
机器之心报道 机器之心编辑部这就是 GPT 的「抽象」,和人类的抽象不太一样。

虽然 ChatGPT 似乎让人类正在接近重新创造智慧,但迄今为止,我们从来就没有完全理解智能是什么,不论自然的还是人工的。
认识智慧的原理显然很有必要,如何理解大语言模型的智力?OpenAI 给出的解决方案是:问问 GPT-4 是怎么说的。
5 月 9 日,OpenAI 发布了最新研究,其使用 GPT-4 自动进行大语言模型中神经元行为的解释,获得了很多有趣的结果。
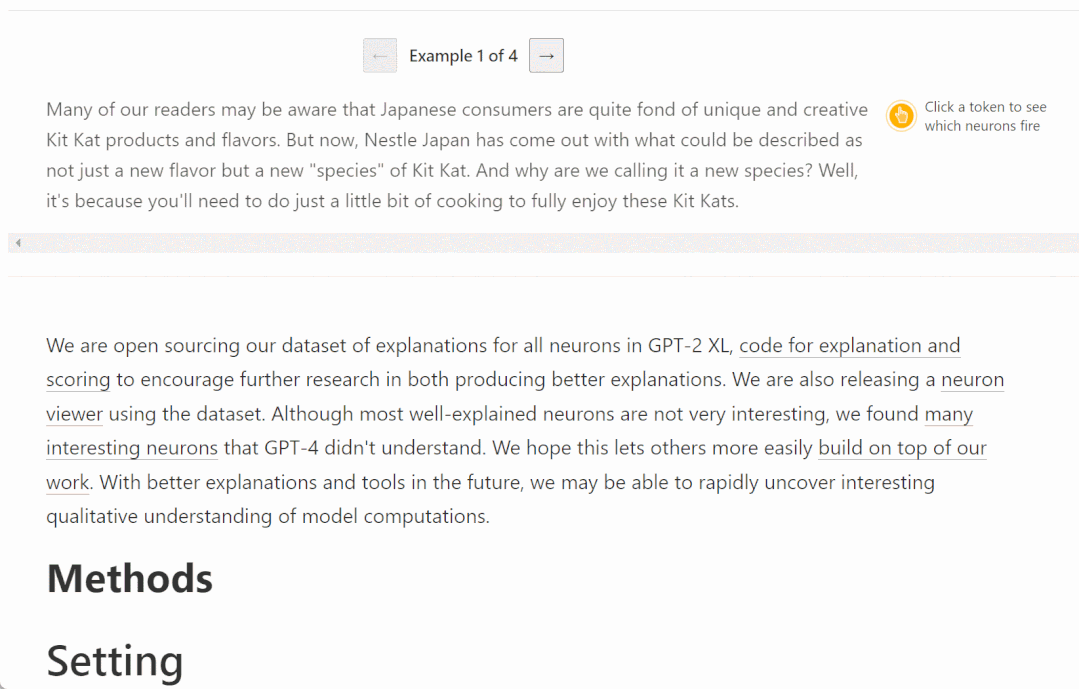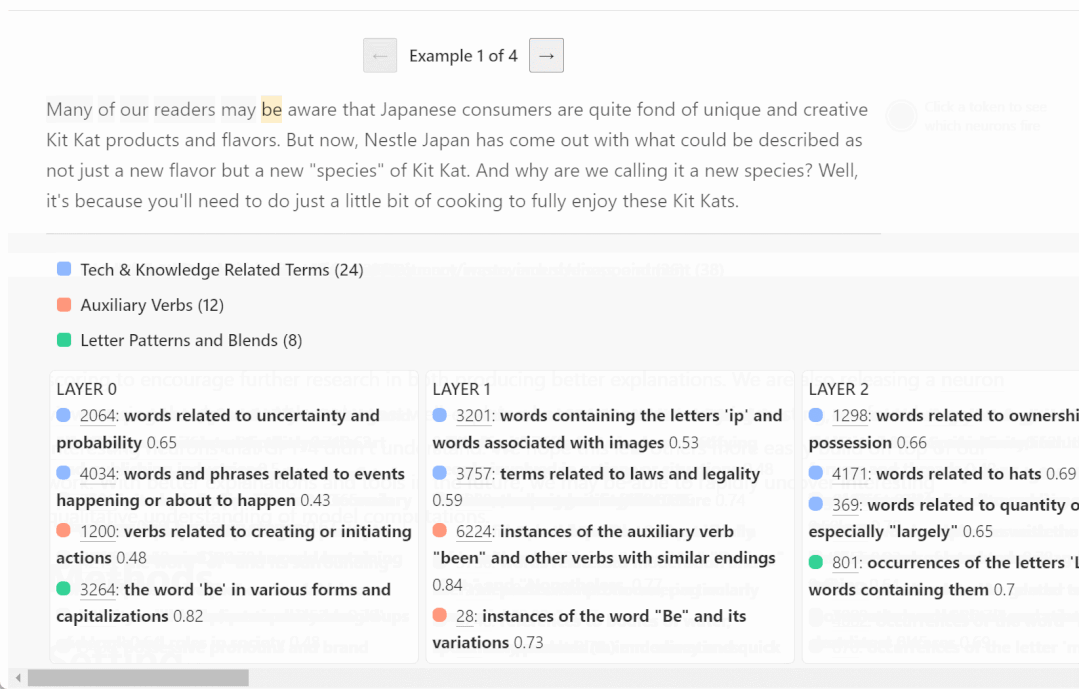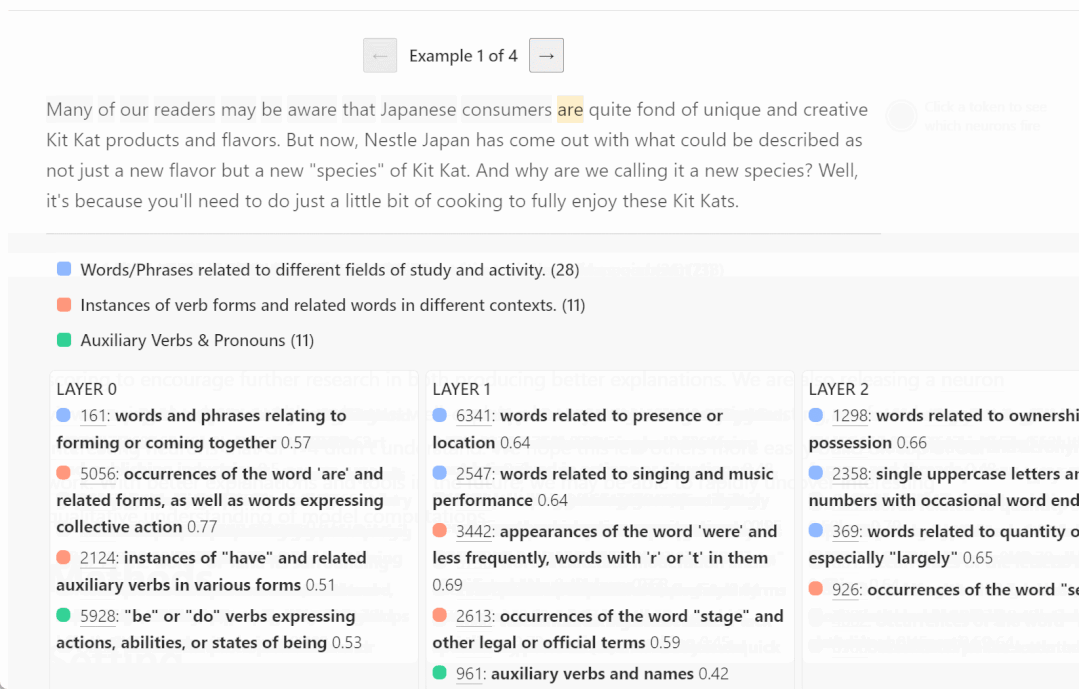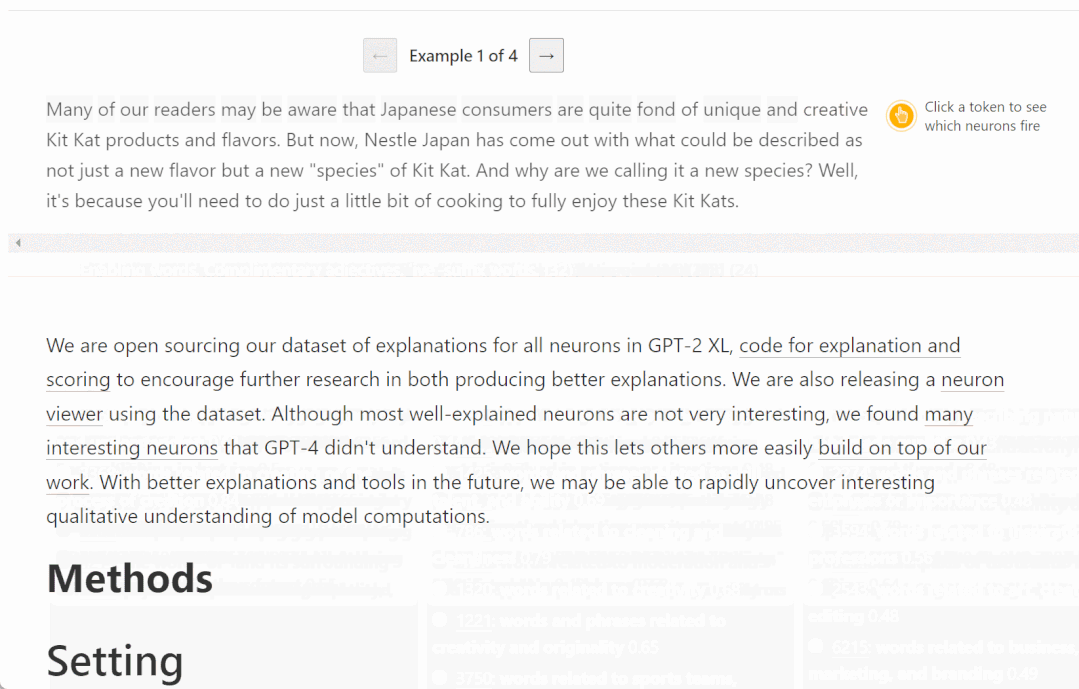
可解释性研究的一种简单方法是首先了解 AI 模型各个组件(神经元和注意力头)在做什么。传统的方法是需要人类手动检查神经元,以确定它们代表数据的哪些特征。这个过程很难扩展,将它应用于具有数百或数千亿个参数的神经网络的成本过于高昂。
所以 OpenAI 提出了一种自动化方法 —— 使用 GPT-4 来生成神经元行为的自然语言解释并对其进行评分,并将其应用于另一种语言模型中的神经元 —— 此处他们选择了 GPT-2 为实验样本,并公开了这些 GPT-2 神经元解释和分数的数据集。

