贝叶斯分类器以及与互信息分类器—国科大UCAS胡包钢教授《信息论与机器学习》课程第七讲
【导读】如何进一步理解贝叶斯分类器以及与互信息分类器的区别是机器学习中的重要基础知识。涉及到的基础问题一是处理不平衡数据背后的数学原理是什么。二是如何验证贝叶斯大脑猜想。本章给出了初步研究进展。

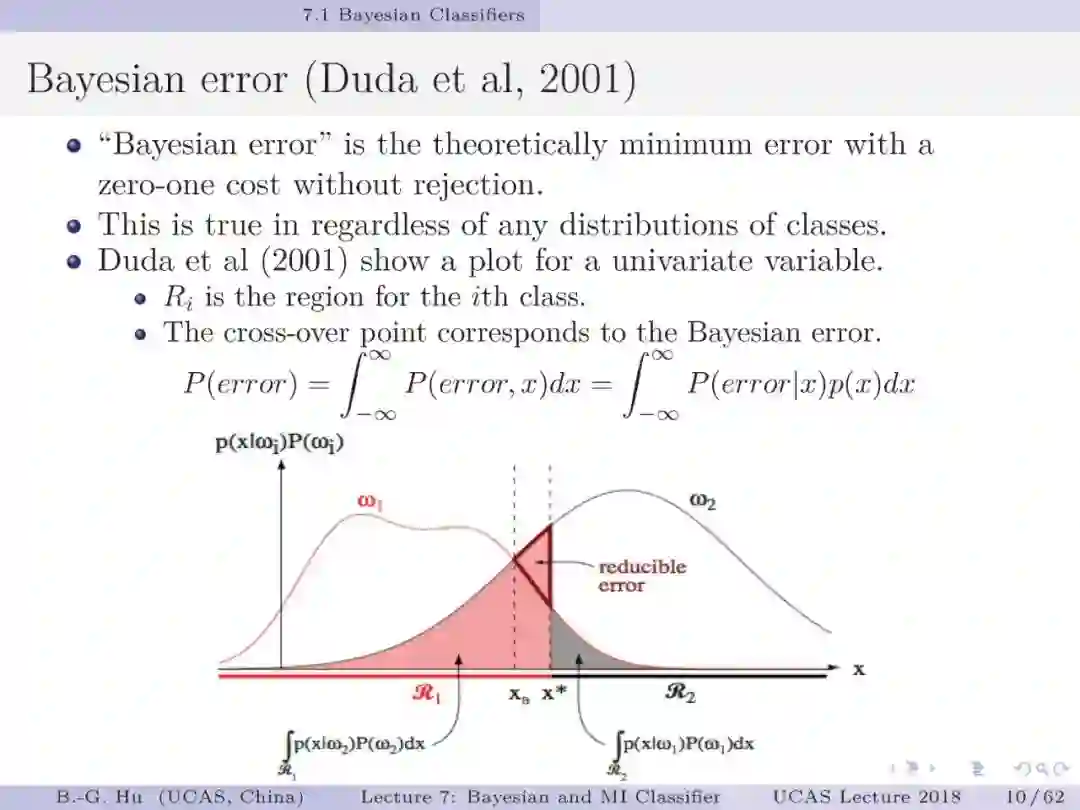
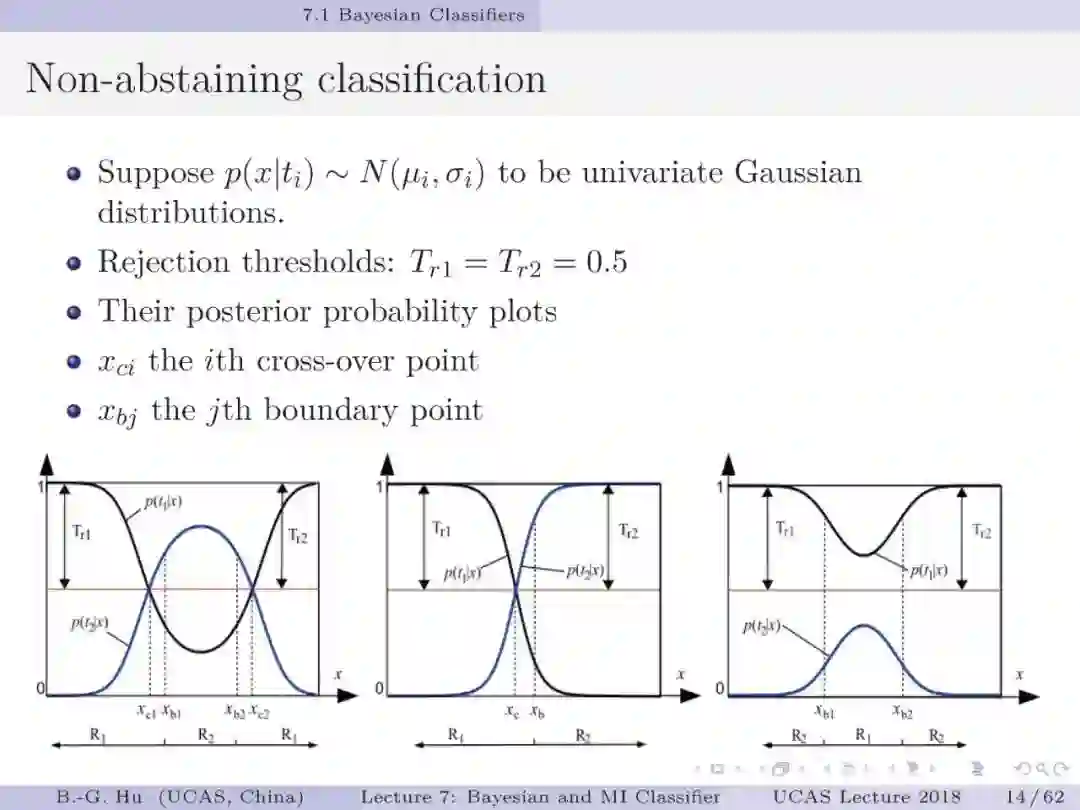
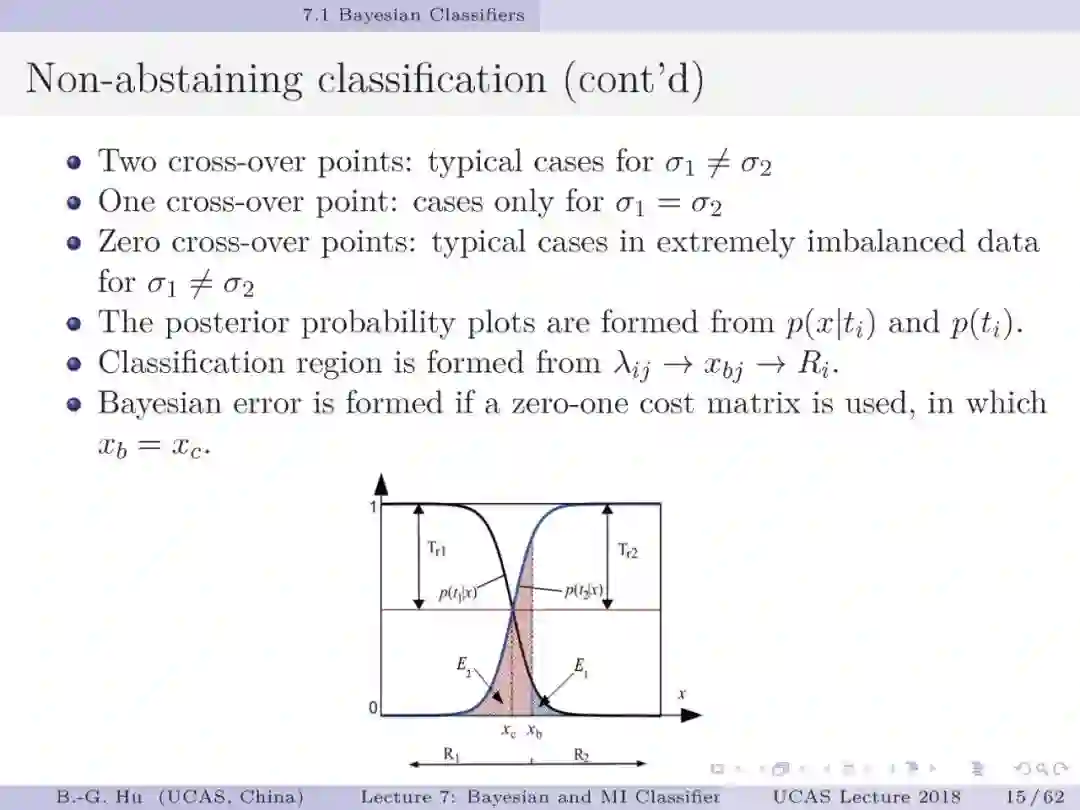
美籍华人学者周紹康(Chow,C.K.)1957年开创式将贝叶斯方法引入模式识别研究中,其它重要学术贡献还有:融合拒识智能决策于分类问题中与共同提出“周-刘”树的方法。