本文介绍了马普所二年级 CS 博士生修宇亮(Yuliang Xiu)入选 CVPR 2022 的一项三维数字人姿态重建新研究 ——ICON[1]。在本文中,他将详述这项工作的来龙去脉,包括厘清本研究的动机及思维起点 (motivation)、梳理出这二十多页论文的主线、论文中没提及的洞见 (insight),并着重讲一下 ICON 的局限及改进思路。
3月17日19:00-20:00,修宇亮将带来线上分享,详细介绍本篇工作,直播详情见文末。
![]()
论文地址:https://readpaper.com/paper/4569785684533977089
GitHub 地址:https://github.com/YuliangXiu/ICON
Colab 地址:https://colab.research.google.com/drive/1-AWeWhPvCTBX0KfMtgtMk10uPU05ihoA?usp=sharing
主页地址:https://icon.is.tue.mpg.de/
首先,明确 ICON 的任务:
给一张彩色图片,将二维纸片人,还原成拥有丰富几何细节的三维数字人
。
围绕这一任务,之前有许多基于显式表达的方法 (expliclit representation: mesh[2]、voxels[3]、depth map & point cloud[4], etc)。但直到三年前 PIFu (ICCV’19)[5] 第一个把隐式表达 (implicit representation) 用到这个问题,衣服的几何细节才终于好到 —— 艺术家愿意扔到 Blender 里面玩一玩的地步。但 PIFu 有两个严重的缺陷:
速度慢和姿势鲁棒性差
。
我们在 MonoPort (ECCV’20)[6] 中一定程度上解决了「
速度慢
」这个问题,整个推理到渲染加一块,用普通显卡可以做到 15FPS 的速度。后来我们把重建和 AR 做了一个结合,用 iPad 陀螺仪控制渲染的相机位姿,最后有幸获得 SIGGRAPH Real-Time Live 的 Best Show Award。
但是「
姿态鲁棒性
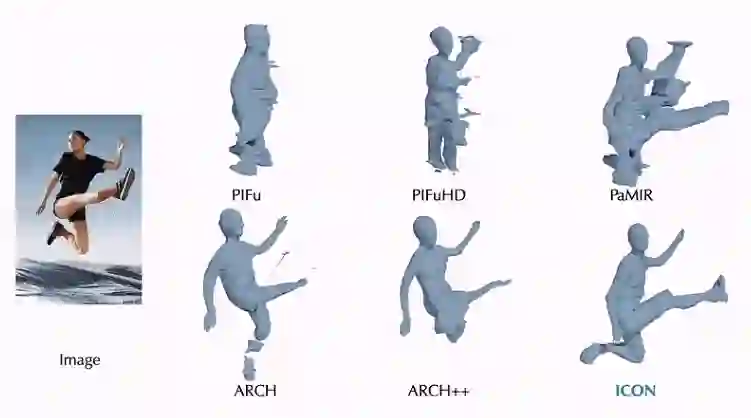
」一直没有得到很好的解决。PIFuHD[7] 将 PIFu 做到了 4K 图片上,把数字人的几何细节又提了一个档次,但还是只能在站立 / 时装姿势 (fashion pose) 下得到满意的结果。ARCH[8] 以及 ARCH++ [9] 尝试把问题从姿态空间(pose space)转换到标准空间(canonical space, 把人摆成「大」字)来解决。但这种转换,首先很依赖于姿态估计 (HPS) 的准确性,其次由于转换依赖于 SMPL 自带的蒙皮骨骼权重(skinning weights),这个权重是写死的且定义在裸体上,强行用到穿衣服的人上,由动作带动的衣服褶皱细节就不那么自然。
另外一个思路,就是加
几何先验 (geometric prior)
。通俗点说,就是我给你一个粗糙的人体几何,然后根据图像信息,来雕琢出来一个细致的人体几何。GeoPIFu (+estimated voxel)[10]、PaMIR (+voxelized SMPL)[11]、S3 (+lidar)[12] 都有做尝试。我尝试过直接把准确的几何先验 (groundtruth SMPL) 灌给 PaMIR,但 PaMIR 依旧不能在训练集中没见过的姿态上(比如舞蹈、运动、功夫、跑酷等)重建出满意的结果。
![]()
提高姿势水平是为了彻底打通基于图像的重建(image-based reconstruction)和基于扫描的建模(scan-based modeling)。
随着 NASA[13]、SCANimate[14]、SNARF[15]、MetaAvatar[16]、Neural-GIF[17] 等一系列工作爆发,如何从动态的三维人体扫描 (3D human scan sequences / 4D scans) 中学出来一个可以被驱动的、用神经网络表达的数字人 (animatable neural avatar) 渐渐成为一个研究热点。而高质量的动态人体扫描的获得,费钱费人工,导致普通用户或者没有多视角采集设备的团队,很难进入这个领域。
![]()
图左为 4D 扫描设备(MPI),图右 Light Stage(USC-ICT)。
问题来了,有没有可能扔掉昂贵且费时费力的扫描流程,用 PIFu 从视频中做逐帧重建(Images to Meshes),然后把重建结果直接扔给 SCANimate 做建模呢(Meshes to Avatar)呢?