- 论文地址:https://openaipublic.blob.core.windows.net/neuron-explainer/paper/index.html
- GPT-2 神经元图:https://openaipublic.blob.core.windows.net/neuron-explainer/neuron-viewer/index.html
- 代码与数据集:https://github.com/openai/automated-interpretability
这项技术让人们能够利用 GPT-4 来定义和自动测量 AI 模型的可解释性这个定量概念:它用来衡量语言模型使用自然语言压缩和重建神经元激活的能力。由于定量的特性,我们现在可以衡量理解神经网络计算目标的进展了。
OpenAI 表示,利用他们设立的基准,用 AI 解释 AI 的分数能达到接近于人类的水平。
OpenAI 联合创始人 Greg Brockman 也表示,我们迈出了使用 AI 进行自动化对齐研究的重要一步。
具体方法
使用 AI 解释 AI 的方法包括在每个神经元上运行三个步骤:
步骤一:用 GPT-4 生成解释

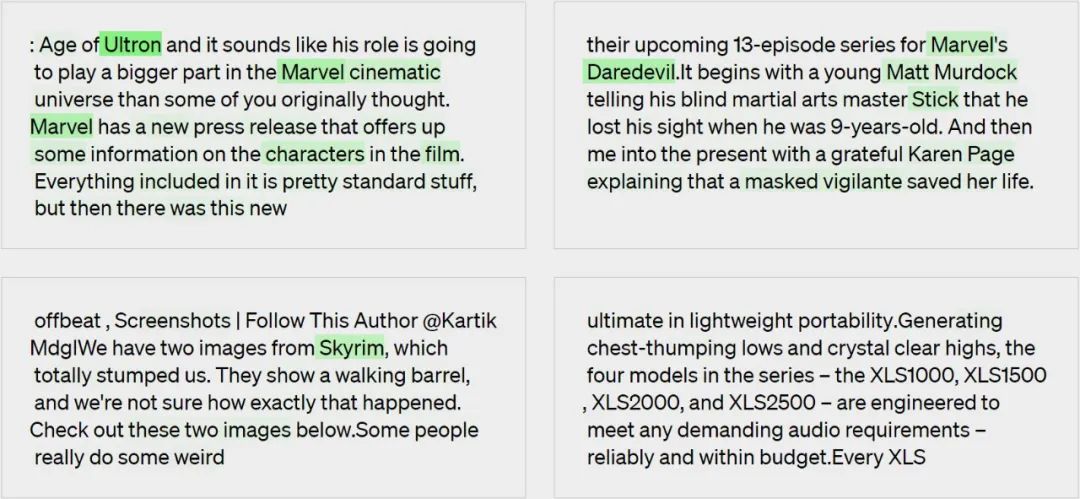