这些都是创造知识的经典范例。本人正是受益于他1970年研究工作并扩展为不同拒识阈值(T_r1≠T_r2)情况下导出新的理论公式,更具一般性和图解释性(第13,14,16页)。目前教科书中通常是以单交叉点图(第14页中图)示意二值分类。其中三个定理扩充了机器学习与信息理论方面的基础知识。第一定理给出了不平衡数据下贝叶斯分类器将失效的证明。第二定理给出了代价矩阵中独立参数个数。这是参数可辨识性(即关于模型参数能否被惟一确定性质)研究内容。定理证明中应用了复合函数中独立参数个数上界是其中最小尺寸参数集的维数,可以理解为木桶原理中的短板决定木桶容量。该方式证明有利于延伸到对多类分类代价矩阵中独立参数个数的理解。第三定理给出了第二章中第3作业的解答。应用修正互信息定义不仅可以简单地解决问题,在非拒识情况下与原始互信息定义等价。它是否会引入其它问题还值得读者思考。
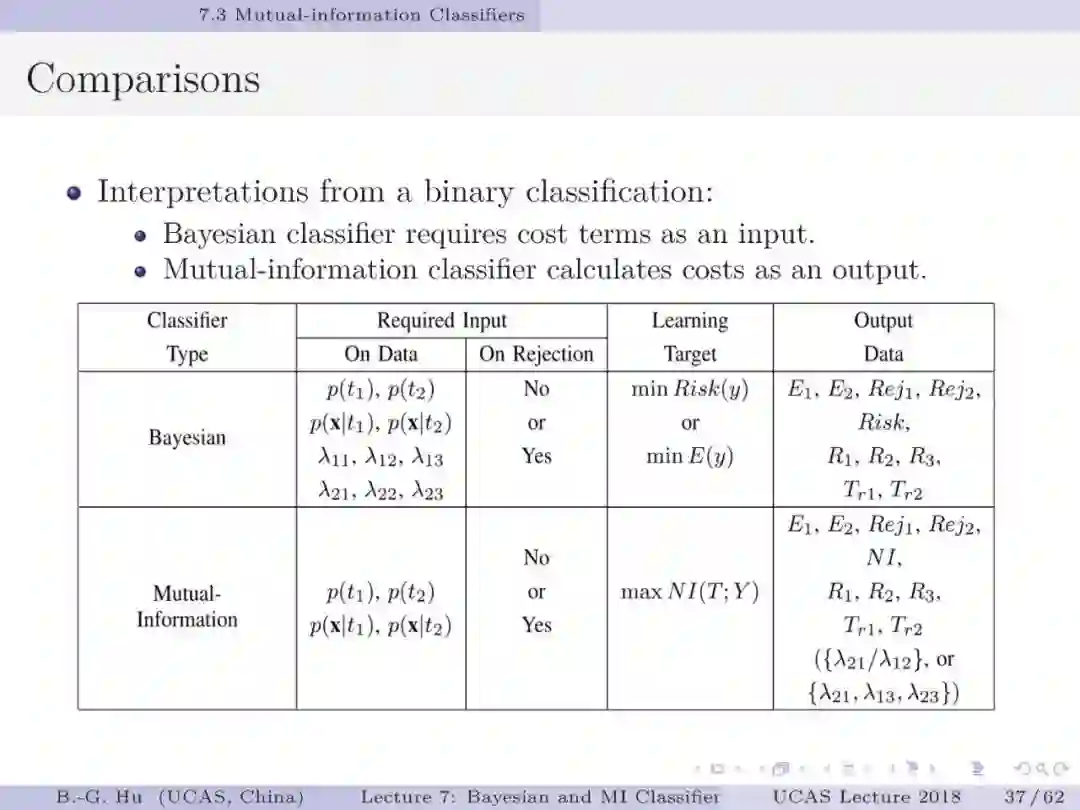
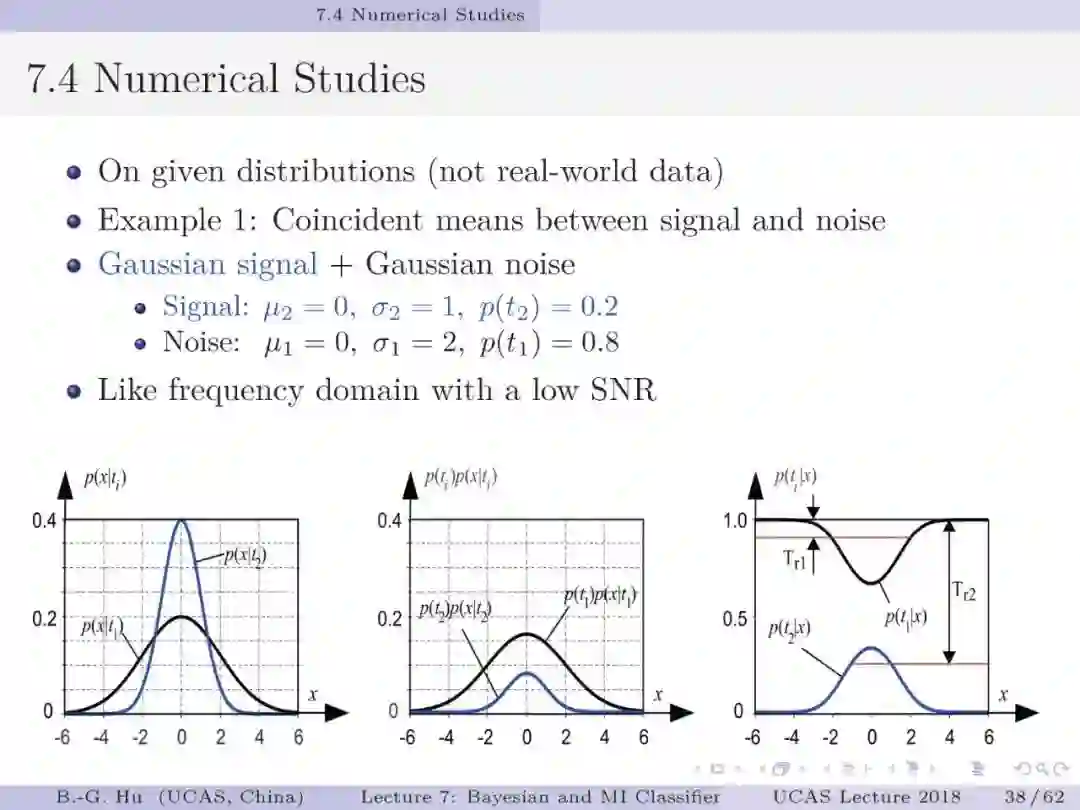
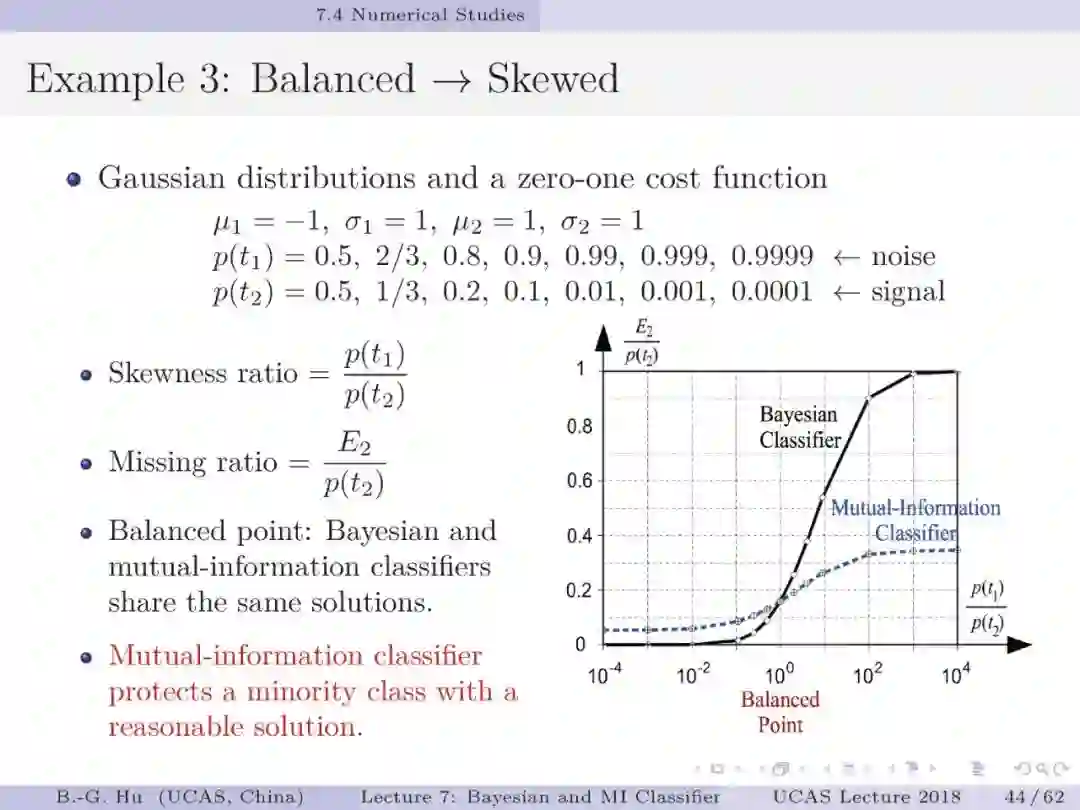
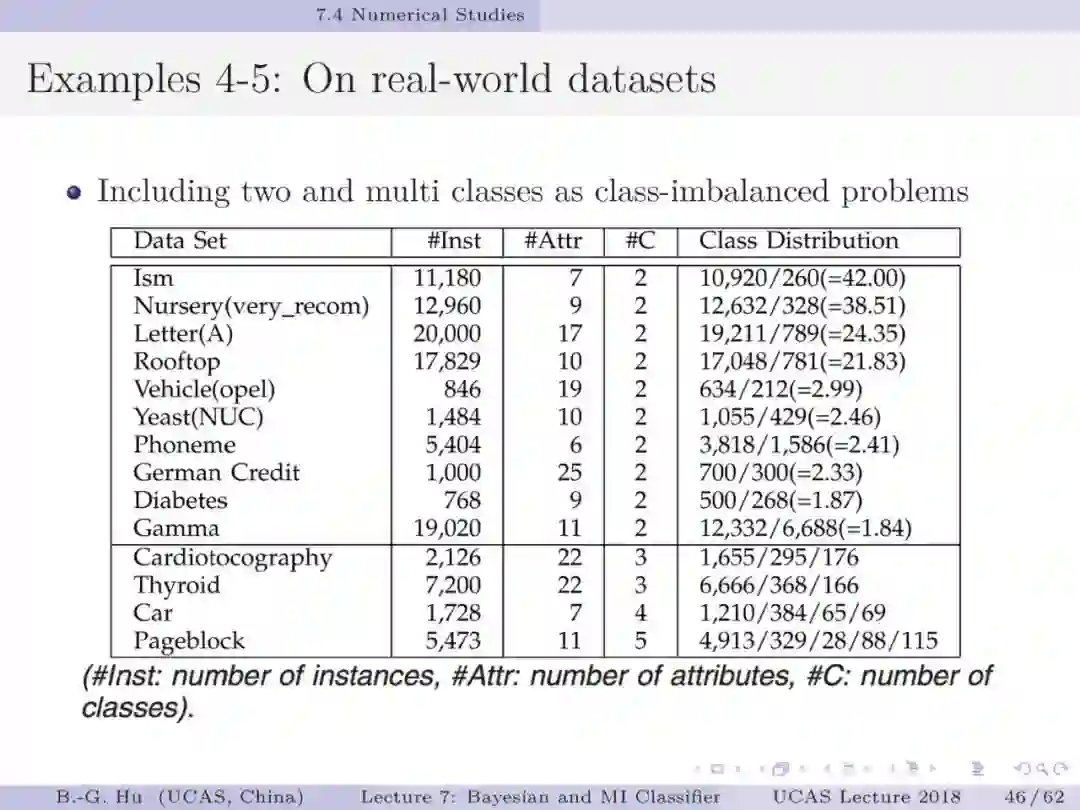
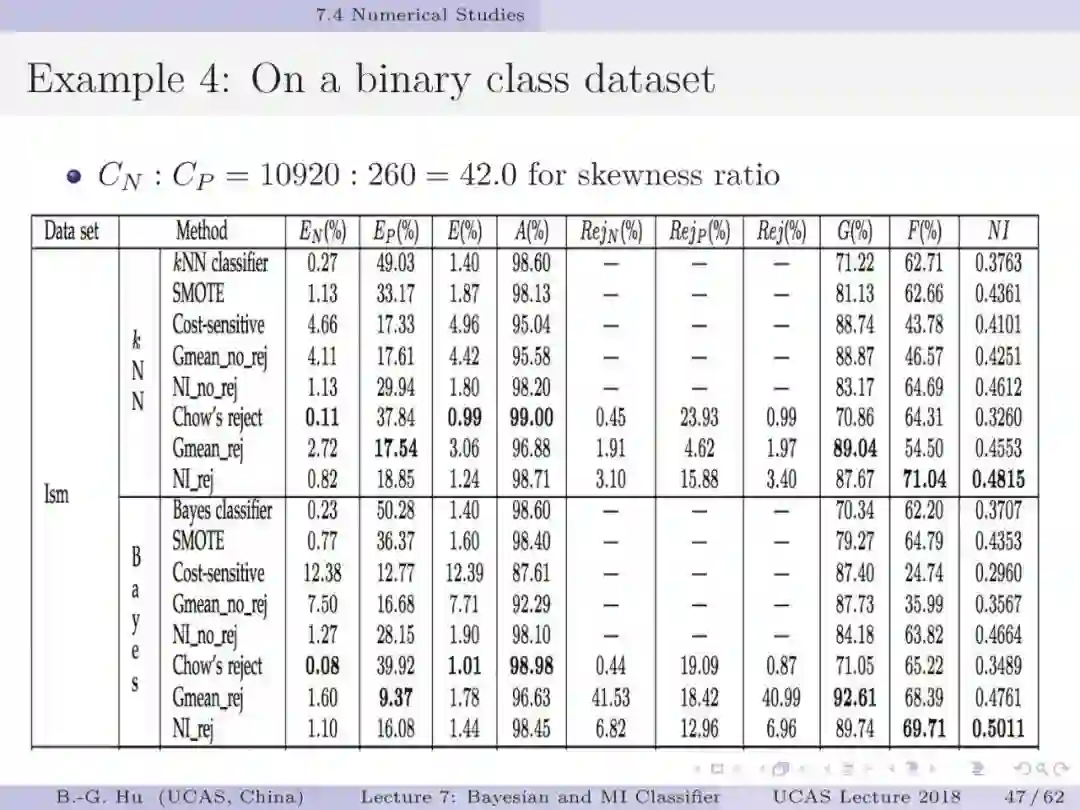
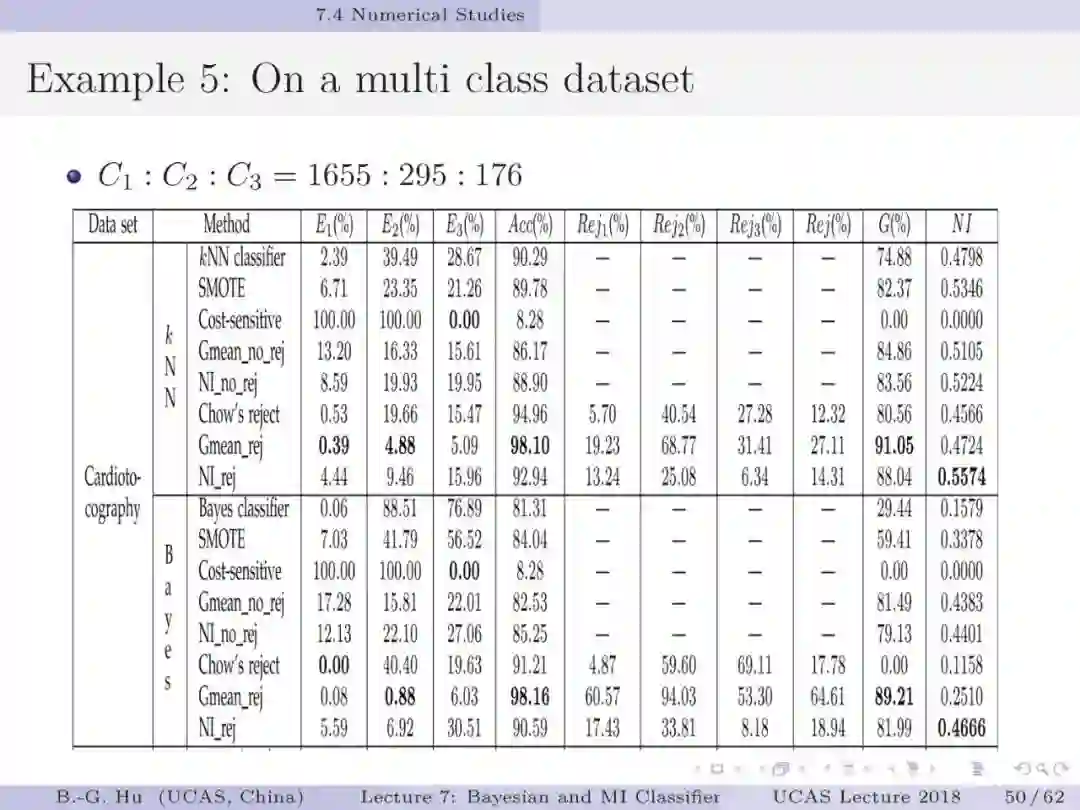
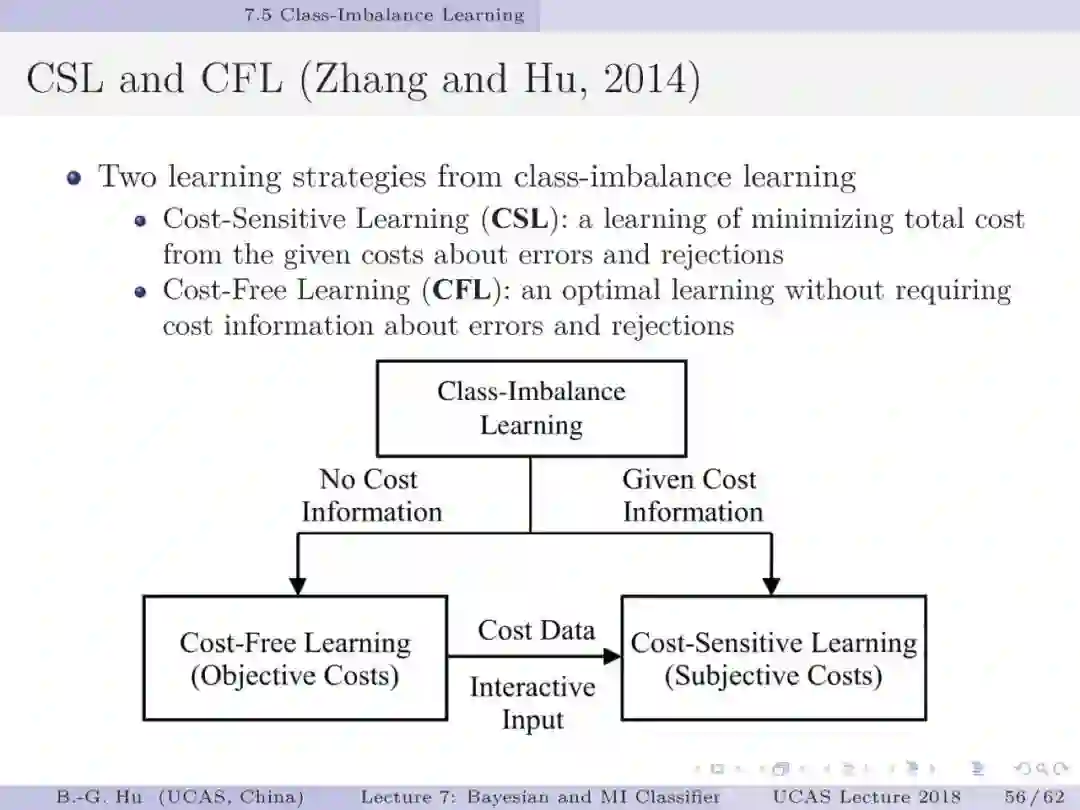