![]()
在理论上当然是可以的,但是现实却很骨感。症结在于,现有的重建算法,都没有办法在很多样的姿态下保持重建的稳定性。
但是,数量足够多且姿势各异的三维人体却是 SCANimate 构建高质量可驱动数字人的必要前提!这个不难理解 —— 要让一个数字人无论怎么动弹,衣服裤子的褶皱都很真实,如果用数据驱动的思路去做,那么网络得先「看过足够多」类似动作下衣服的形变,才能准确摸索出衣服形变与动作姿势之间的关联。
总而言之,真要把 Images-Meshes-Avatar 这条路走通,非提高姿势水平不可。
![]()
ICON 在思路上借鉴了很多相关工作,比如 PIFuHD 里面的法向图(Normal Image),并和 PaMIR 一样都用了 SMPL body 做几何空间约束。这两个信息都是不可或缺的:SMPL body 提供了一个粗糙的人体几何,而法向图则包含了丰富的衣服褶皱细节,一粗一细,相得益彰。
![]()
RGB Image - Normal Image (Body) - Normal Image (Clothed Human)
SMPL 辅助 normal 预测。pix2pix 地从 RGB 猜 normal,要在不同姿态上做到足够泛化,就需要灌进去大量的训练数据。但是,既然 SMPL body 已经提供了粗糙的人体几何,这个几何也可以渲染成 body normal 的形式,那么如果我们把这个 body normal 和 RGB 合并一下,一块扔进网络作为输入, pix2pix 的问题就可以转化为一个新问题:用 RGB 的细节信息对粗糙的 body normal 进行形变(wraping)和雕琢(carving)最后获得 clothed normal。而这个问题的解决,可以不依赖于大量训练数据;
normal 帮助优化 SMPL。既然 clothed normal 可以从图像中攫取到 SMPL body 没有的几何细节,那么有没有可能用这些信息去反过来优化 SMPL body ?这样,SMPL body 和 clothed normal 就可以相互裨益迭代优化,body mesh 准了,normal image 就对;normal image 对了,反过来还可以进一步优化 body mesh。1+1>2,实现双赢;
舍弃 global encoder。最后,SMPL body 和 clothed normal 都有了,即人大致的体型和衣服几何细节都有了,我们真的需要像 S3、PaMIR、GeoPIFu 那样,使用一个巨大的全局卷积神经网络(2D/3D global CNN)来提特征,然后用 Implicit MLP 雕琢出穿衣人的精细外形吗?ICON 的答案是:不需要,SDF is all you need。
有了 SMPL body(左边,w/ Prior)的加持,clothed normal 预测更准确。
![]()
让 clothed normal 来优化 SMPL(第二列),同时更好的 SMPL 也提升了 clothed normal 的质量(第三列)。
![]()
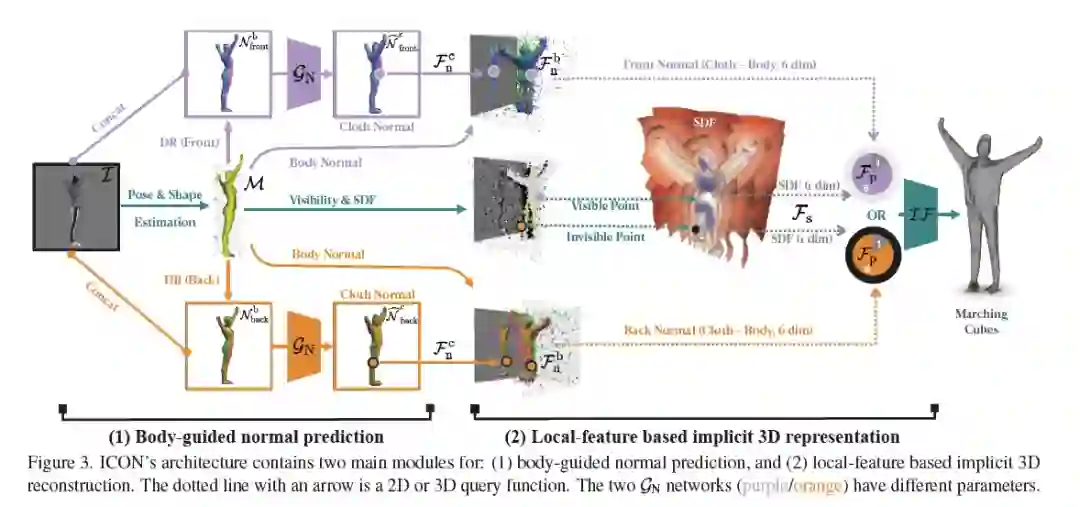
下面这张图展示了
ICON 整体处理 pipeline
。先从图像中预测 SMPL body,渲染出正反 body normal,与原始图像合并起来,过一个法向预测网络,出正反 clothed normal。然后对于三维空间中的点,clothed normal 取三维,body normal 上取三维(注意,这里是从 SMPL mesh 上用最近邻取的,而不是从 body normal image 中取的),SDF 取一维,一共七维,直接扔进 implict MLP,Marching Cube 取一下 0.5 level-set 等值面。
![]()
量化指标这里就不放了。为了确保比较的绝对公平,我除了用原作者放的模型在测试集上跑了结果,还在 ICON 的框架内重新复现了 PIFu、PaMIR。此外,我确保除了方法本身的差异,其他部分(训练数据、优化策略、网络结构)都保持一致,不引入干扰变量。实验结论显示,ICON 是 SOTA,在离谱的姿势下优势明显,训起来省数据。SMPL 不准的时候,加上迭代优化那个模块,甚至要比 PaMIR 直接在精准 SMPL 上的结果还要好。
现在放出来的代码只包括测试代码,但完整的训练代码已经在路上。ICON 包括了 PIFu、PaMIR 以及 ICON 各种变种的测试 + 训练代码,而且使用了 PyTorch-Lightning 框架做代码规范。这样以后大家要用自己的数据在 ICON、PIFu 和 PaMIR 上做训练和测试,只需要基于 ICON 调整就行。
