算不对就用各种方法多算几遍,中间步骤也检查一下,原来这套教学方法对大模型也管用。
大型语言模型在解决算术推理任务时性能欠佳,经常提供错误的答案。与自然语言理解不同,数学问题通常只有一个正确答案,这使得生成准确解决方案的任务对大型语言模型来说更具挑战性。
为了在一定程度上解决这类问题,来自微软的研究者从人类解决数学问题的方式中获得灵感,将其分解为更简单的多步骤程序,并在每个步骤中利用多种方式来验证他们的方法。
![]()
论文链接:https://arxiv.org/pdf/2303.05398.pdf
具体来说,给定一个问题 Q,然后执行以下几个步骤:
1、生成代数模板:研究者首先生成其对应的代数表达式 Q_t,用变量替换数字项。
2、Math-prompt:然后,他们向大型语言模型提供多个 prompt P,这些 prompt 可以以不同的方式分析解决 Q_t。例如,P 可以是「推导出一个代数表达式」或「编写一个 Python 函数」等等。按照这个程序,我们最终会得到 P 的表达式,它根据 Q_t 的变量解析地求解 Q_t。
3、计算验证:通过给 Q_t 变量分配多个随机值来评估 P 的解析解。
4、统计学意义:如果 P 的解析函数的解在 N∼5 个不同的变量选择上处于「一致」状态,那么将 Q 中的原始值替换为最终解。如果不「一致」,重复步骤(II)、(III)和(IV)。
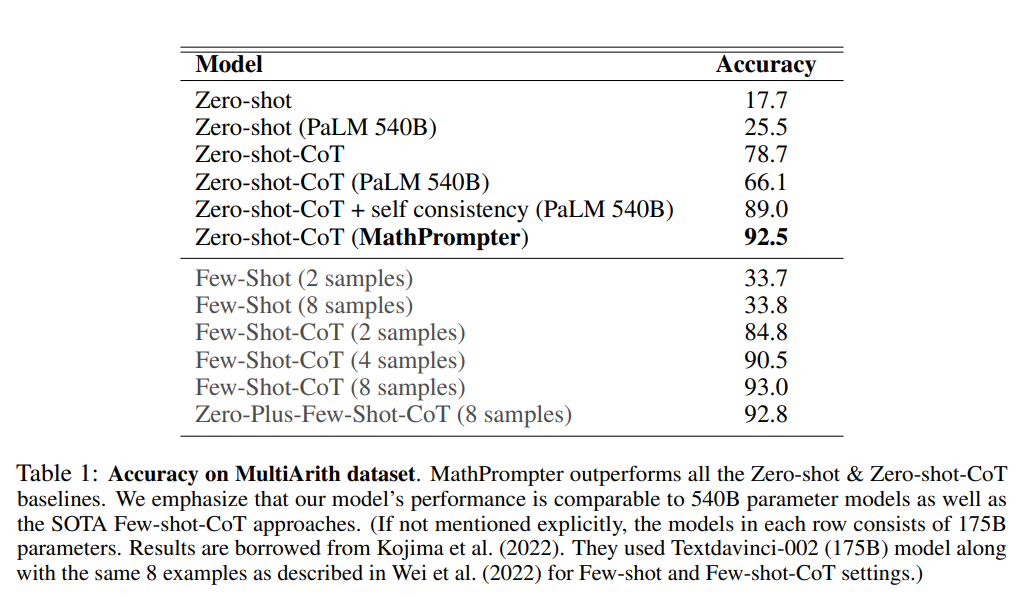
这篇论文提出的方法 ——MathPrompter,使用了 175B 参数量的大型语言模型 ——GPT3 DaVinci completion engine,能够将模型在 MultiArith 数据集上的准确率从 78.7% 提升到 92.5%。
由于大型语言模型是生成模型,要确保生成的答案是准确的就变得非常棘手,特别是对于数学推理任务。研究者从学生解决算术问题的过程中获得启发。他们缩小了学生为验证他们的解决方案而采取的几个步骤,即:
与已知结果相一致。通过将解决方案与已知的结果进行比较,可以评估其准确性并进行必要的调整。当问题是一个有既定解的标准问题时,这一点尤其有用。
多重验证。从多个角度处理问题并比较结果有助于确认解的有效性,确保其既合理又准确;
交叉检查。解决问题的过程与最终的答案一样必要。核实过程中的中间步骤的正确性,可以清楚地了解解的背后的思维过程。
计算验证。利用计算器或电脑进行算术计算可以帮助验证最终答案的准确性。
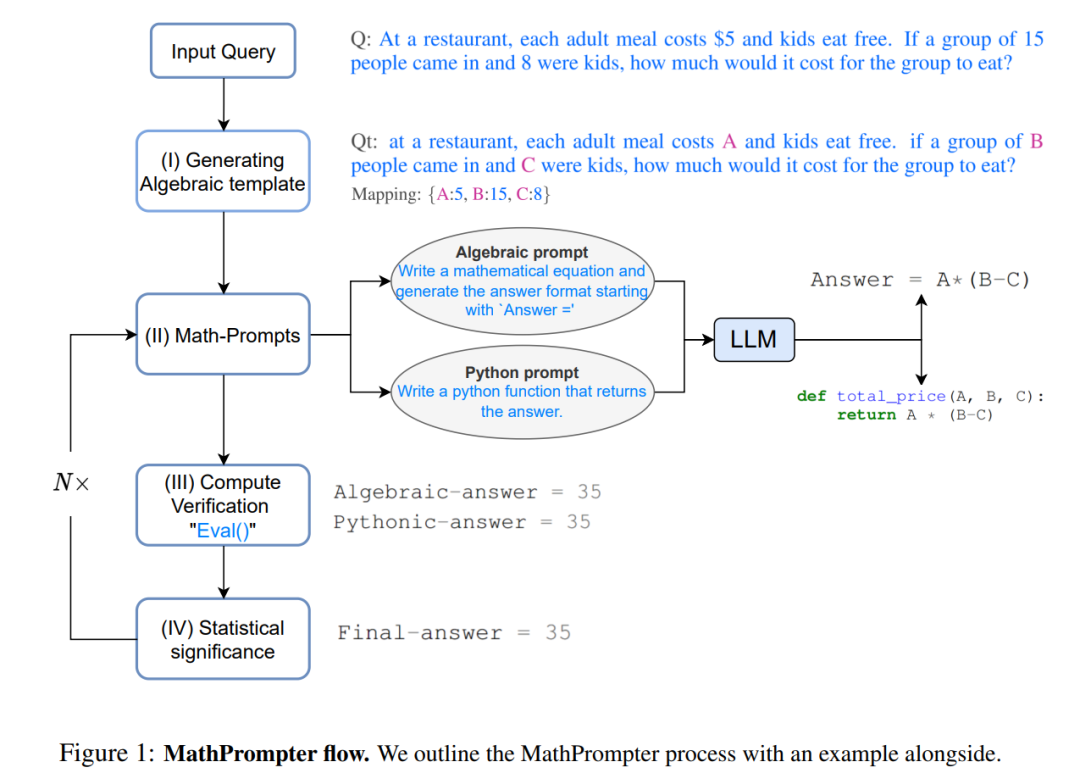
本文提出的方法 ——MathPrompter,就是试图将这种思维过程的一部分转移到大型语言模型答案生成过程中。图 1 概述了 MathPrompter 解决一个数学推理问题所遵循的步骤。
研究者使用最先进的 GPT-3 DaVinci completion engine 来完成问答任务。他们使用 MultiArith 数据集中的以下问题「Q」来演示 MathPrompter 的解题过程:
问:
在一家餐厅,每份成人餐的价格是 5 美元,儿童免费用餐。
如果有一个 15 人的团体进来,其中 8 个是儿童,那么这个团体要花多少钱吃饭?
第一步:生成代数模板。首先将问题转化为代数形式,通过使用键值映射将数字替换为变量。在这个例子中,修改后的问题「Q_t」变成了:
Q_t:在一家餐厅,每份成人餐的价格是 A 美元,儿童免费用餐。如果有一个 B 人的团体进来,其中 C 个是儿童,那么这个团体要花多少钱吃饭?
第二步:Math-prompt。受到上面提到的多重验证和交叉检查思维过程的启发,研究者使用两种不同的方法生成 Q_t 的解析解,即代数方式和 Python 方式。他们给大型语言模型以下 prompt,以便为 Q_t 生成额外的上下文:
代数 prompt:写一个数学方程并生成以 “answer =” 格式开头的答案。
Python prompt:编写一个返回答案的 Python 函数。
大型语言模型在回应上述 prompt 时产生了以下输出表达式:
上面生成的解析解给用户提供了一些信息,让他们了解大型语言模型的「中间思维过程」。加入额外的 prompt 将提高结果的准确性和一致性。这将反过来提高 MathPrompter 生成更精确和有效的解的能力。
第三步:计算验证。研究者使用 Q_t 中输入变量的多个随机键值映射来评估上一步生成的表达式。为了评估这些表达式,研究者使用了 Python 的 eval () 方法。他们比较输出结果,看能否在答案中找到一个共识。这也提高了他们对答案正确性、可靠性的信心。一旦表达式在输出上达成一致,他们就使用输入 Q 中的变量值来计算最终的答案,如下所示:
第四步是统计重要性。为了确保在各种表达式的输出中都能达成共识,研究者在实验中对第二、三步重复 N∼5 次,并报告观察到的最频繁的答案值。
表 1 比较了 MathPrompter 与基线模型的性能,显示了基于 few-shot 和 zero-shot 学习的方法的效果。
结果显示,MathPrompter 可以达到 92.5% 的准确率,远远高于其他 SOTA 模型。
表 2 列出了一组样本问题及其各自的输出、中间步骤和由 MathPrompter 和 SOTA 模型产生的最终答案。
该表显示了 Kojima et al. (2022) 技术的不足之处,以及可以用 MathPrompter 补救的地方,而 MathPrompter 就是为了解决这些问题而设计的。例如,生成答案的某个步骤有时会出错,这可以通过多次运行模型并报告共识结果来避免。此外,Kojima et al. (2022) 的推理步骤可能过于冗长,但 Pythonic 或 Algebraic 方法可以解决这个问题,通常需要较少的 token。此外,在推理步骤正确的情况下,最终的计算结果可能不正确。MathPrompter 通过使用 Python 的 eval () 方法函数解决这个问题。
更多细节请参见原论文。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com