BAT机器学习面试1000题系列(第11~20题)
(点击上方公众号,快速关注一起学AI)
11.谈谈判别式模型和生成式模型?
判别方法:由数据直接学习决策函数 Y = f(X),或者由条件分布概率 P(Y|X)作为预测模型,即判别模型。
生成方法:由数据学习联合概率密度分布函数 P(X,Y),然后求出条件概率分布P(Y|X)作为预测的模型,即生成模型。
由生成模型可以得到判别模型,但由判别模型得不到生成模型。
常见的判别模型有:K近邻、SVM、决策树、感知机、线性判别分析(LDA)、线性回归、传统的神经网络、逻辑斯蒂回归、boosting、条件随机场
常见的生成模型有:朴素贝叶斯、隐马尔可夫模型、高斯混合模型、文档主题生成模型(LDA)、限制玻尔兹曼机
12.L1和L2的区别
L1范数(L1 norm)是指向量中各个元素绝对值之和,也有个美称叫“稀疏规则算子”(Lasso regularization)。
比如 向量A=[1,-1,3], 那么A的L1范数为 |1|+|-1|+|3|.
简单总结一下就是:
L1范数: 为x向量各个元素绝对值之和。
L2范数: 为x向量各个元素平方和的1/2次方,L2范数又称Euclidean范数或者Frobenius范数
Lp范数: 为x向量各个元素绝对值p次方和的1/p次方.
在支持向量机学习过程中,L1范数实际是一种对于成本函数求解最优的过程,因此,L1范数正则化通过向成本函数中添加L1范数,使得学习得到的结果满足稀疏化,从而方便人类提取特征。
L1范数可以使权值稀疏,方便特征提取。
L2范数可以防止过拟合,提升模型的泛化能力。
13. CNN最成功的应用是在CV,那为什么NLP和Speech的很多问题也可以用CNN解出来?为什么AlphaGo里也用了CNN?这几个不相关的问题的相似性在哪里?CNN通过什么手段抓住了这个共性?
@许韩,来源:https://zhuanlan.zhihu.com/p/25005808
Deep Learning -Yann LeCun, Yoshua Bengio & Geoffrey Hinton
Learn TensorFlow and deep learning, without a Ph.D.
The Unreasonable Effectiveness of Deep Learning -LeCun 16 NIPS Keynote
以上几个不相关问题的相关性在于,都存在局部与整体的关系,由低层次的特征经过组合,组成高层次的特征,并且得到不同特征之间的空间相关性。如下图:低层次的直线/曲线等特征,组合成为不同的形状,最后得到汽车的表示。
CNN抓住此共性的手段主要有四个:局部连接/权值共享/池化操作/多层次结构。
局部连接使网络可以提取数据的局部特征;权值共享大大降低了网络的训练难度,一个Filter只提取一个特征,在整个图片(或者语音/文本) 中进行卷积;池化操作与多层次结构一起,实现了数据的降维,将低层次的局部特征组合成为较高层次的特征,从而对整个图片进行表示。如下图:
上图中,如果每一个点的处理使用相同的Filter,则为全卷积,如果使用不同的Filter,则为Local-Conv。
另,关于CNN,这里有篇文章《 CNN笔记:通俗理解卷积神经网络》。

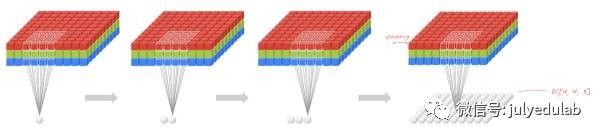
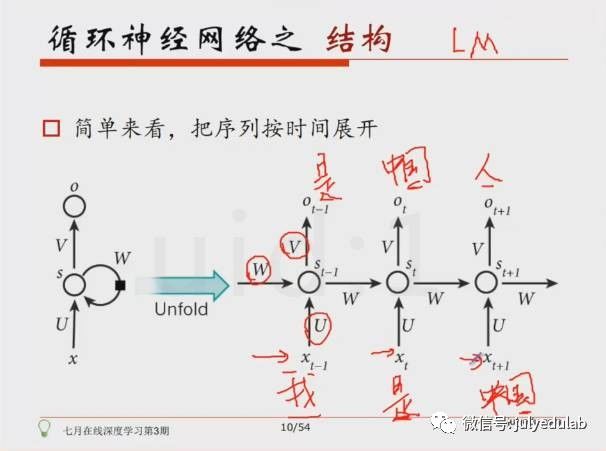
14.简单说说RNN的原理
我们升学到高三准备高考时,此时的知识是由高二及高二之前所学的知识加上高三所学的知识合成得来,即我们的知识是由前序铺垫,是有记忆的,好比当电影字幕上出现:“我是”时,你会很自然的联想到:“我是中国人”。
关于RNN,这里有个课程会详细讲RNN,此外这里也有篇讲解LSTM的文《理解 LSTM 网络》。
15. 说一下Adaboost,权值更新公式。当弱分类器是Gm时,每个样本的的权重是w1,w2...,请写出最终的决策公式。