![]()
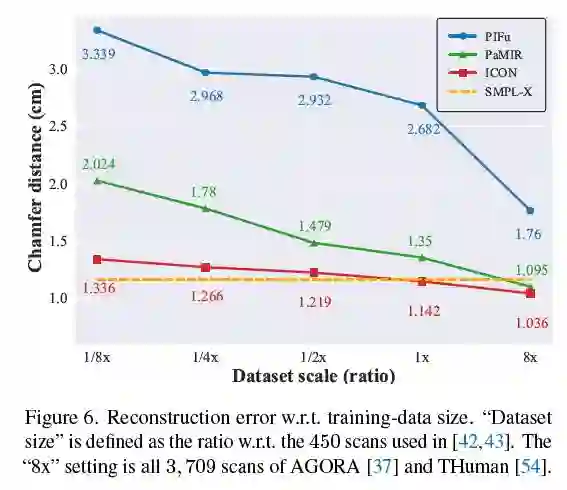
下面这张图证明了
ICON 的一个特别突出的优势,就是省钱
。毕竟 RenderPeople 一个就几百块人民币,实在离谱。仅仅给 1/8 的训练数据(50 个 3D human scan),ICON 重建的质量就可以超过用接近 4000 个训练数据训出来的 PIFu,也超过了用 450 个数据训出来的 PaMIR。作为一个舍弃了 global CNN 的极其 local 的模型,ICON 对训练数据量确实不敏感。而恰恰就是这种钝感,对于提高三维人重建的姿势水平至关重要。
![]()
为了充分测试 ICON 在非常难的姿势上是什么水平,我从 pinterest 上找了一些动作非常离谱的图片,武术、跑酷、舞蹈以及体育等等。总之,这些动作从未出现在训练集中,也不可能成为训练集(动作转瞬即逝,没法稳定住用仪器进行扫描捕捉)。但结果是令人欣慰的,尽管不完美,但至少还是个人形。
![]()
![]()
最后,我们按照之前计划的,把 Images-Meshes-Avatar 的流程跑了一下,结果还不错。
![]()
ICON 确实可以提高姿势水平,但不是尽善尽美。接下来聊聊 ICON 的劣势。
其实原论文及补充材料中对「坏结果」的分析和呈现 (Fig.7 和 Fig.18),已然不怎么遮掩了。虽然 ICON 在量化指标上实现了 SOTA,但对本领域相关研究者而言,
「坏结果」往往比「好结果」更能揭示方法的原理和本质。
![]()
鱼和熊掌不可得兼。SMPL prior 带来了稳定性,但也破坏了 implicit function 原有的优势 —— 几何表达的自由性。因此,对于那些离裸体比较远的部分,比如两腿之间的裙子、随风飞扬的外套,就「挂」了。而这些部分,最原始的 PIFu 不见的做的比 ICON 差,毕竟 PIFu 是没有引入任何几何先验的。总之,稳定性 vs 自由度,是一个 tradeoff;
慢。SMPL-normal 迭代优化的设计思路,导致单张图要跑 20s 才能出来不错的结果,实时性大大折扣;
性能天花板受制于 HPS。重建结果受 SMPL 准确性影响极大,SMPL-Normal 的迭代优化,并不能彻底解决严重的姿势估计错误。ICON 现在支持 PyMAF[18]、PARE[19] 以及 PIXIE[20] 三种 HPS,PARE 对遮挡好一些。PIXIE 手和脸准一些,PyMAF 最稳定,但依旧对一些很难的 case 束手无策。所以,尽管 HPS 已经做得很多了,围绕各种 corner case 每年能出数百篇论文,但我们依然不能说这个问题解决了,也不能说这个问题没有价值了。至少,对于 ICON 而言,HPS 的准确度是一切的基础,HPS 挂了,再怎么迭代优化也没用;
几何比法向差。clothed normal 的质量与最终重建的人体几何质量之间有 gap。normal 明明看起来很好,但 geometry 的质量就打了折扣。理论上,重建人体渲染出来的 normal image 和网络预测出来的 clothed normal 不应该有那么大差距。这块我还在 debug,希望下一个版本可以修复。
![]()
基于 ICON,接下来还可以在以下几个方向进行改进:
ICON++,进一步提升 ICON 的重建质量,更快更细节更稳定更泛化更通用;
把 ICON 用到别的任务中,比如做动物姿态,比如用 ICON 做个数据集,基于数据集建个生成模型;
Wildvideo-ICON、Multiview-ICON 和 Multiperson-ICON;
扔掉 3D supervision、非监督、自监督,以及训练范式的改进,比如 E2E-ICON。
如果有同学对这些方向有兴趣,我非常欢迎各种形式的合作(yuliang.xiu@tuebingen.mpg.de)。
Google Colab 支持上传并测试你自己的图片,最后会生成类似下图这样的重建视频,你可以将视频上传到 twitter 并打上#ICON的标签,@yuliangxiu,无论结果是好是坏,我都会转发,对于重建任务,cherry picks 和 failure cases 都是算法的一部分,好的烂的都放出来,才是一次完整的作品呈现,期待大家奇形怪状的重建结果。另外,Readpaper 这个产品非常吼,大家如果有关于ICON的问题,可以直接在Readpaper上提问:
https://readpaper.com/paper/4569785684533977089
。
![]()
