表示可能加深近视,而 0 表示不太可能。预测一个人是否会加深近视也是一个有监督学习问题,更确切地说,是分类问题。
示例三
假设你的公司拥有很多客户。根据他们最近与贵公司的互动情况、他们近期购买的产品以及他们的人口统计数据,你想要形成相似顾客的群体,以便以不同的方式应对他们 - 例如向他们中的一些人提供独家折扣券。在这种情况下,你将使用上述提及的特征作为算法的输入,而算法将决定应该形成的组的数量或类别。这显然是一个无监督学习的例子,因为我们没有任何关于输出会如何的线索,完全不知道结果会怎样。
接下来,我将介绍一些更具体的算法……
回归
首先,回归不是一个单一的监督学习技术,而是一个很多技术所属的完整类别。
回归的主要思想是给定一些输入变量,我们要预测目标值。在回归的情况下,目标变量是连续的 - 这意味着它可以在指定的范围内取任何值。另一方面,输入变量可以是离散的也可以是连续的。
在回归技术中,最流行的是线性回归和逻辑回归。让我们仔细研究一下。
线性回归
在线性回归中,我们尝试在输入变量和目标变量之间构建一段关系,并将这种关系用条直线表示,我们通常将其称为回归线。
例如,假设我们有两个输入变量 X1 和 X2,还有一个目标变量 Y,它们的关系可以用数学公式表示如下:
Y = a * X1 + b*X2 +c
假设 X1 和 X2 的值已知,我们需要将 a,b 和 c 进行调整,从而使 Y 能尽可能的接近真实值。
举个例子!
假设我们拥有著名的 Iris 数据集,它提供了一些方法,能通过花朵的花萼大小以及花瓣大小判断花朵的类别,如:Setosa,Versicolor 和 Virginica。
使用 R 软件,假设花瓣的宽度和长度已给定,我们将实施线性回归来预测萼片的长度。
在数学上,我们会通过以下公式来获取 a、b 值:
SepalLength = a * PetalWidth + b* PetalLength +c
相应的代码如下所示:
# Load required packageslibrary(ggplot2)# Load iris datasetdata(iris)# Have a look at the first 10 observations of the datasethead(iris)# Fit the regression linefitted_model <- lm(Sepal.Length ~ Petal.Width + Petal.Length, data = iris)# Get details about the parameters of the selected modelsummary(fitted_model)# Plot the data points along with the regression line ggplot(iris, aes(x = Petal.Width, y = Petal.Length, color = Species)) + geom_point(alpha = 6/10) + stat_smooth(method = "lm", fill="blue", colour="grey50", size=0.5, alpha = 0.1)
线性回归的结果显示在下列图表中,其中黑点表示初始数据点,蓝线表示拟合回归直线,由此得出估算值:a= -0.31955,b = 0.54178 和 c = 4.19058,这个结果可能最接近实际值,即花萼的真实长度。
接下来,只要将花瓣长度和花瓣宽度的值应用到定义的线性关系中,就可以对花萼长度进行预测了。

逻辑回归
主要思想与线性回归完全相同。不同点是逻辑回归的回归线不再是直的。
我们要建立的数学关系是以下形式的:
Y=g(a*X1+b*X2)
g() 是一个对数函数。
根据该逻辑函数的性质,Y 是连续的,范围是 [0,1],可以被解释为一个事件发生的概率。
再举个例子!
