CVPR 2022 Oral | 从图形学顶会到视觉顶会:一份改良何恺明早期工作的图像拼接矩形化新基准
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
作者:廖康 | 已授权转载(源:知乎)编辑:CVer
https://zhuanlan.zhihu.com/p/492174095

论文链接:
数据集和代码链接:
1. 研究动机

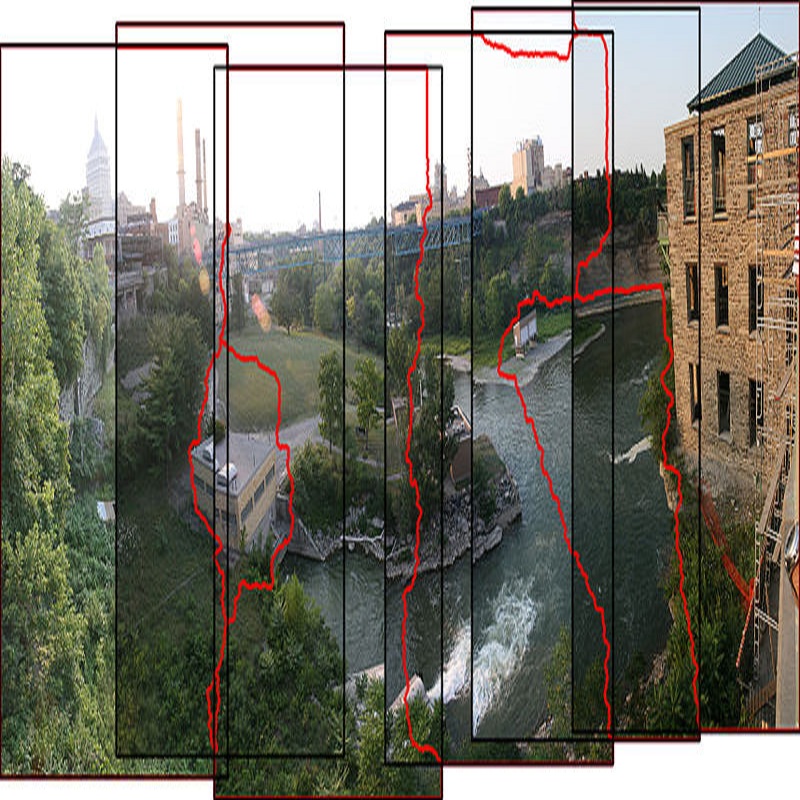
图像拼接技术在获得大视场的同时也因为视角投影带来了不规则的边界问题(如图1b)。为了获得规则的矩形边界,裁剪(图1c)和图像补全(图1d)为两种常见的方法,但这两种方法会减少原始图像内容或增加新的图像内容,使得这些结果在实际应用中并不完全可靠。
为了解决上述问题,Meta/前Facebook AI科学家-何恺明早在2013年就提出了第一个解决该问题的方法——rectangling(矩形化),并发表于计算机图形学顶会SIGGRAPH。该方法在不增加、不减少图像内容的基础上,通过网格变形的方式将不规则的拼接图映射为矩形。然而,该算法受限于LSD检测的性能同时也无法提取有效的语义感知特征,对结构复杂的场景并不鲁棒,其结果往往呈现出部分扭曲(图1e)。
在此背景下,我们提出了第一个拼接图像rectangling的深度学习解决思路,同时构建了第一个带标签的rectangling数据集,将计算机图形学问题结合新的深度学习范式并带至计算机视觉顶会。
2 Deep Rectangling
2.1 传统pipeline vs. 深度pipeline


