7 月 30 日,今日头条宣布正式推出新版「灵犬」反低俗助手,新工具除了文本内容识别功能的进化以外,首次加入了图片识别功能。这是时隔半年,「灵犬」的又一次重大升级。
「灵犬」是一款检测内容健康程度的小工具,旨在帮助人们打击低俗低质内容,净化网络空间。
新一代「灵犬」首次引入了自然语言处理领域里最近热门的 BERT 模型,在多达 1.2T 的数据训练之后,灵犬的内容识别准确率提升到了 91%。
人工智能真的可以解决内容审核了?
在今日头条总部,字节跳动人工智能实验室总监王长虎和我们进行了一番交流。
目前看来,技术可以解决的问题很多,但缺点也不少。
![]()
在移动互联网成为主流的今天,科技公司需要处理的数据正在呈几何级数增长,很多企业都在建立自己的技术审核机制。
去年 9 月,Facebook 发布并部署了名为「罗塞塔」的系统来解决内容审核问题,罗塞塔每天可以实时从超过 10 亿张图像和视频帧中提取文本,并能识别并审核多种语言的文字内容。
在国内,知乎去年推出的社区管理大脑「瓦力」,希望通过多种算法处理社区内不友善、答非所问、低质量、违法违规等方面的内容。
据介绍,这一系统每天可以清理约 5000 条新产生的低质量内容。
尽管各家公司都在使用自己的算法技术应对违规内容,但面对语言和图片的无限可能性,人工智能还是经常会出错。
而另一方面,内容审核就像无人驾驶汽车一样,漏判造成的后果会很严重。
没有足够召回率的话,再优秀的算法也无法实用化。
去年的美国独立日期间,「独立宣言」的选段曾被 Facebook 的算法判定为涉嫌种族歧视而遭删除。
![]()
2016 年,Facebook 曾恢复一张被误删除的越战新闻照片。照片描述了美国在越南轰炸制造的「战争恐怖」,画面是一个被凝固汽油弹烧伤的越南女孩,赤身裸体在奔跑。这是机器审核误伤的著名案例。
那么,文本、图片处理的技术难点在哪里?
让我们先从让技术如何学习语言说起。
自然语言处理(NLP)的历史几乎跟计算机和人工智能的历史一样长。
自计算机诞生起,就有了对人工智能的研究,而人工智能领域最早的研究就是机器翻译及自然语言理解。
这并不意味着今天的机器对于语言的理解能力有多高,事实上,我们距离真正的智能还有很长一段路要走。
计算机非常擅长使用结构化数据,例如电子表格和数据库表。
但是我们人类通常使用非结构化的文字互相交流,这对计算机来说不是一件好事。
![]()
让计算机理解「It」就是指代「London」,是非常困难的一件事——更不用说不带脏字的骂人和阴阳怪气的回复了。
为了让机器理解语言,我们通常需要遵循一个流水线过程:
首先把文本拆分成单独的句子,进而把句子分成不同的单词或标记,接下来,我们需要让机器尝试猜测每个标记的词类:
名词,动词,形容词等等。
经过词形还原、识别停止词、依赖解析等过程之后在命名实体识别(NER)过程中通过统计模型,使用上下文来猜测单词代表的是哪种类型的名词。
自然语言处理技术虽然已经让计算机一定程度上能够理解文字的含义,但大多数研究都是基于英文的。
仅从 NLP 研究角度而言:
中英文在词性标注、句法分析等任务上颇有差异。
主要体现在英语有明显的屈折变化(单复数、时态等)而汉语缺少这些屈折变化。
对于文字内容审核来说,算法必须能够通过「拟合」过程知晓单词的语义;
另一方面,算法也必须具备泛化能力,在理解语义的基础上,能够举一反三。
目前最常见的文本分类模型主要包括 Fasttext、TextCNN、TextRNN 及其各种变体。
其中,fasttext 直接基于文本中 token 的平均嵌入进行分类,该方法虽然未考虑词序,但简单有效。
TextCNN 基于卷积建模文本的局部依赖关系 (local feature), 通过池化学习全局信息。
CNN 能够在降维的同时捕捉到局部词序关系。
若要建模长距离依赖关系,需依赖于多层的卷积和池化层,模型结构较复杂。
TextRNN 基于 LSTM 或 GRU 建模文本的序列模式, 能够有效建模文本的长距离依赖关系。
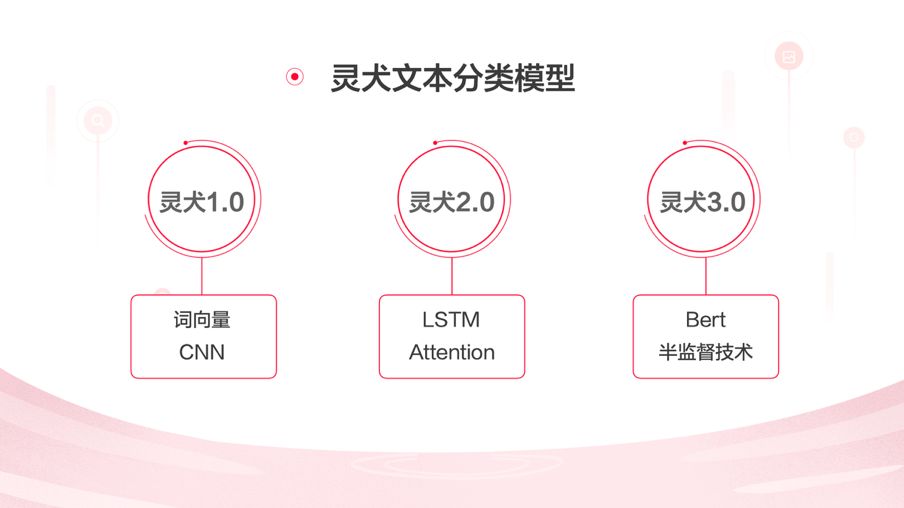
今日头条「灵犬」背后的文本分类模型经历了三次迭代,第一代灵犬的文本识别模型应用的是「词向量」和「CNN(卷积神经网络)」技术,训练数据集包含 350 万数据样本,对随机样本的预测准确率达到 79%。
第二代灵犬,应用的是「LSTM(长短期记忆)」和「注意力机制」,训练数据集包含 840 万数据样本,准确率提升至 85%。
每个新版本相对于旧版本,在技术和数据集层面都有了明显的跃升。
第三代灵犬已经用上了 BERT。
![]()
「BERT」是当前最先进的自然语言处理技术,NLP 领域近年来重大进展的集大成者。
这项技术在常见的阅读理解、语义蕴含、问答、相关性等各项任务上曾经一次刷新了 11 项业内最佳记录,但也因为高达 3 亿的参数量让大多数开发者望而却步。
「BERT」提出了一种深层模型结构,使用「遮挡」方式同时利用上下文提高准确性,并通过无监督学习对天然超大规模语料建模。
由于自然语言具有天生的连贯性,经过大规模训练的语言模型的预测能力,达到了前所未有的水平。
新版「灵犬」同时应用了「BERT」模型和半监督学习,并在此基础上使用了专门的中文语料,在不牺牲效果的情况调整了模型结构,使得计算效率达到了实用水平。
今日头条表示,相比之前的 LSTM+Attention 方案,BERT 方案下的内容识别模型机器延迟为 125ms,算力需求增加了 33 倍,准确率的提升则为 7.04%。
