跟男朋友约会也要问语言模型?Nature:提idea,总结笔记,GPT-3竟成当代「科研民工」
![]()
新智元报道

新智元报道
【新智元导读】还不会用语言模型帮忙做科研?那你可能Out啦!
让一只猴子在打字机上随机地按键,只要给足够长的时间,莎士比亚全集也能敲出来。
那要是一只懂语法和语义的猴子呢?答案是连科研都能帮你做!
语言模型的发展势头十分迅猛,几年前还只能在输入法上对下一个要输入的词进行自动补全,今天就已经可以帮助研究人员分析和撰写科学论文、生成代码了。
大型语言模型(LLM)的训练一般需要海量的文本数据作支撑。
2020年,OpenAI发布了拥有1750亿参数的GPT-3模型,写诗、做数学题,几乎生成模型能做的,GPT-3已然做到极致,即便到了今天,GPT-3仍然是很多语言模型要拿来对比和超越的基线。
GPT-3发布后,很快在Twitter和其他社交媒体上引发热议,大量研究人员对这种诡异的「类人写作」方式感到吃惊。

GPT-3发布在线服务后,用户可以随意输入文本,并让模型返回下文,每处理750个单词的收费最低仅为0.0004美元,堪称物美价廉。
最近Nature专栏科技专题上发布了一篇文章,没想到除了帮忙写小作文,这些语言模型还能帮你「做科研」!
让机器帮你思考
让机器帮你思考
冰岛大学雷克雅未克分校的计算机科学家Hafsteinn Einarsson表示:我几乎每天都会用到GPT-3,比如给论文摘要进行修改。

Einarsson在6月份的一次会议上准备文案时,虽然GPT-3提了很多无用的修改建议,但也有一些有帮助的,比如「使研究问题在摘要的开头更加明确」,而这类问题你自己看手稿时根本不会意识到,除非你让别人帮你看,而这个别人为什么不能是「GPT-3」呢?
语言模型甚至还可以帮助你改进实验设计!
在另一个项目中,Einarsson想使用Pictionary游戏在参与者中收集语言数据。
在给出了游戏的描述后,GPT-3给出了一些游戏的修改建议。理论上讲,研究人员也可以要求对实验方案进行新的尝试。
一些研究人员也会使用语言模型来生成论文标题或使文本更易读。
斯坦福大学计算机科学教授的博士生Mina Lee的使用方法是,给GPT-3输入「使用这些关键词,生成一篇论文标题」等作为提示,模型就会帮你拟定几个标题。
有部分章节如果需要重写的话,她还会用到以色列特拉维夫AI21实验室发布的人工智能写作助手Wordtune,只需要点击「Rewrite」,就能转换出多个版本的重写段落,然后进行仔细挑选即可。
Lee还会要求GPT-3为生活中的一些事提供建议,比如询问「如何把男朋友介绍给她的父母」时,GPT-3建议去海边的一家餐馆。
位于纽约布鲁克林的科技初创公司Scite的计算机科学家Domenic Rosati使用Generate语言模型对自己的思路进行重新组织。

链接:https://cohere.ai/generate
Generate由加拿大的一家NLP公司Cohere开发,模型的工作流程与GPT-3非常相似。
只需要输入笔记,或者只是随便说点idea,最后加上「总结一下」或是「把它变成一个抽象概念」,模型就会自动帮你整理思路。
何必亲自写代码?
何必亲自写代码?
OpenAI 的研究人员对 GPT-3进行了大量的文本训练,包括书籍、新闻故事、维基百科条目和软件代码。
后来,团队注意到GPT-3可以像补全普通文本一样对代码进行补全。
研究人员创建了一个名为 Codex 的算法的微调版本,使用来自代码共享平台GitHub上超过150G 的文本上进行训练;目前GitHub 现在已经将Codex 集成到 Copilot 的服务中,可以辅助用户编写代码。

位于华盛顿州西雅图的艾伦人工智能研究所AI2的计算机科学家Luca Soldaini说,他们办公室里至少有一半 的人都在用Copilot
Soldaini表示,Copilot最适合重复性编程的场景。比如他有一个项目涉及到编写处理PDF的模板代码,Copilot直接就给补全了。
不过Copilot补全的内容也会经常出错,最好在一些自己熟悉的语言上使用。
文献检索
文献检索
语言模型最为成熟的应用场景可能就是搜索和总结文献了。
AI2开发的Semantic Scholar搜索引擎使用了TLDR的语言模型对每篇论文给出了一个类似Twitter长度的描述。

该搜索引擎覆盖了大约2亿篇论文,其中大部分来自生物医学和计算机科学。
TLDR的开发基于由Meta更早发布的BART模型,然后AI2的研究人员在人写摘要的基础上对模型进行了微调。
按照今天的标准,TLDR并不是一个大型语言模型,因为它只包含大约4亿个参数,而GPT-3的最大版本包含1750亿。
TLDR在AI2开发的扩充科学论文应用程序Semantic Reader中也有应用。
当用户使用Semantic Reader中的文内引用时,会弹出一个包含TLDR摘要的信息框。
Semantic Scholar的首席科学家Dan Weld表示,我们的想法是利用语言模型来提升阅读体验。