给定一个训练数据集T={(x1,y1), (x2,y2)…(xN,yN)},其中实例,而实例空间,yi属于标记集合{-1,+1},Adaboost的目的就是从训练数据中学习一系列弱分类器或基本分类器,然后将这些弱分类器组合成一个强分类器。
Adaboost的算法流程如下:
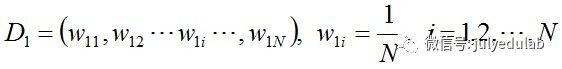
a. 使用具有权值分布Dm的训练数据集学习,得到基本分类器(选取让误差率最低的阈值来设计基本分类器):
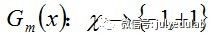
b. 计算Gm(x)在训练数据集上的分类误差率
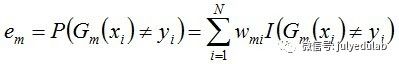
由上述式子可知,Gm(x)在训练数据集上的误差率em就是被Gm(x)误分类样本的权值之和。
c. 计算Gm(x)的系数,am表示Gm(x)在最终分类器中的重要程度(目的:得到基本分类器在最终分类器中所占的权重):
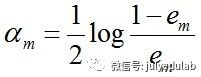
由上述式子可知,em <= 1/2时,am >= 0,且am随着em的减小而增大,意味着分类误差率越小的基本分类器在最终分类器中的作用越大。
d. 更新训练数据集的权值分布(目的:得到样本的新的权值分布),用于下一轮迭代
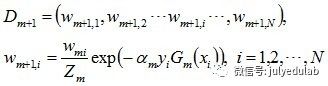
使得被基本分类器Gm(x)误分类样本的权值增大,而被正确分类样本的权值减小。就这样,通过这样的方式,AdaBoost方法能“重点关注”或“聚焦于”那些较难分的样本上。
其中,Zm是规范化因子,使得Dm+1成为一个概率分布:
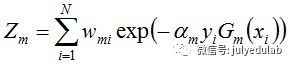
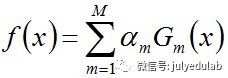
从而得到最终分类器,如下:
更多请查看此文:《Adaboost 算法的原理与推导》。
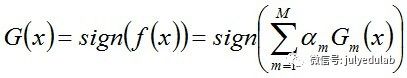
步骤3. 组合各个弱分类器
步骤2. 进行多轮迭代,用m = 1,2, ..., M表示迭代的第多少轮
步骤1. 首先,初始化训练数据的权值分布。每一个训练样本最开始时都被赋予相同的权值:1/N。
P(c)表示某个正确的词的出现"概率",它可以用"频率"代替。如果我们有一个足够大的文本库,那么这个文本库中每个单词的出现频率,就相当于它的发生概率。某个词的出现频率越高,P(c)就越大。比如在你输入一个错误的词“Julw”时,系统更倾向于去猜测你可能想输入的词是“July”,而不是“Jult”,因为“July”更常见。
P(w|c)表示在试图拼写c的情况下,出现拼写错误w的概率。为了简化问题,假定两个单词在字形上越接近,就有越可能拼错,P(w|c)就越大。举例来说,相差一个字母的拼法,就比相差两个字母的拼法,发生概率更高。你想拼写单词July,那么错误拼成Julw(相差一个字母)的可能性,就比拼成Jullw高(相差两个字母)。值得一提的是,一般把这种问题称为“编辑距离”,参见博客中的这篇文章。
E步:选取一组参数,求出在该参数下隐含变量的条件概率值;
M步:结合E步求出的隐含变量条件概率,求出似然函数下界函数(本质上是某个期望函数)的最大值。
重复上面2步直至收敛。
公式如下所示:
M步公式中下界函数的推导过程:
EM算法一个常见的例子就是GMM模型,每个样本都有可能由k个高斯产生,只不过由每个高斯产生的概率不同而已,因此每个样本都有对应的高斯分布(k个中的某一个),此时的隐含变量就是每个样本对应的某个高斯分布。
GMM的E步公式如下(计算每个样本对应每个高斯的概率):
更具体的计算公式为:
M步公式如下(计算每个高斯的比重,均值,方差这3个参数):
16.LSTM结构推导,为什么比RNN好?