与文字不同,机器进行图像识别的过程就像在盲文上进行阅读,像素是一个个信息点,最终要通过所有信息点内容的集合做出一个最为合理的判断。
这种方法让机器在特定的图像视觉处理上已经可以超过人类。
比如说在动植物物种的识别上,计算机就比我们更为「专业」。
但在更多的情况下,内容检测还是一个具有挑战性的任务。
目前常见的图像分类的基本思路是基于 ImageNet 预训练分类模型 (e.g. ResNet、 Xception、 SENet 等),在进行结构和参数的调整;
然后基于微调后的模型提取图像 feature,作为特定任务分类模型的输入进行图像分类。
这些基于卷积神经网络的方法有着被「欺骗」的风险。
![]()
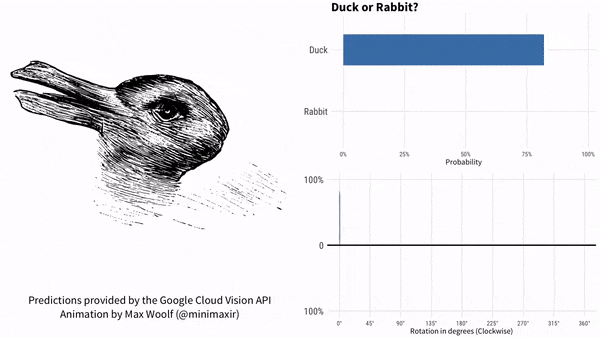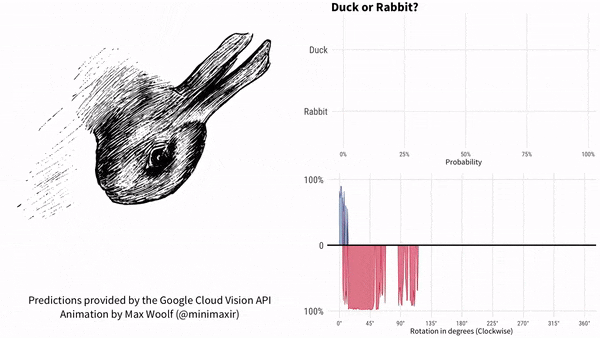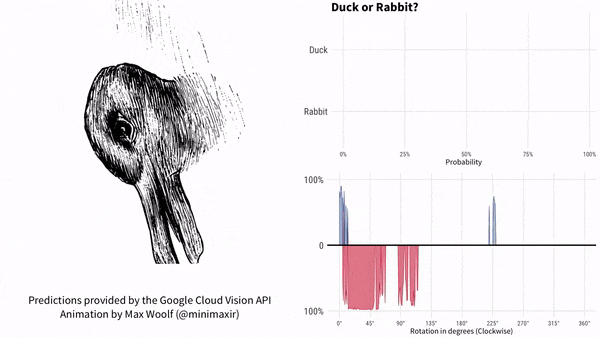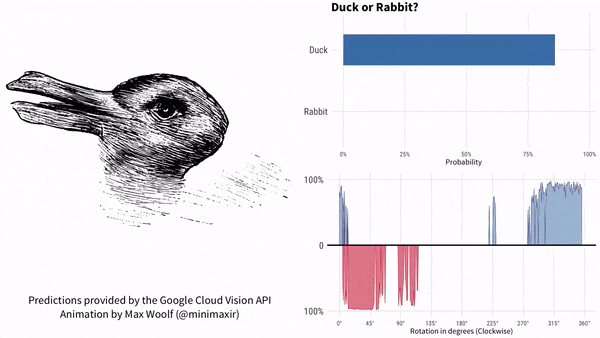
上图中的动物形象,自 1892 年首次出现在一本德国杂志上之后就一直让人感到迷惑:
有些人只能看到一只兔子,有些人只能看到一只鸭子。
有人把这张图片输入进谷歌机器图像识别工具中,结果机器认为 78% 的概率是一只鸟,68% 的概率是一只鸭子。
供职于 BuzzFeed 的数据科学家 Max Woolf 随后设计了一个更复杂的实验:
他干脆让这张图旋转起来,想要看看机器会做何判断。
结果,谷歌 AI 最初认为这是一只鸭子,鸭子嘴指向 9 点方向。
随着鸭子嘴向上转到 10 点方向,很快谷歌 AI 就认为画里面是兔子了,直到鸭子嘴转到 2 点方向之后。
此后一段时间,谷歌 AI 认为既不是鸭子也不是兔子。
一直到 7 点方向,谷歌 AI 再次肯定是一只鸭子。
有人认为,这或许是因为人类在判断物体时对于空间的认识具有先验性——用这样的标注数据训练出的模型,在不知不觉中也将空间和方向等因素考虑在内了。
而且,不仅旋转图片会让机器迷惑,有时候就连不同的图片尺寸也会让机器给出不同的判断。
对于图片内容审核来说,难点包含三方面:
数据不均衡、类内方差大和不可穷举。
低俗图片样本占数据集内容的比例较低,经常导致深度学习模型训练效果不佳。
此外,低俗图片的种类丰富、繁杂,构成低俗图片的特征千差万别。
对此,「灵犬」运用的解决方案是优化深度学习。
「我们分别在数据、模型、计算力等方面做了很多优化,」王长虎介绍道。
「在数据层面上,灵犬已累积了上千万级别的训练集。
而在模型层面上,灵犬针对许多困难样本做了模型结构调优,尝试解决多尺寸、多尺度、小目标等复杂问题。