给定一个 GPT-2 神经元,通过向 GPT-4 展示相关文本序列和激活来生成对其行为的解释。
模型生成的解释:对电影、角色和娱乐的引用。
步骤二:使用 GPT-4 进行模拟
再次使用 GPT-4,模拟被解释的神经元会做什么。
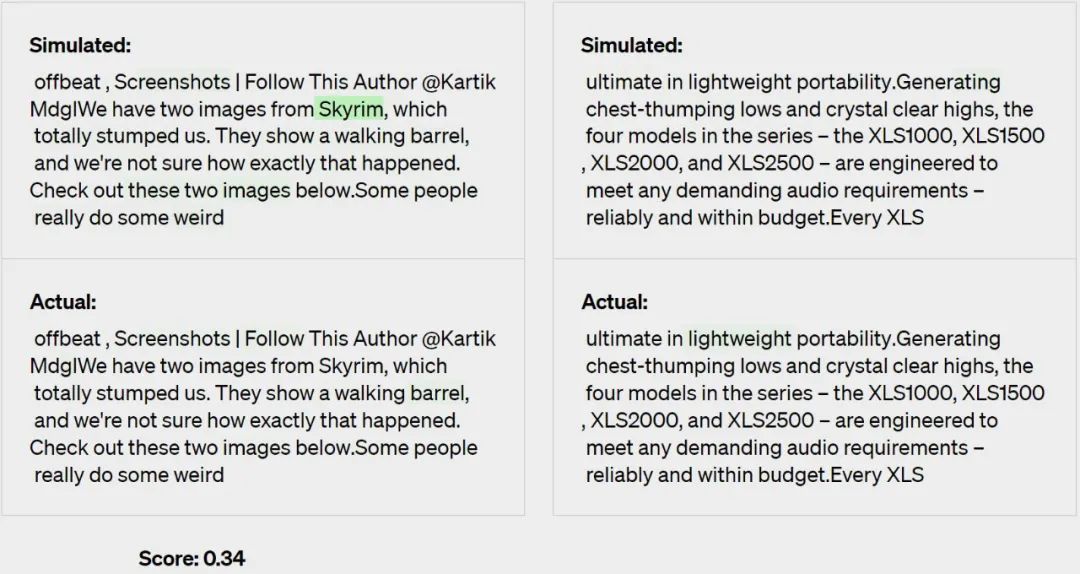
步骤三:对比
根据模拟激活与真实激活的匹配程度对解释进行评分 —— 在这个例子上,GPT-4 的得分为 0.34。

**
**
主要发现
使用自己的评分方法,OpenAI 开始衡量他们的技术对网络不同部分的效果,并尝试针对目前解释不清楚的部分改进技术。例如,他们的技术对较大的模型效果不佳,可能是因为后面的层更难解释。
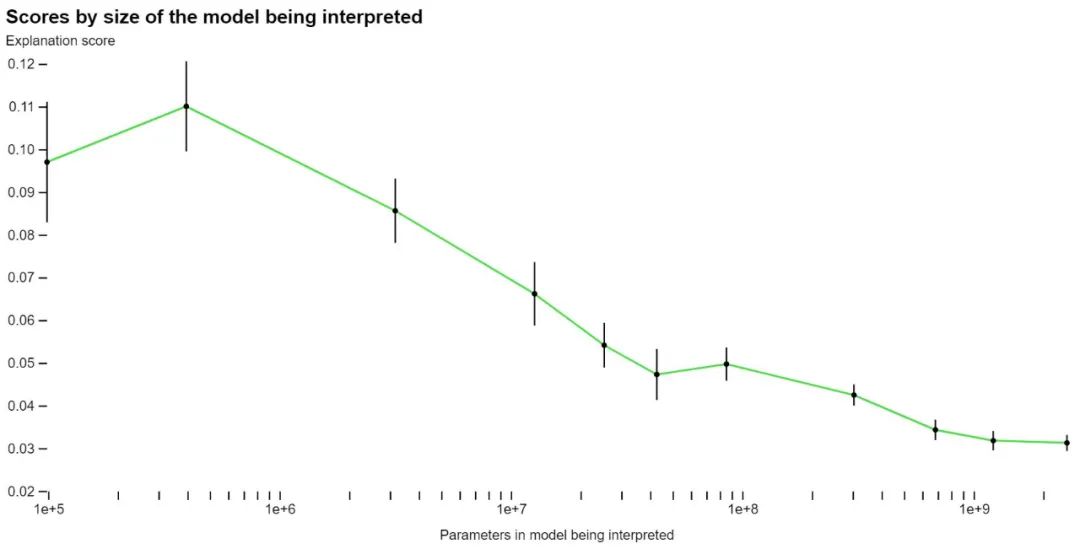
OpenAI 表示,虽然他们的绝大多数解释得分不高,但他们相信自己现在可以使用 ML 技术来进一步提高他们产生解释的能力。例如,他们发现以下方式有助于提高分数:
迭代解释。他们可以通过让 GPT-4 想出可能的反例,然后根据其激活情况修改解释来提高分数。 * 使用更大的模型来进行解释。随着解释模型(explainer model)能力的提升,平均得分也会上升。然而,即使是 GPT-4 给出的解释也比人类差,这表明还有改进的余地。 * 改变被解释模型(explained model)的架构。用不同的激活函数训练模型提高了解释分数。