当语言模型生成文本摘要时,模型有可能会生成一些文章中不存在的事实,研究人员将这种问题称之为「幻觉」,但实际上语言模型纯粹是在编造或撒谎。
TLDR 在真实性检验中表现较好,论文作者对TLDR的准确度评分为2.5分(满分3分)。
Weld表示,TLDR更真实是因为摘要只有大约20个单词的长度,也可能是因为算法不会将没有出现在正文中的单词放入摘要中。
在搜索工具方面,2021年在加利福尼亚州旧金山的机器学习非营利组织Ought推出了Elicit ,如果用户问它「mindfulness对决策的影响是什么?」它会输出一个包含十篇论文的表格。

用户可以要求软件在列中填写诸如摘要和元数据等内容,以及关于研究参与者、方法和结果的信息,然后使用包括 GPT-3在内的工具从论文中提取或生成这些信息。
马里兰大学帕克分校的Joel Chan的研究方向为人机交互,每当他开始一个新项目的时候都会使用Elicit搜索相关论文。
斯德哥尔摩卡罗琳学院的神经系统科学家Gustav Nilsonne还利用Elicit找到了一些可以添加到汇总分析中的数据的论文,用这个工具可以找到在其他搜索中没有发现的文件。
不断进化的模型
不断进化的模型
AI2的原型为LLM提供了一种未来的感觉。
有时研究人员在阅读科学论文的摘要后会有疑问,但还没有时间阅读全文。
AI2的一个团队还开发了一个工具,可以在NLP领域回答这些问题。
模型首先要求研究人员阅读NLP论文的摘要,然后询问相关问题(比如「分析了哪五个对话属性?」)
研究小组随后要求其他研究人员在阅读完全部论文后回答这些问题。
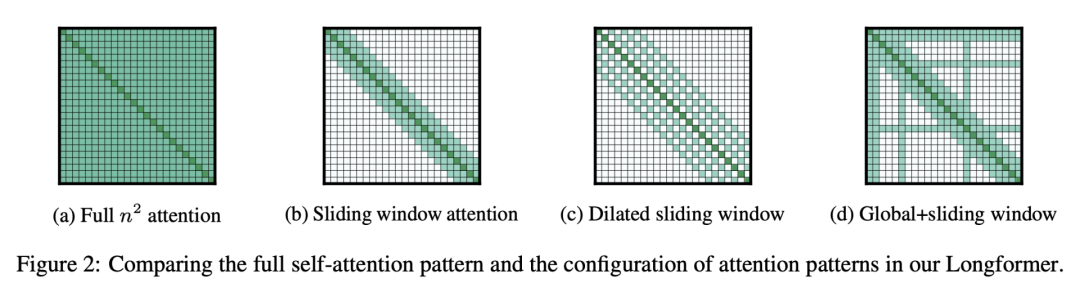
AI2训练了另一个版本的Longformer语言模型,输入为一篇完整的论文,然后利用收集的数据集生成关于其他论文不同问题的答案。
ACCoRD模型可以为150个与NLP相关的科学概念生成定义和类比。
MS2是一个包含470,000个医学文档和20,000个多文档摘要的数据集,用MS2微调BART后,研究人员就能够提出一个问题和一组文档,并生成一个简短的元分析摘要。
2019年,AI2对谷歌2018年创建的语言模型 BERT 进行了微调,在Semantic Scholar的论文上创建了拥有1.1亿个参数的 SciBERT

Scite使用人工智能创建了一个科学搜索引擎,进一步对SciBERT进行了微调,以便当其搜索引擎列出引用目标论文的论文时,将这些论文归类为支持、对比或以其他方式提到该论文。
Rosati表示这种细微差别有助于人们识别科技文献中的局限性或差距。
AI2的SPECTER模型也是基于SciBERT,它将论文简化为紧凑的数学表示。
Weld 说,会议组织者使用 SPECTER 将提交的论文与同行评审者匹配,Semantic Scholar使用它根据用户的库推荐论文。
在希伯来大学和AI2的计算机科学家Tom Hope说他们有研究项目通过微调语言模型来确定有效的药物组合、基因和疾病之间的联系,以及在COVID-19研究中的科学挑战和方向。
但是,语言模型能否提供更深入的洞察力,甚至是发现能力呢?
今年5月,Hope 和 Weld 与微软首席科学官Eric Horvitz共同撰写了一篇评论,列出了实现这一目标的挑战,包括教授模型以「(推断)重组两个概念的结果」。
Hope表示,这基本和 OpenAI 的 DALL · E 2图像生成模型「生成一张猫飞入太空的图片是一回事」,但是我们怎样才能走向结合抽象的、高度复杂的科学概念呢?

这是个开放性问题。
时至今日,大型语言模型已经对研究产生了实实在在的影响,如果人们还没有开始使用这些大型语言模型辅助工作,他们就会错过这些机会。