这一次我们研究 mtcars 数据集,包含 1973-1974 年间 32 种汽车制造的汽车设计、十个性能指标以及油耗。
使用 R,我们将在测量 V/S 和每英里油耗的基础上预测汽车的变速器是自动(AM = 0)还是手动(AM = 1)的概率。
am = g(a * mpg + b* vs +c):
# Load required packageslibrary(ggplot2)# Load datadata(mtcars)# Keep a subset of the data features that includes on the measurement we are interested incars <- subset(mtcars, select=c(mpg, am, vs))# Fit the logistic regression linefitted_model <- glm(am ~ mpg+vs, data=cars, family=binomial(link="logit"))# Plot the resultsggplot(cars, aes(x=mpg, y=vs, colour = am)) + geom_point(alpha = 6/10) + stat_smooth(method="glm",fill="blue", colour="grey50", size=0.5, alpha = 0.1, method.args=list(family="binomial"))
如下图所示,其中黑点代表数据集的初始点,蓝线代表闭合的对数回归线。估计 a = 0.5359,b = -2.7957,c = - 9.9183
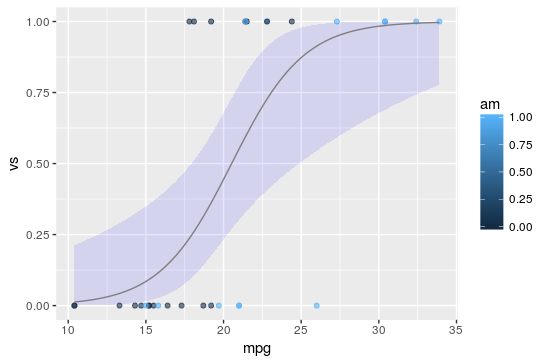
我们可以观察到,和线性回归一样,对数回归的输出值回归线也在区间 [0,1] 内。
对于任何新汽车的测量 V/S 和每英里油耗,我们可以预测这辆汽车将使用自动变速器。这是不是准确得吓人?
决策树
决策树是我们要研究的第二种机器学习算法。它们被分成回归树和分类树,因此可以用于监督式学习问题。
无可否认,决策树是最直观的算法之一,因为它们模仿人们在多数情况下的决策方式。他们基本上做的是在每种情况下绘制所有可能路径的“地图”,并给出相应的结果。
图形表示有助于更好地理解我们正在探讨的内容。

基于像上面这样的树,该算法可以根据相应标准中的值来决定在每个步骤要采用的路径。算法所选择的划分标准以及每个级别的相应阈值的策略,取决于候选变量对于目标变量的信息量多少,以及哪个设置可以最小化所产生的预测误差。
再举一个例子!
这次测验的数据集是 readingSkills。它包含学生的考试信息及考试分数。
我们将基于多重指标把学生分为两类,说母语者(nativeSpeaker = 1)或外国人(nativeSpeaker= 0),他们的考试分数、鞋码以及年龄都在指标范围内。
对于 R 中的实现,我们首先要安装 party 包:
# Include required packageslibrary(party) library(partykit)# Have a look at the first ten observations of the datasetprint(head(readingSkills)) input.dat <- readingSkills[c(1:105),]# Grow the decision treeoutput.tree <- ctree( nativeSpeaker ~ age + shoeSize + score, data = input.dat)# Plot the resultsplot(as.simpleparty(output.tree))
我们可以看到,它使用的第一个分类标准是分数,因为它对于目标变量的预测非常重要,鞋码则不在考虑的范围内,因为它没有提供任何与语言相关的有用的信息。

现在,如果我们多了一群新生,并且知道他们的年龄和考试分数,我们就可以预测他们是不是说母语的人。
聚类算法
到目前为止,我们都在讨论有监督学习的有关问题。现在,我们要继续研究聚类算法,它是无监督学习方法的子集。
因此,只做了一点改动......