如果将贝叶斯分类与互信息分类视为两种不同数学原理,如第5章中第13页,代表了两种不同驱动力机制(力学方式思考)。要理解第44页中给出的例题为回答上面两个基础问题很有意义。处理不平衡数据要求小类样本被多数正确识别(第1章中第38页)。例题数值结果表明贝叶斯分类器是失效的。这样一个反例即可以推翻贝叶斯为大脑统一理论的猜想。例题的重要发现是熵原理支撑了“物以稀为贵”这样的分类决策(第54-55页)。另一方面我们要理解证实某数学原理为统一理论则必须要穷举。这通常是无法做到的。本人建议应用“猜想(conjecture)”的说法(如第1章第33页)。这部分仍然需要读者质疑”。对于大数据下的不平衡数据学习,对应代价敏感学习我们首次提出了代价缺失学习(即没有代价方面信息)。虽然已经有其它的代价缺失学习方法(如AUC, 几何平均等),但是只有互信息分类器能够处理拒识学习(第57页)。建议要思考这个“独门绝技”方法的内涵。信息论不仅能够深化解释性,而且还为发展新的工具提供原理性的方法。
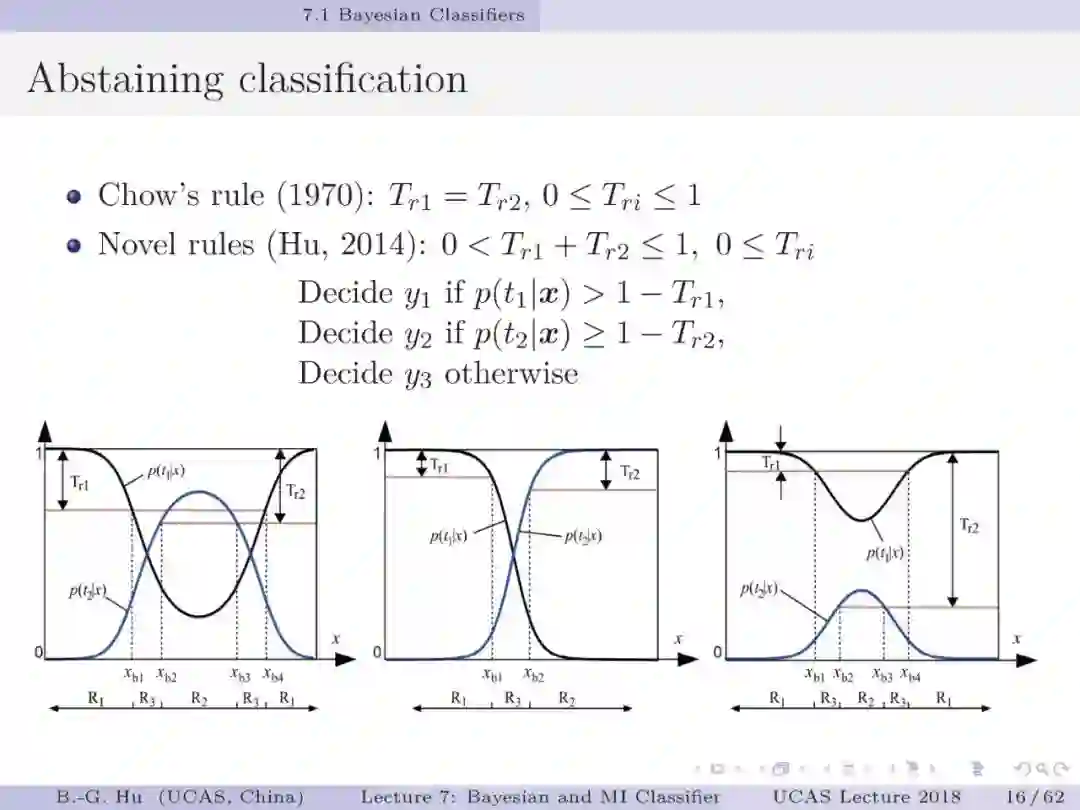
第30,43页: 解释为什么在拒识分类中应用代价矩阵会有解释不一致性问题。这里以二值分类为例,会存在两组参数是代表了同一个分类器。而第一组对应了误差代价固定且相同,只是拒识代价不同。第二组对应了拒识代价固定且相同,只是误差代价不同。这种现象被称为解释不一致性。由此会在应用中产生混乱的解释结果。而应用拒识阈值可以获得唯一解释性。
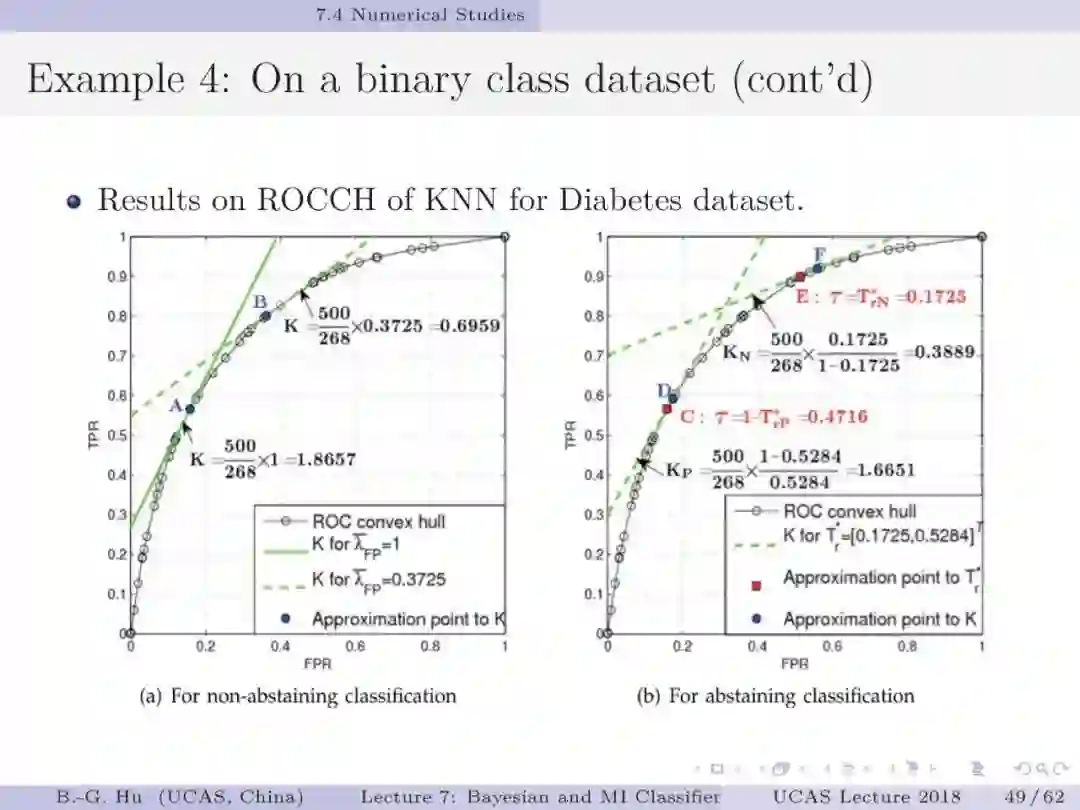
