超越整句的流式多级Attention:解密百度输入法背后的语音识别模型
机器之心原创
作者:晓坤、思源
1 月 16 日,百度输入法举办了「AI·新输入全感官输入 2.0」发布会,正式对外发布百度输入法 AI 探索版,这是一款默认输入方式为全语音输入、并以注意力机制为语音核心的新产品。新语音模型结合了 CTC 和 Attention,为每日数亿条语音识别调用提供硬核支持,本文将带你一观新模型是如何劝君「动口不动手」。
全语音交互对于语音识别准确率要求极高。百度表示,其 AI 探索版的语音输入用户体验提升得益于四项重大突破,分别是在在线语音、离线语音、中英混合语音以及方言四个领域上实现的。
关于在线语音识别,百度发布了流式多级的截断注意力建模(SMLTA),将在线语音识别准确率相对于上一代 Deep Peak 2 再次提升 15%,并实现了基于 SMLTA 模型的在线语音识别服务大规模上线应用。
在离线语音识别中,百度通过持续优化去年 1 月发布的 Deep Peak 2 系统,让离线语音输入相对准确率再次提升,并表示可以保证在没网的情况下实现输入法的流畅快速使用。百度输入法「中英自由说」可以在不影响中文语音输入准确率的情况下,实现高精准的中英文混合语音识输入(例如,可以准确地区分「有你的快递」和「you need cry dear」)。「方言自由说」则将普通话和六大方言融合成一个语音识别模型,在输入时可以无需设置自由切换,无论是普通话和方言之间,还是方言和方言之间。
开启百度输入法 AI 探索版后,点击语音按钮,除了可以说出你要记录的内容,让输入法帮你直接录入转文字。还可以呼唤「小度小度」语音助手,并说出相应指令,即可实现语音修改、发表情、发弹幕、发文件等一系列操作,满足与输入相关的周边需求。可以说,百度输入法 AI 探索版的核心功能就是语音识别。
百度输入法 AI 探索版界面
在下文中,机器之心将介绍百度输入法中部署的最新在线语音识别模型——SMLTA 的架构细节。简言之,SMLTA 就是流式多级的截断注意力模型,是融合了 CTC、LSTM 和 attention 等近年语音识别技术的集大成者。百度表示,SMLTA 是在业界首个截断模型能超越整句的注意力模型,同时这也是第一次实现了基于 Attention 技术的在线语音识别服务的大规模上线。
可大规模工业使用的基于注意力建模的语音识别
CTC 模型和注意力 (Attention) 模型在学术界都不是新名词。尤其是注意力模型,是近些年研究的热点,注意力模型已经在实验室内被证明能够实现语音识别的端到端建模,这种建模将使得语音识别系统极度简化。相对于包括 CTC 在内的所有传统语音识别技术而言,注意力模型都被认为有较高的识别率。但这都只是在实验室得到的实验结论。注意力模型在投入实际工业应用中还会遇到大量的问题,例如无法做到一边传语音一边识别从而导致用户等待时间太长的问题和无法保证长句字识别时候的识别精度的问题等。
百度采用的是一种名为「流式多级的截断注意力模型(SMLTA)」,其中流式表示可以直接对语音的小片段(而不是必须整句),进行一个片段一个片段地增量解码,多级表示堆叠多层注意力模型,而最后的截断则表示利用 CTC 模型的尖峰信息,把语音切割成一个一个小片段,注意力模型建模和解码可以在这些小片段上展开。这样的模型就是支撑起每天数亿条识别任务的核心方法,也是工业上大规模使用注意力模型进行语音识别的范例。
其实想要了解百度的工业级语音模型,看看下面这张结构图就够了,其目前已经被证明在大规模应用上有非常好的效果。后面我们主要围绕这张图介绍 SMLTA 模型的具体结构:

如上所示为 SMLTA,最下面的输入声波会按照 CTC 尖峰的分布,被截断为一个个语音小片段(时间步),也就是 h 所表示的内容。除了截断外,这里 CTC 模型的另外一个核心作用是把短时平稳的语音信息抽象成高度集中的局部信息。之后的注意力建模就是在这个一个个小片段上进行的,这样的注意力建模被称作局部注意力建模。
按照 CTC 建模的特性,每一个语音小片段预测的就是一个基本建模单元(比如音节,或者高频音素组合)。在对每个语音小片段进行注意力建模前,百度进行了一个编码过程。编码过程抽取出来的特征就是代表这个建模单元的最本质描述特征 c。在注意力建模之后,百度又采用了 2 层 LSTM 模型,来描述每个单元的最本质描述特征 c 和识别结果之间的一对一的映射关系,从而实现完美的实现了端到端建模。这种建模方式,使得语音识别摆脱之前复杂的动态规划解码器带来的系统的冗余和复杂,使得语音识别过程变成一个简单的滚动生成过程:在一个时间步生产一个识别结果,然后滚动到下一个时间步,再生成下一个识别结果,直到识别过程结束。
由于该方法把传统的全局的注意力建模转换成局部注意力建模,所以这个过程也是一个绝对可以流式实现的过程,无论多长的句子,都可以通过截段来实现流式解码和精准的局部注意力建模,同时也实现了流式解码。
由于 CTC 模型必然存在着插入和删除等错误,这些错误会影响截断的效果,也就是影响语音小片段的定义,从而一定影响最终的模型精度。因此,在百度的 SMLTA 中采用了一种多级注意力结构。这种多级结构描述工作原理描述如下:具体而言,在上图不同的语音片段 h 上,第一层注意力机制会注意当前语音片段以及过去所有一段时间内的语音片段的语音特征信息,也就是注意不同发音对当前预测的重要性,且重要性是由注意力的权重α来决定的。直观而言,第一层 Attention 注意到的是 CTC 截断的「音」,这些音组合起来能表示某个具体的文字的特征,也就是输出结果 c。而第二层 Attention 是建立在前一层注意到的特征 c 之上,对第一层注意力模型的输出再进行第二次注意力学习。如果第一次注意力的学习结果存在冗余信息的话,经过第二次注意力建模,就能找到真正需要集中注意力的注意力点。
所以工业级的 SMLTA 模型最核心的部分还是利用 CTC 模型的尖峰对连续音频流做截断,然后在每个截断的小语音片段上进行注意力建模。传统的注意力模型必须需要在整句范围内建模,而百度的注意力模型却可以在小片段上建模。核心原因是因为 CTC 模型的尖峰信息所对应的特征表示是高度局部集中的。这种高度局部集中的特征表示,使得仅对当前截断的小片段做注意建模,就能够实现对当前建模单元的高精准描述。而不需要像之前那样对一个很大范围的声音信息进行「集中注意力」。
这就是流式的、多级的截断注意力模型,它解决了传统注意力模型不能进行流建模和解码的问题,并且依靠截断,实现了对长句子的高精准的注意力建模,同时也解决了 CTC 模型的插入或删除错误对注意力模型的影响。CTC 建模和注意力建模这两者的结合,对于学术或研究还是有很重要意义的,更不用说流式实时解码对工业应用的贡献了。
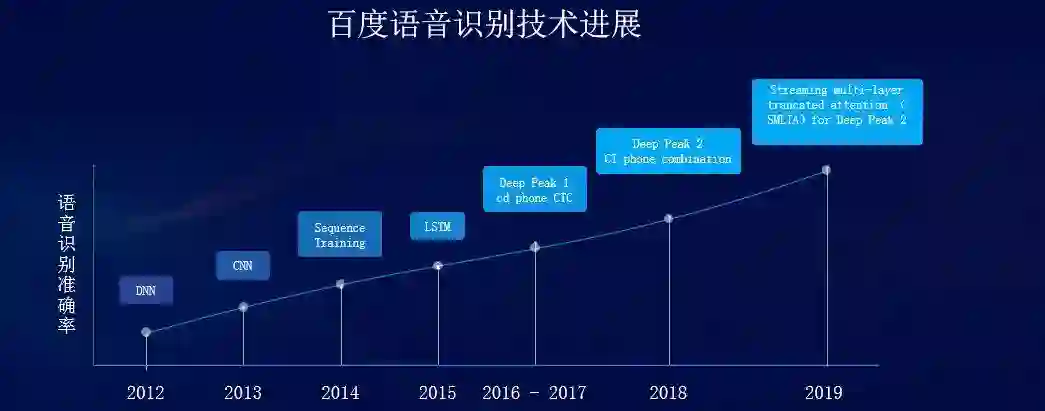
语音识别模型的迭代
SMLTA 也可以看成是百度上一代语音识别模型 Deep Peak 2 的进一步优化。Deep Peak 2 的全称叫做「基于 LSTM 和 CTC 的上下文无关音素组合建模」。上下文无关建模方式是指:把高频出现的音素联合在一起,形成一个音素组合体,然后将这个音素组合体作为一个基本建模单元。Deep Peak 2 还通过声学模型学习和语言信息学习相分离的训练方法,使用音素组合来保留最重要的音素连接特性,从而避免了上下文无关建模时的过拟合问题。这种建模方式可以显著缩小建模单元,带来更快的解码速度。
相比之下,SMLTA 对 Deep Peak 2 的核心改进在于局部注意力和多级注意力的引入,可以看成是将 Deep Peak2 通过结合注意力机制来获取更大范围和更有层次的上下文信息。这种改进一般而言会造成计算量的增加,但百度表示,其整体计算量和上一代的 Deep Peak 2 是技术相当的。整个工业产品部署完全是 CPU 部署,无需额外的 GPU 就可以完成。成本低廉,适合大规模推广使用。
By the Way
机器之心在发布会现场还见识到了百度输入法 AI 探索版的一项很有意思的功能——凌空手写。它不需要特殊的手写笔,也不需要类似深度摄像头或多目摄像头等硬件,只需要最普通的 RGB 摄像头即可。如下图所示,使用者只要对着摄像头竖起手指就可以在空气中开始写字,写完后张开手掌,就能结束写字,输入法会开始识别并将对应文字输出。图中的使用者正在尝试写一个「绍」字,已输出的「凌空手写张」也是用这个功能写的。

凌空手写采用双神经网络模型的方案:一个是基于灰度图的指尖跟踪模型,另一个是基于多方向特征文字识别模型。此外,研发团队发现锯齿和连笔在三维空间的手写识别中对识别率影响较大,于是对抗锯齿和连笔消除算法进行了大量优化工作。无论实用性如何,这么好玩的功能还是值得试试~

本文为机器之心原创,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com