说到聚类,如果我们有一些初始数据需要支配,我们会想建立一个组,这样一来,其中一些组的数据点就是相同的,并且能与其他组的数据点区分开来。
我们将要学习的算法叫做 K-均值聚类(K-Means Clustering),也可以叫 K-Means 聚类,其中 k 表示产生的聚类的数量,这是最流行的聚类算法之一。
还记得我们前面用到的 Iris 数据集吗?这里我们将再次用到。
为了更好地研究,我们使用花瓣测量方法绘制出数据集的所有数据点,如图所示:

仅仅基于花瓣的度量值,我们使用 3-均值聚类将数据点聚集成三组。
那么3-均值,或更普遍来说,k-聚类算法是怎样工作的呢?整个过程可以概括为几个简单的步骤:
初始化步骤:例如 K = 3 簇,这个算法为每个聚类中心随机选择三个数据点。
群集分配步骤:该算法通过其余的数据点,并将其中的每一个分配给最近的群集。
重心移动步骤:在集群分配后,每个簇的质心移动到属于组的所有点的平均值。
步骤 2 和 3 重复多次,直到没有对集群分配作出更改为止。用 R 实现 k-聚类算法很简单,可以用下面的代码完成:
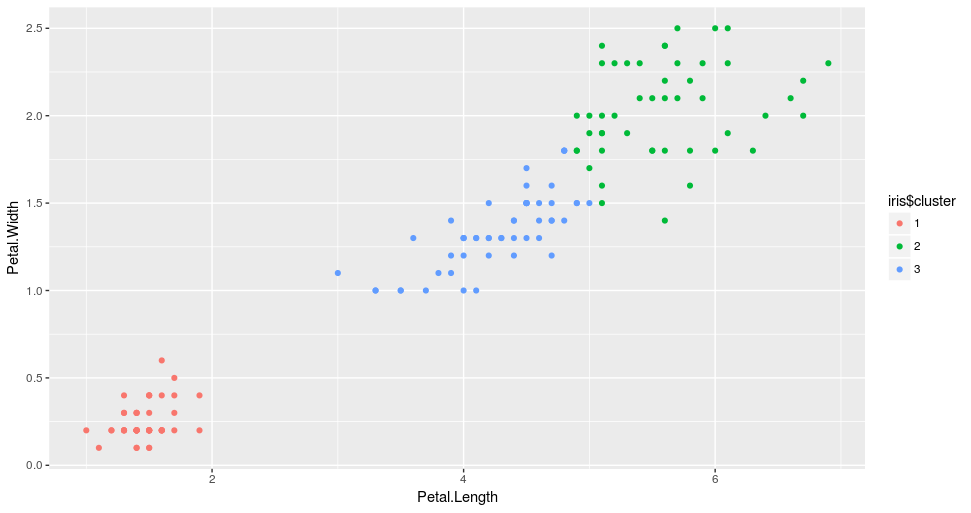
# Load required packageslibrary(ggplot2) library(datasets)# Load datadata(iris)# Set seed to make results reproducibleset.seed(20)# Implement k-means with 3 clustersiris_cl <- kmeans(iris[, 3:4], 3, nstart = 20) iris_cl$cluster <- as.factor(iris_cl$cluster)# Plot points colored by predicted clusterggplot(iris, aes(Petal.Length, Petal.Width, color = iris_cl$cluster)) + geom_point()
从结果中,我们可以看到,该算法将数据分成三个组,由三种不同的颜色表示。我们也可以观察到这三个组是根据花瓣的大小分的。更具体地说,红点代表小花瓣的花,绿点代表大花瓣的花,蓝点代表中等大小的花瓣的花。
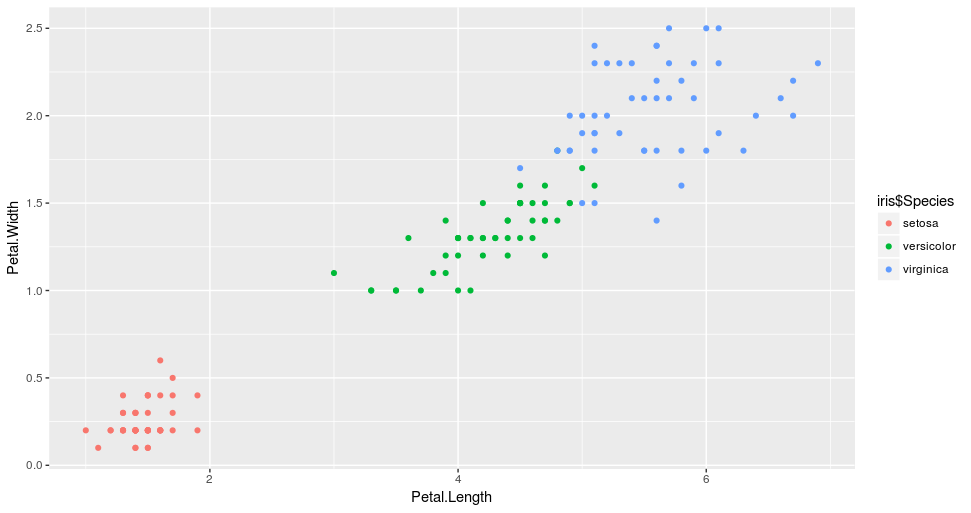
因此,如果我们再次绘制数据,这一次由它们的物种着色,我们将看到集群中的相似性。
总结
我们从一开始就走了很长的路。我们已经谈到回归(线性和逻辑)、决策树,以及最后的 K-均值聚类。我们还在R中为其中的每一个方法建立了一些简单而强大的实现。
那么,每种算法的优势是什么呢? 在处理现实生活中的问题时你该选择哪一个呢?