第32页: 希望同学们明白知识创新并非只是“高大上”的产物,只要是有心人,是可以预期获得的。由张晓晚博士发展的的拒识分类ROC曲线(第32页中右图)就是这样的实例。这是可以进入机器学习教科书中崭新基础知识。已有研究是应用三维方式描述拒识情况。而二维ROC曲线不仅常规应用,而且解释性更直接与简单(相关点给出的斜率计算公式解释与独立参数个数的解释)。要理解对于同一个ROC曲线,左右图是有关联的。左图只是右图中拒识率为零的特殊情况。另一方面,左图ROC曲线中黑点位置应该位于右图ROC两个黑点之间的曲线中(满足第13页中不等式关系)。为避免数据构成的ROC经验曲线导出代价矩阵中有负值情况,应用中采用ROC凸包曲线(ROCCH,第49页)常规方法。
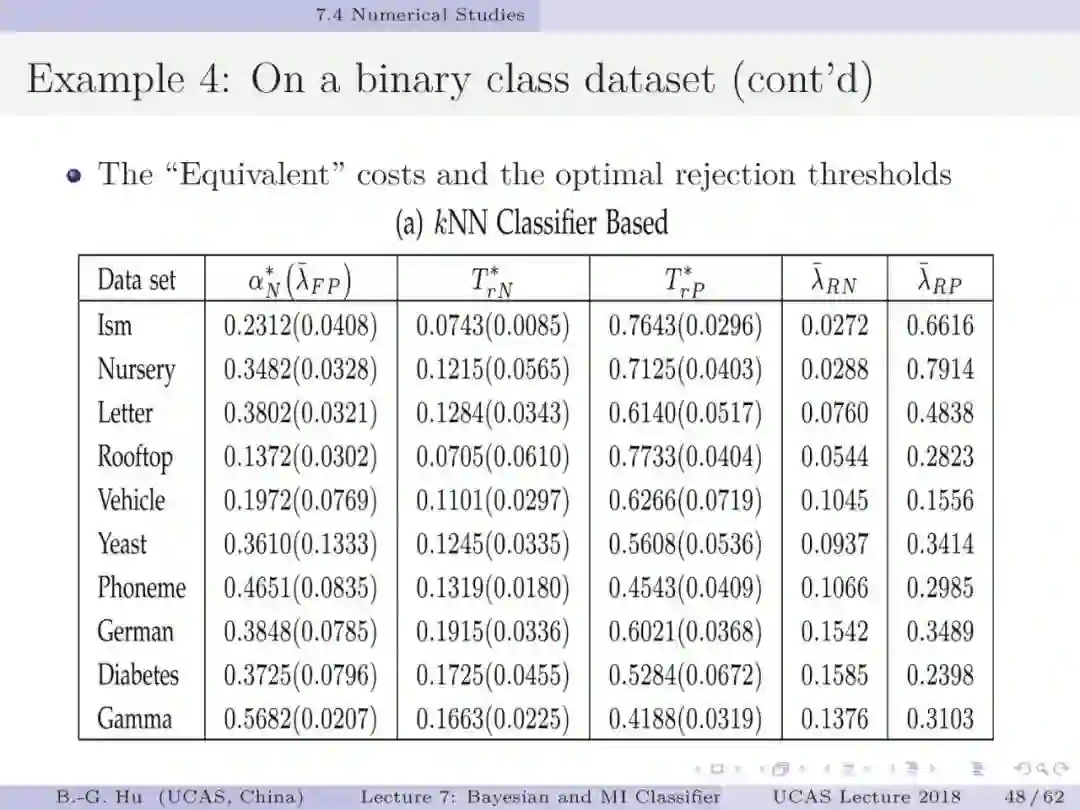
第45,52页: 应用互信息分类器可以根据数据分布获得拒识阈值方面的信息。考虑到拒识分类常规应用中人们习惯应用代价矩阵。我们提出了代价矩阵计算方法,并保证解释一致性。该方法提出了两步计算方式。第一步是应用互信息分类器对数据按照非拒识分类计算,计算结果可以唯一确定一个代价参数。第二步 是应用互信息分类器对数据按照拒识分类计算,获得拒识阈值具体值两个(T_r1与T_r2)。根据第13页中拒识阈值与代价参数之间的关系,以及其中四个代价参数已知(见第45页),可以唯一确定剩余两个固定代价参数。由此确保代价矩阵是唯一结果,实现了解释一致性。
作业:
1. 在第32页左图中,当类别趋于极端不平衡情况时,贝叶斯分类器会位于ROC曲线中的什么位置?互信息分类器结果会怎样?