在计算力层面上,灵犬利用分布式训练算法以及 GPU 训练集群,加速模型的训练和调试。
」
为应对用户上传不同比例的图片,今日头条在图像识别算法中设计了「多桶模型」,使得各种比例的图片都能有很好的识别效果。
在模型进行预测时,算法会根据传入的图片比例寻找比例最接近的「桶」,进而给出相应的预测结果。
由于不同比例的桶对应的模型的参数是共享的,所以预测时间和单模型基本接近。
而由于经过了对应模型的处理,算法也可以进一步提升准确率。
在以人为主的场景中,为解决人在图片中的面积占比变化较大的问题,工程师引入了特征金字塔结构,对不同尺度的物体,它能提高模型提取一致性特征的能力。
常规的网络结构会对图片进行多次卷积,得到图片的特征图,再对接全连接层进而得到图片的分类结果——但这种方法有一个缺点,如果测试集中人在图片中的占比和训练集差距较大,就会导致效果下降。
在网络中引入特征金字塔结构,将底层特征和上层特征融合,并在每层给出预测结果,可以同时利用底层特征的高分辨率和高层特征的高语义信息。
![]()
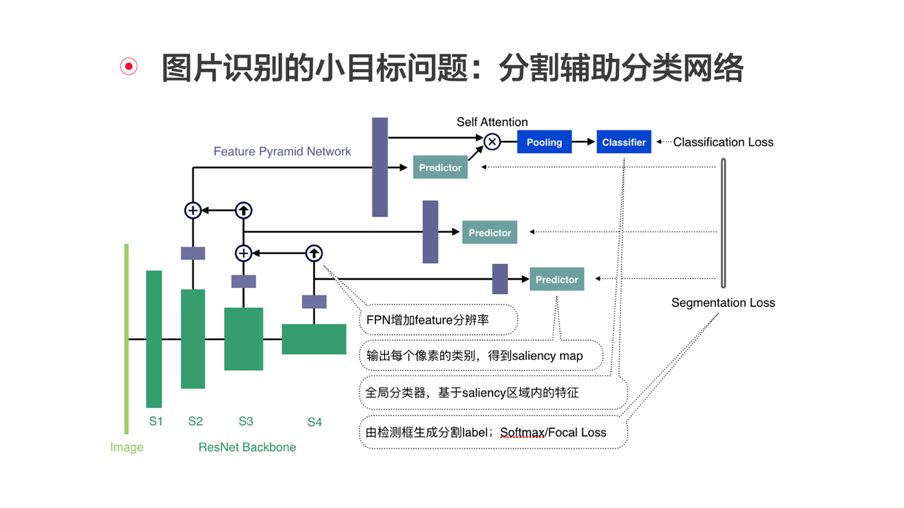
为应对在图片中出现小范围问题区域的挑战,今日头条还设计了分割辅助分类网络。
该网络结合了特征金字塔结构,训练分为两部分,分割部分每层的预测结果都会与标注区域计算损失,分类部分将预测出的区域与特征图进行叠加,再进入分类器和分类标签计算损失;
预测时,特征金字塔结构会输出预测区域,将该区域与特征图叠加,再送入分类器即可得到分类结果。
虽然使用了优化过的算法,但一些技术难以搞定的问题,现阶段还有赖于人工判断:
世界名画中常常出现裸女形象,如果完全交由机器判断,机器通过识别画中人物的皮肤裸露面积,就会认为这幅画是色情低俗的;
而某些拍摄芭蕾舞的图片,以机器的视角来看,或许类似于裙底偷拍。
王长虎认为,针对低俗判断问题的复杂性和不同判断方式的局限性,一方面需要不断进化技术模型,另一方面需要有效结合技术和人工判断两种方式。
「我们的模型还在不断进化,除了灵犬反低俗系统,还有色情、低俗、标题党、虚假信息、低质等几百种模型,」王长虎表示。
「自 2012 年建立以来,今日头条已建立起近万人的专业审核团队来保证内容的安全。
」
人工智能可以帮助我们大幅提升审核效率和准确率,但在现阶段甚至很长一段时间内,它仍无法完全代替人类进行所有判断。
因为机器还很难理解内容背后的深意,也不会在不同文化场景中做自由切换,或及时学会不断变化的标准尺度。
目前看来,在内容审核上机器+人工的方法是最合理通行的做法。![]()
本文为机器之心原创,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com