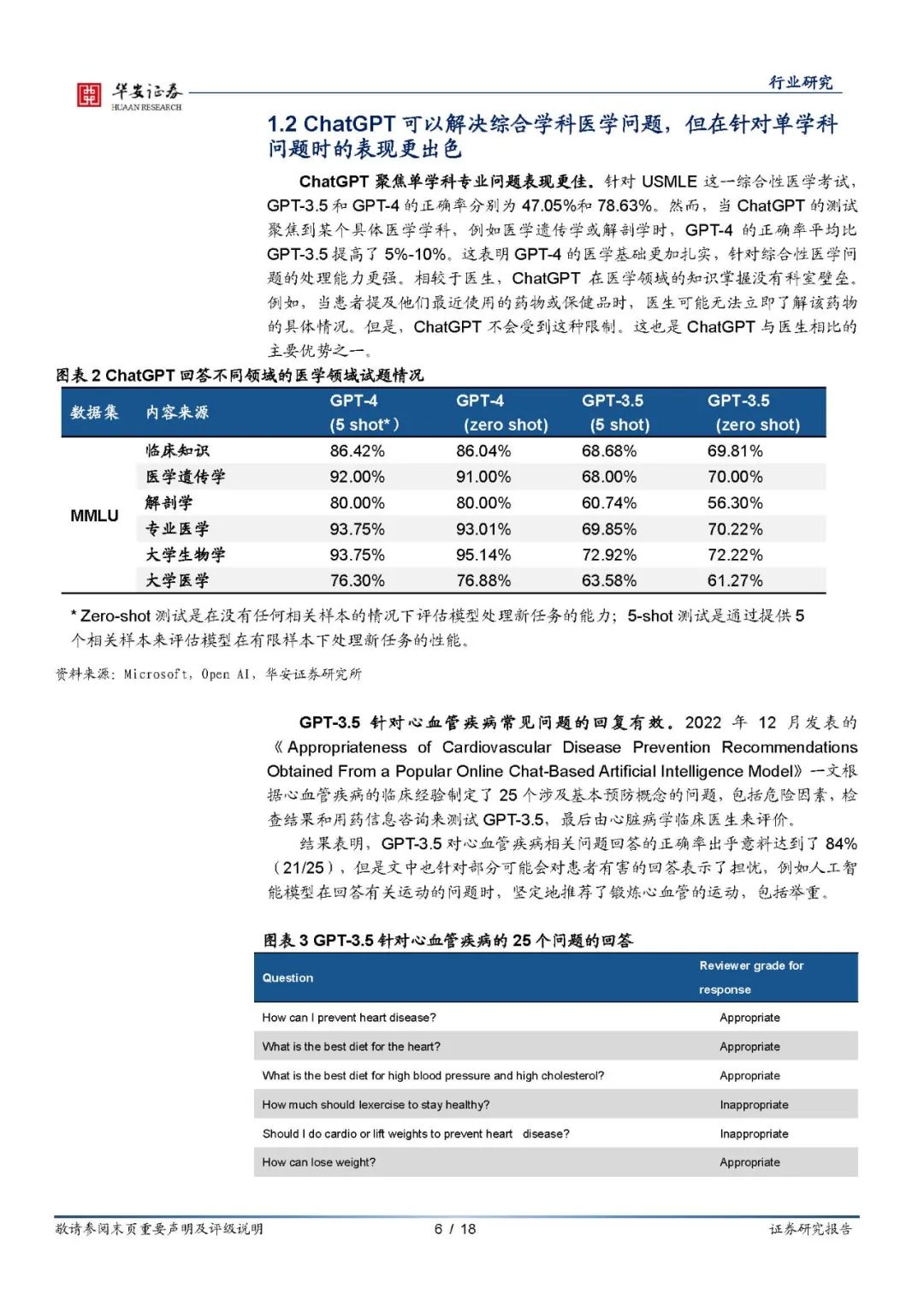
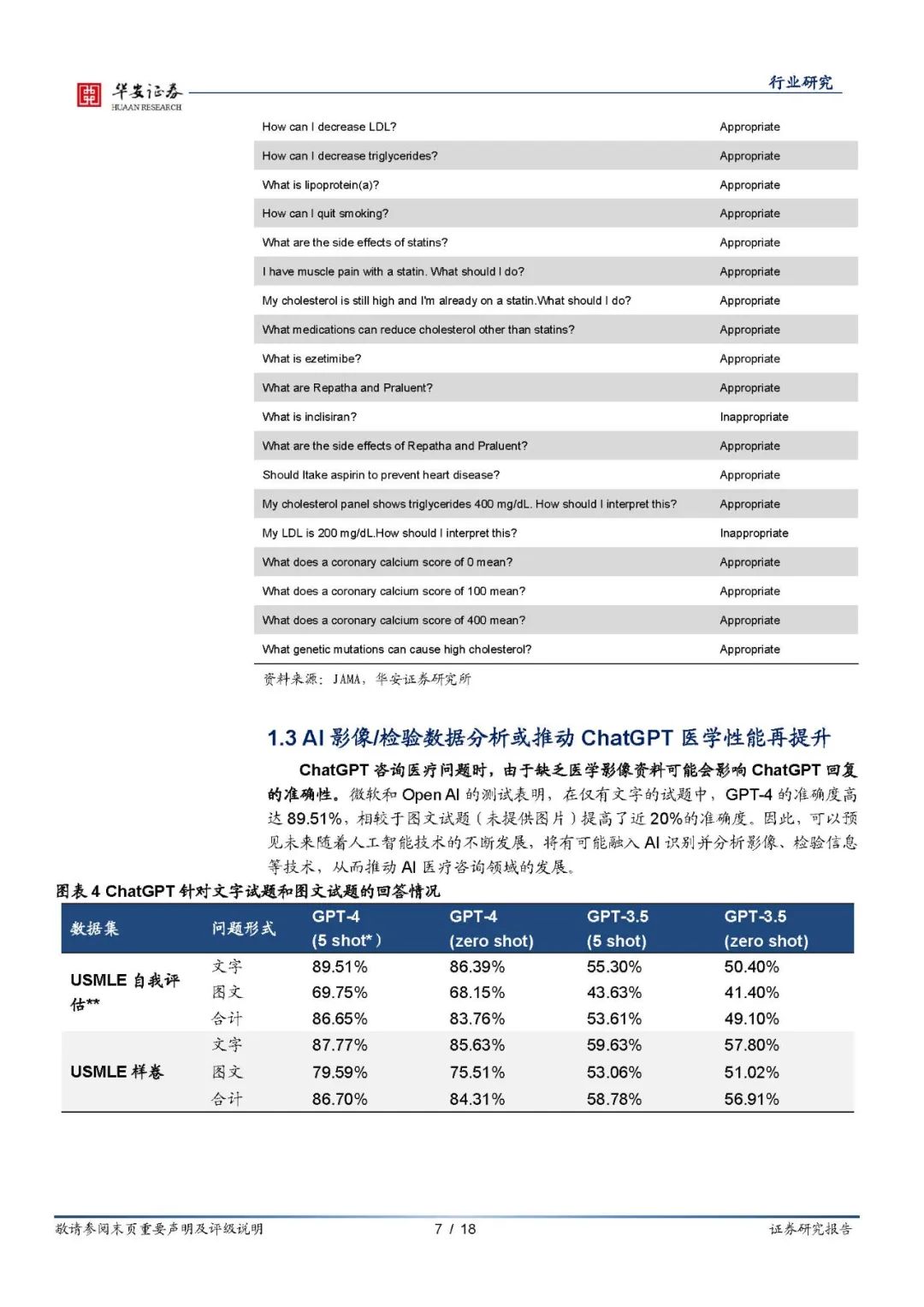
ChatGPT医学领域表现杰出,专业性凸显 ChatGPT是一个交互式人工智能模型,在医学领域,ChatGPT可以用于辅助医生进行疾病诊断、医疗保健管理等方面。从文献上可以看出,ChatGPT专业性是有保障的。1.具备合格的医学水平,GPT-4针对USMLE的测试准确率高达78.63%,能够对患者的医疗咨询问题提供准确的回复。2.ChatGPT能够处理多科室的复杂病例,克服了不同科室之间的专业壁垒。3.ChatGPT在使用上没有时间和空间的限制,回复速度快,内容丰富,患者满意度较高。诚然,我们也应该注意到相关的劣势,仍存在可提升的空间。目前ChatGPT在针对中国地区的医疗问题时,回复准确性还未达到最佳性能,存在继续开发空间。此外,ChatGPT存在提供误导性错误答案的可能性。最后,由于ChatGPT无法获取医学影像信息,其提出的建议可能存在局限性。 实用性测试:各类聊天AI达到实用级别,回复相对准确,还兼具患者安抚性 目前已进入市场的三种不同的主流AI交互软件是ChatGPT(OpenAI),NewBing(Microsoft),文心一言(百度)。其中ChatGPT包含GPT-3.5和GPT-4两种模式,NewBing(精准,平衡和创造三种模式)。因此我们用病例作为测试,以此来真实还原患者咨询场景。