2. 讨论题:第54页中是基于“物以稀為貴”语义的分类讨论,有否应用中会与此相反?这时应该建议什么样的学习目标?
3. 思考题(第58页):拒识分类是人类决策中的重要智能方式之一。你会怎样找出优化方式的拒识阈值?人们一般是这样给出吗?
附录
在介绍本人课件结束之际,我再次推荐读者阅读香港城市大学陈关荣教授的文章:“你遇见过香农吗?”[1]。还有珍贵视频[2, 3],其中香农教授讲述个人经历: "In the beginning I didn't think it would have an enormous impact. I enjoyed working on these problems, just like I enjoyed working on lots of other problems, without any ulterior motives for money or fame. And I think that a lot of other scientists have this same approach, they work because of their love of the game". 向香农教授致敬!感谢他开启了新世界并告知我们应该如何开展科研工作。
阅读后更要理解陈关荣教授给出有关参考文献中的寓意,这里的“遇见”是意指科学技术中已有知识是如何从原理上“遇见”香农。这些文章给出的启迪是研究工作要主动与香农“相遇”,有利于获得深度知识。我们已有研究工作正是受益于此:学会主动接受好的学术思想影响,并积极创新来影响他人。其中实例有冉智勇博士首次建立了参数可辨识性理论与信息论和最优化理论之间的联系,为参数可辨识性理论带来更为深刻的理论解释[3],而参数可辨识性应是统计机器学习模型中基础理论内容[4,5]。学习前人而非迷信,并相信好作品终会冒出(佩雷尔曼与华为产品等实例)。为破除迷信,本人建议“大师时代已然逝去?当下唯有作品为重!”的说法[6] (如有“惊诧”质疑,欢迎“专业”指正)。科研工作犹如艺术与文学创作,讲究作品文化。以专业方式勇于“吾往矣”是关键。质量如何,让同行与历史评说去吧。在此给同学们两个建议:1. 力争从“人工智能数学”或物理理论层面思考来主动与香农等大师“相遇”。2. 在未来工作中用你们的创新作品说话。
最后本人教学结语是对中国教育发展的期许,特别愿意引用中国伟人毛泽东先生的豪情词语:“一万年太久,只争朝夕”。
1. http://www.ee.cityu.edu.hk/~gchen/pdf/Shannon.pdf
2. https://ieeetv.ieee.org/history/the-shannon-centennial-1100100-years-of-bits
3. https://thebitplayer.com/
3. Ran, Z.-Y., and Hu, B.-G., “Determining parameter identifiability from the optimization theory framework: A Kullback–Leibler divergence approach”, Neurocomputing, Vol. 142, pp. 307-317, 2014.
4. Ran, Z.-Y., and Hu, B.-G., “Parameter Identifiability in Statistical Machine Learning: A Review”, Neural Computation, Vol. 29, pp. 1151-1203, 2017.
5. 冉志勇,胡包钢,“统计机器学习中参数可辨识性研究及其关键问题”, 《自动化学报》, Vol. 43, No. 10, pp. 1677−1686, 2017.
6. https://www.zhuanzhi.ai/document/5eeb02d0e6664e43f7d0edfb038ac822?from=doc_right_sim_rec
前期课程链接:
第一讲:
国科大UCAS《信息论与机器学习》课程,中国科学院自动化研究所胡包钢研究员
第二讲:
国科大UCAS胡包钢教授《信息论与机器学习》课程第二讲:信息论基础一
第三讲:
国科大UCAS胡包钢教授《信息论与机器学习》课程第三讲:信息论基础二
第四讲:
熵与其它信息量估计—国科大UCAS胡包钢教授《信息论与机器学习》课程第四讲
第五讲:
二值分类熵界分析—国科大UCAS胡包钢教授《信息论与机器学习》课程第五讲
第六讲:
国科大UCAS胡包钢教授《信息论与机器学习》课程第六讲:信息指标与拒识分类评价
课件文件:















































附录文件:







专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“ITML2020” 就可以获取《国科大UCAS《信息论与机器学习》课件》专知下载链接