Image - Normal Estimation - Reconstructed Mesh (w/o smooth, w/ smooth)
知乎原文:https://zhuanlan.zhihu.com/p/477379718
![]()
分享主题:ICON:提高三维数字人重建的姿势水平
分享嘉宾:修宇亮,德国马克斯·普朗克研究所智能系统系,二年级博士生,玛丽居里学者,导师 Michael J.Black,现研究方向为,基于图像和视频的三维人体数字化。转到马普所之前,曾为美国南加州大学计算机系博士生,导师 Hao Li。2019年于上海交通大学计算机系取得硕士学位,导师卢策吾,研究方向为二维人体姿态估计与跟踪, AlphaPose 的主要贡献者之一。本科毕业于山东大学数字媒体技术专业。
分享摘要:以假乱真的数字虚拟人,是构建Metaverse的基础组件。现有的数字人制作流程,需要昂贵的三维扫描设备以及大量的人工后处理,费时费力费钱,因此如何从互联网上现有的照片或视频中,规模化地生产高质量数字虚拟人,成为一个学界和业界都在关心的问题。在这次分享中,我将介绍我们CVPR 2022的新工作ICON,ICON可以直接将图像中的纸片人,还原成几何细节丰富的三维数字虚拟人,具有训练高效,泛化能力强,重建效果稳定等优势。
直播时间:3 月 17 日 19:00-20:00
直播间:关注机动组视频号,3 月 17 日开播。
![]()
直播群:识别下方二维码,即可加入本次直播交流群。
如群已超出人数限制,请添加机器之心小助手:syncedai2、syncedai3、syncedai4 或 syncedai5,备注「数字人」即可加入。
1. Xiu, Yuliang, et al. "ICON: Implicit Clothed humans Obtained from Normals." arXiv preprint arXiv:2112.09127 (2021).
2. Zhu, Hao, et al. "Detailed human shape estimation from a single image by hierarchical mesh deformation." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019.
3. Zheng, Zerong, et al. "Deephuman: 3d human reconstruction from a single image." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019.
4. Gabeur, Valentin, et al. "Moulding humans: Non-parametric 3d human shape estimation from single images." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019.
5. Saito, Shunsuke, et al. "Pifu: Pixel-aligned implicit function for high-resolution clothed human digitization." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019.
6. Li, Ruilong, et al. "Monocular real-time volumetric performance capture." European Conference on Computer Vision. Springer, Cham, 2020.
7. Saito, Shunsuke, et al. "Pifuhd: Multi-level pixel-aligned implicit function for high-resolution 3d human digitization." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020.
8. Huang, Zeng, et al. "Arch: Animatable reconstruction of clothed humans." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020.
9. He, Tong, et al. "ARCH++: Animation-ready clothed human reconstruction revisited." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