首先,这里所提出的方法都是在实际操作中被验证为行之有效的算法 - 它们在世界各地的产品系统中被广泛使用,所以根据任务情况选用,能发挥十分强大的作用。
其次,为了回答上述问题,你必须明确你所说的优势究竟意味着什么,因为每个方法的相对优势在不同情况下的呈现不同,比如可解释性、鲁棒性、计算时间等等。
在目前只考虑方法的适当性和预测性能情况下,对每种方法的优缺点进行简简单的总结:
方法 |
输出变量 |
优点 |
缺点 |
线性回归 |
连续 |
|
|
逻辑回归 |
区间 [0,1] 内连续 |
|
|
决策树 |
连续或离散 |
|
|
k-均值 |
离散 |
|
|
现在,我们终于有信心将这些知识落实到一些现实问题中了!
-END-
转载声明:本文转载自开源中国,由Tocy、东风玖哥、达尔文协作翻译

人工智能赛博物理操作系统
AI-CPS OS
“人工智能赛博物理操作系统”(新一代技术+商业操作系统“AI-CPS OS”:云计算+大数据+物联网+区块链+人工智能)分支用来的今天,企业领导者必须了解如何将“技术”全面渗入整个公司、产品等“商业”场景中,利用AI-CPS OS形成数字化+智能化力量,实现行业的重新布局、企业的重新构建和自我的焕然新生。
AI-CPS OS的真正价值并不来自构成技术或功能,而是要以一种传递独特竞争优势的方式将自动化+信息化、智造+产品+服务和数据+分析一体化,这种整合方式能够释放新的业务和运营模式。如果不能实现跨功能的更大规模融合,没有颠覆现状的意愿,这些将不可能实现。
领导者无法依靠某种单一战略方法来应对多维度的数字化变革。面对新一代技术+商业操作系统AI-CPS OS颠覆性的数字化+智能化力量,领导者必须在行业、企业与个人这三个层面都保持领先地位:
重新行业布局:你的世界观要怎样改变才算足够?你必须对行业典范进行怎样的反思?
重新构建企业:你的企业需要做出什么样的变化?你准备如何重新定义你的公司?
重新打造自己:你需要成为怎样的人?要重塑自己并在数字化+智能化时代保有领先地位,你必须如何去做?