OpenAI 表示,他们正在将 GPT-4 编写的对 GPT-2 中的所有 307,200 个神经元的解释的数据集和可视化工具开源。同时,他们还提供了使用 OpenAI API 上公开可用的模型进行解释和评分的代码。他们希望研究界能够开发出新的技术来生成更高分的解释,同时开发出更好的工具来通过解释探索 GPT-2。
他们发现,有超过 1000 个神经元的解释得分至少为 0.8 分,这意味着根据 GPT-4,它们占据了神经元的大部分顶级激活行为。这些得到很好解释的神经元中的大多数都不是很有趣。然而,他们也发现了许多有趣但 GPT-4 并不理解的神经元。OpenAI 希望随着解释的改进,他们可能会迅速发现对模型计算的有趣的定性理解。
以下是一些不同层神经元被激活的例子,更高的层更抽象:




看起来,GPT 理解的概念和人类不太一样?
OpenAI 未来工作
目前,该方法还存在一些局限性,OpenAI 希望在未来的工作中可以解决这些问题:
该方法专注于简短的自然语言解释,但神经元可能具有非常复杂的行为,因而用简洁地语言无法描述; * OpenAI 希望最终自动找到并解释整个神经回路实现复杂的行为,神经元和注意力头一起工作。目前的方法只是将神经元的行为解释为原始文本输入的函数,而没有说明其下游影响。例如,一个在周期(period)上激活的神经元可以指示下一个单词应该以大写字母开头,或者增加句子计数器; * OpenAI 解释了神经元的这种行为,却没有试图解释产生这种行为的机制。这意味着即使是得高分的解释在非分布(out-of-distribution)文本上也可能表现很差,因为它们只是描述了一种相关性; * 整个过程算力消耗极大。
最终,OpenAI 希望使用模型来形成、测试和迭代完全一般的假设,就像可解释性研究人员所做的那样。此外,OpenAI 还希望将其最大的模型解释为一种在部署前后检测对齐和安全问题的方法。然而,在这之前,还有很长的路要走。
参考内容: https://openai.com/research/language-models-can-explain-neurons-in-language-models https://news.ycombinator.com/item?id=35877402 https://www.reddit.com/r/MachineLearning/comments/13d4b3o/language_models_can_explain_neurons_in_language/ https://techcrunch.com/2023/05/09/openais-new-tool-attempts-to-explain-language-models-behaviors/