10. He, Tong, et al. "Geo-pifu: Geometry and pixel aligned implicit functions for single-view human reconstruction." Advances in Neural Information Processing Systems 33 (2020): 9276-9287.
11. Zheng, Zerong, et al. "Pamir: Parametric model-conditioned implicit representation for image-based human reconstruction." IEEE transactions on pattern analysis and machine intelligence (2021).
12. Yang, Ze, et al. "S3: Neural shape, skeleton, and skinning fields for 3D human modeling." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.
13. Deng, Boyang, et al. "NASA neural articulated shape approximation." European Conference on Computer Vision. Springer, Cham, 2020.
14. Saito, Shunsuke, et al. "SCANimate: Weakly supervised learning of skinned clothed avatar networks." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.
15. Chen, Xu, et al. "SNARF: Differentiable forward skinning for animating non-rigid neural implicit shapes." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
16. Wang, Shaofei, et al. "Metaavatar: Learning animatable clothed human models from few depth images." Advances in Neural Information Processing Systems 34 (2021).
17. Tiwari, Garvita, et al. "Neural-GIF: Neural generalized implicit functions for animating people in clothing." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
18. Zhang, Hongwen, et al. "Pymaf: 3d human pose and shape regression with pyramidal mesh alignment feedback loop." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
19. Kocabas, Muhammed, et al. "Pare: Part attention regressor for 3d human body estimation." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
20. Feng, Yao, et al. "Collaborative Regression of Expressive Bodies using Moderation." 2021 International Conference on 3D Vision (3DV). IEEE, 2021.
机器之心 · 机动组
机动组是机器之心发起的人工智能技术社区,聚焦于学术研究与技术实践主题内容,为社区用户带来技术线上公开课、学术分享、技术实践、走近顶尖实验室等系列内容。机动组也将不定期举办线下学术交流会与组织人才服务、产业技术对接等活动,欢迎所有 AI 领域技术从业者加入。