AI-CPS OS是数字化智能化创新平台,设计思路是将大数据、物联网、区块链和人工智能等无缝整合在云端,可以帮助企业将创新成果融入自身业务体系,实现各个前沿技术在云端的优势协同。AI-CPS OS形成的数字化+智能化力量与行业、企业及个人三个层面的交叉,形成了领导力模式,使数字化融入到领导者所在企业与领导方式的核心位置:
精细:这种力量能够使人在更加真实、细致的层面观察与感知现实世界和数字化世界正在发生的一切,进而理解和更加精细地进行产品个性化控制、微观业务场景事件和结果控制。
智能:模型随着时间(数据)的变化而变化,整个系统就具备了智能(自学习)的能力。
高效:企业需要建立实时或者准实时的数据采集传输、模型预测和响应决策能力,这样智能就从批量性、阶段性的行为变成一个可以实时触达的行为。
不确定性:数字化变更颠覆和改变了领导者曾经仰仗的思维方式、结构和实践经验,其结果就是形成了复合不确定性这种颠覆性力量。主要的不确定性蕴含于三个领域:技术、文化、制度。
边界模糊:数字世界与现实世界的不断融合成CPS不仅让人们所知行业的核心产品、经济学定理和可能性都产生了变化,还模糊了不同行业间的界限。这种效应正在向生态系统、企业、客户、产品快速蔓延。
AI-CPS OS形成的数字化+智能化力量通过三个方式激发经济增长:
创造虚拟劳动力,承担需要适应性和敏捷性的复杂任务,即“智能自动化”,以区别于传统的自动化解决方案;
对现有劳动力和实物资产进行有利的补充和提升,提高资本效率;
人工智能的普及,将推动多行业的相关创新,开辟崭新的经济增长空间。
给决策制定者和商业领袖的建议:
超越自动化,开启新创新模式:利用具有自主学习和自我控制能力的动态机器智能,为企业创造新商机;
迎接新一代信息技术,迎接人工智能:无缝整合人类智慧与机器智能,重新
评估未来的知识和技能类型;
制定道德规范:切实为人工智能生态系统制定道德准则,并在智能机器的开
发过程中确定更加明晰的标准和最佳实践;
重视再分配效应:对人工智能可能带来的冲击做好准备,制定战略帮助面临
较高失业风险的人群;
开发数字化+智能化企业所需新能力:员工团队需要积极掌握判断、沟通及想象力和创造力等人类所特有的重要能力。对于中国企业来说,创造兼具包容性和多样性的文化也非常重要。
子曰:“君子和而不同,小人同而不和。” 《论语·子路》云计算、大数据、物联网、区块链和 人工智能,像君子一般融合,一起体现科技就是生产力。
如果说上一次哥伦布地理大发现,拓展的是人类的物理空间。那么这一次地理大发现,拓展的就是人们的数字空间。在数学空间,建立新的商业文明,从而发现新的创富模式,为人类社会带来新的财富空间。云计算,大数据、物联网和区块链,是进入这个数字空间的船,而人工智能就是那船上的帆,哥伦布之帆!
新一代技术+商业的人工智能赛博物理操作系统AI-CPS OS作为新一轮产业变革的核心驱动力,将进一步释放历次科技革命和产业变革积蓄的巨大能量,并创造新的强大引擎。重构生产、分配、交换、消费等经济活动各环节,形成从宏观到微观各领域的智能化新需求,催生新技术、新产品、新产业、新业态、新模式。引发经济结构重大变革,深刻改变人类生产生活方式和思维模式,实现社会生产力的整体跃升。
产业智能官 AI-CPS
用“人工智能赛博物理操作系统”(新一代技术+商业操作系统“AI-CPS OS”:云计算+大数据+物联网+区块链+人工智能),在场景中构建状态感知-实时分析-自主决策-精准执行-学习提升的认知计算和机器智能;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。


长按上方二维码关注微信公众号: AI-CPS,更多信息回复:
新技术:“云计算”、“大数据”、“物联网”、“区块链”、“人工智能”;新产业:“智能制造”、“智能农业”、“智能金融”、“智能零售”、“智能城市”、“智能驾驶”;新模式:“财富空间”、“特色小镇”、“赛博物理”、“供应链金融”。
“人工智能赛博物理操作系统”官网:AI-CPS.NET
本文系“产业智能官”(公众号ID:AI-CPS)收集整理,转载请注明出处!
版权声明:由产业智能官(公众号ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源。部分文章推送时未能与原作者取得联系。若涉及版权问题,烦请原作者联系我们,与您共同协商解决。联系、投稿邮箱:erp_vip@hotmail.com