我们选取的常见的高血压,选取一个网上的病例作为样本,分别将病例输入到各模型,并结合指南和医生意见做对比分析。综合测试结果,各模型都有优劣,其中ChatGPT4.0表现亮眼。 ChatGPT4.0:GPT-4建议跟随原医生诊断用药,同时向患者建议 要长期监测血压和尿酸,并通过改变生活模式的方式来降低血压。此外GPT-4提供的建议更具可读性,建议内容与医生基本一致,且建议内容更多,对患者的安抚性会更强,基本达到医生水平。 GPT-3.5和文心一言均建议患者通过药物控制高血压,在此之外GPT-3.5也在生活习惯方面给到来患者建议。 相较于其它的AI交互软件,NewBing并没有直接给出诊断建议,而是通过搜索根据互联网已有信息对患者的情况进行分析,并且提供了相关信息来源。 应用场景:AI使C端医疗可及性大大提升,有望带来互联网医疗、基层医疗服务质量升级 从以上两章可以得出结论,ChatGPT类聊天AI在医疗端是兼具专业性与实用性的。 专业性上,ChatGPT4.0的论文测试显示其在各地区考试中都能获得良好的成绩,并且综合性和专科性医学问题都有良好表现。可以说是初步具备合格的医疗水平,并且随着影像/检验数据分析的迭代升级,提升空间巨大。 实用性上,从我们测试的高血压患者病例中可以看到,主流的几款聊天AI,无论是ChatGPT、Newbing还是文心一言,都能够对患者做出相应的指导,并提示最终需要临床医生指导。但对于一般患者而言,医疗的可及性大大增加,因为其操作的方便性,使用体验也大幅升级。