图2. 传统矩形化 vs. 深度学习矩形化
传统方法分为两个阶段:local warping和global warping。
在第一阶段,首先会借助于image resize中的经典工作seam-carving,通过不断向拼接图中插入感知不明显的seam,来使得拼接图逐渐变化为矩形,然后放置一个刚性的初始网格在其中,随后去掉之前插入的seam,使得该矩形逐渐退化为拼接图的形状。这样一插一抽的过程帮助获得了一个紧贴着拼接图边界的初始网格(图2a “initial mesh”)。
在第二阶段,设计了3个能量项来优化最终的target mesh (图2a “optimized target mesh”):直线保持项(约束warp后直线不会扭曲),形状保持项(鼓励mesh中每个网格的变形为相似变换)和边界项(强制约束最终mesh边界紧贴矩形边界)。
最后通过从initial mesh到target mesh的warp,实现了拼接图的矩形化。从上述描述可以看出,该方法个两阶段的,每一步都过程繁复,最后两个warp过程由于mesh的不规则也无法采用矩阵加速。
区别于传统方法,我们设计了一种一阶段的rectangling策略。首先,我们预先定义好了target msh的形状(图2b “predefined target mesh”)为一个刚性的规则矩形,这种定义有助于矩形加速实现mesh warp,从而为深度学习实现mesh warp提供可能。随后rectangling被简化为了只需预测一个初始的mesh,并且这个初始的mesh必须和我们预定义的target mesh匹配。为了实现这一点,我们通过一个简单的神经网络从数据中学习mesh预测的能力。
2.2 网络结构与损失函数设计
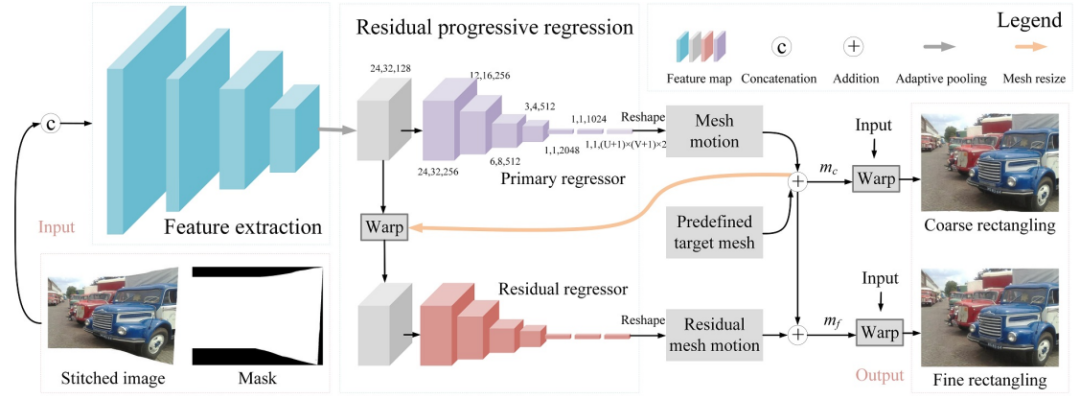
从单张图像中预测mesh是一个ill-posed问题,就像是从单张图像中预测光流或深度。为了验证该问题的可解决性,我们没有设计复杂的网络结构,采用简单的特征提取+回归的思路来简单实现预测mesh这一功能。
网络结构如图3,我们将拼接图与mask进行concat作为输入,然后堆叠了简单的conv-pooling模块来提取特征,随后再通过简单的卷积来实现mesh的预测。其中mesh(U×V)被表示成了(U+1)×(V+1)个顶点,每个顶带包含x和y方向的偏移量。即mesh可被表示成(U+1)×(V+1)×2的volume。
为了对标何恺明方法中优化的3个能量项,我们也将损失函数分为3个部分:content term,mesh term和boundary term。
在content term中,我们采用了深度学习image generation任务中常见的L1像素loss和L2感知loss,来帮助网络聚焦于语义感知明显的位置。
在mesh term中,我们设计了一个网格间和网格内loss,来约束相邻网格相似。
在boundary term中,我们通过mask来约束rectangling的结果尽量为一个完美的矩形。
3 数据集 DIR-D
数据集生成的具体过程比较复杂,请参考原论文。
简单说来,为了获得rectangling的数据集,我们从正常的矩形图像出发,反向warp出非矩形的结果,来模拟拼接图的不规则边界。为了使得反向warp出的模拟拼接图更加真实且无畸变,我们人工对warp的结果进行了严格的筛选,最终从六万多张样本中挑选出了5839个训练样本和519个测试样本,每个样本的分辨率为512×384。
部分数据集展示如下:

4 实验
为了证明本文方法的有效性,我们在提出的数据集(DIR-D)上对我们的方法与传统方法进行全面的对比,如定量评估、无参定量评估、定性结果比较、user study等。下图为部分视觉质量比较:


图5. 在DIR-D数据集上的视觉质量比较
除此之外,我们还在经典的图像拼接数据集上展示了从拼接到rectangling的过程来验证本文算法的泛化性,如下:

5 局限与思考
本工作从一个有监督的角度解决了拼接图矩形化的问题,但传统的图形学算法都是没有监督的,它们从一种纯优化的角度找到了使得矩形化最合理的条件,比如直线保持,平行线保持等。那么矩形化这个问题,是否也能在深度学习中找到一种对应的无监督优化目标?就像是经典的homography estimation、image stitching或者image resize问题,现在有研究者开始尝试用深度学习的方式进行实现,而其中无监督的方法(unsupervised homo、unsupervised stitching和unsupervised resize)也正是找到了无监督的优化函数。
TIP 2021 | 重访CV经典!首个无监督深度学习图像拼接框架
除此之外,该工作目前只考虑了两张图拼接的矩形化情况,然而更多图像无规则的边界会更加具有挑战性。而且,对于视频拼接的结果进行矩形化也值得进一步探索,如何在时间上稳固视频拼接矩形化的结果是非常具有实际价值的研究问题。
最后,本文的代码与数据集均已开源,欢迎各位使用、测评、讨论。
上面论文、代码和数据集下载
后台回复:拼接2022,即可下载上述论文/代码/数据集
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer6666,即可添加CVer小助手微信,便可申请加入CVer-Transformer或者目标检测 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer或者目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信: CVer6666,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看