推导forget gate,input gate,cell state, hidden information等的变化;因为LSTM有进有出且当前的cell informaton是通过input gate控制之后叠加的,RNN是叠乘,因此LSTM可以防止梯度消失或者爆炸
17.经常在网上搜索东西的朋友知道,当你不小心输入一个不存在的单词时,搜索引擎会提示你是不是要输入某一个正确的单词,比如当你在Google中输入“Julw”时,系统会猜测你的意图:是不是要搜索“July”,如下图所示:
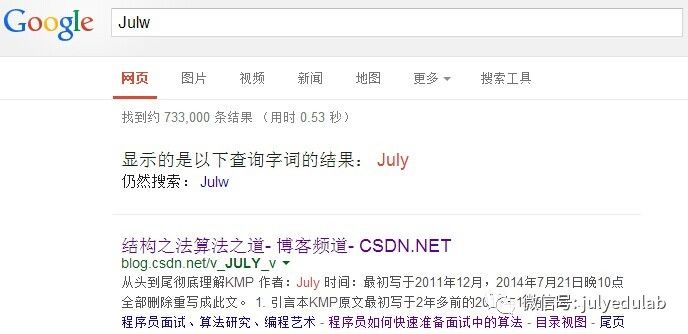
这叫做拼写检查。根据谷歌一员工写的文章显示,Google的拼写检查基于贝叶斯方法。请说说的你的理解,具体Google是怎么利用贝叶斯方法,实现"拼写检查"的功能。
用户输入一个单词时,可能拼写正确,也可能拼写错误。如果把拼写正确的情况记做c(代表correct),拼写错误的情况记做w(代表wrong),那么"拼写检查"要做的事情就是:在发生w的情况下,试图推断出c。换言之:已知w,然后在若干个备选方案中,找出可能性最大的那个c,也就是求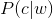
而根据贝叶斯定理,有:
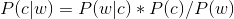
由于对于所有备选的c来说,对应的都是同一个w,所以它们的P(w)是相同的,因此我们只要最大化
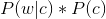
即可。其中:
所以,我们比较所有拼写相近的词在文本库中的出现频率,再从中挑出出现频率最高的一个,即是用户最想输入的那个词。具体的计算过程及此方法的缺陷请参见这里。
18.为什么朴素贝叶斯如此“朴素”?
因为它假定所有的特征在数据集中的作用是同样重要和独立的。正如我们所知,这个假设在现实世界中是很不真实的,因此,说朴素贝叶斯真的很“朴素”。
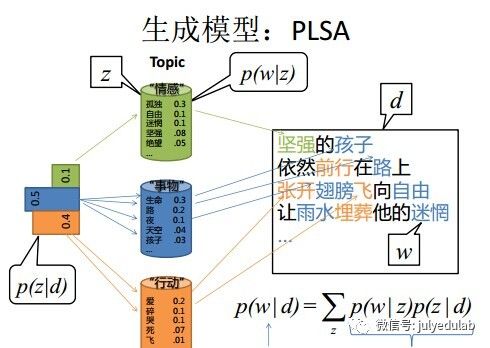
19.请大致对比下plsa和LDA的区别
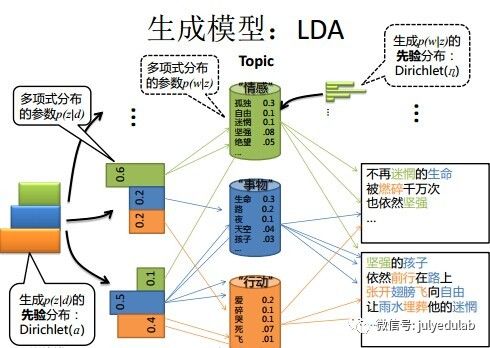
换言之,LDA在pLSA的基础上给这两参数(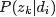
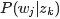
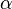
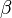
综上,LDA真的只是pLSA的贝叶斯版本,文档生成后,两者都要根据文档去推断其主题分布和词语分布,只是用的参数推断方法不同,在pLSA中用极大似然估计的思想去推断两未知的固定参数,而LDA则把这两参数弄成随机变量,且加入dirichlet先验。
更多请参见:《通俗理解LDA主题模型》。
还是再次举下文档d具体产生主题z的例子。给定一篇文档d,现在有多个主题z1、z2、z3,它们的主题分布{ P(zi|d), i = 1,2,3 }可能是{0.4,0.5,0.1},也可能是{0.2,0.2,0.6},即这些主题被d选中的概率都不再认为是确定的值,可能是P(z1|d) = 0.4、P(z2|d) = 0.5、P(z3|d) = 0.1,也有可能是P(z1|d) = 0.2、P(z2|d) = 0.2、P(z3|d) = 0.6等等,而主题分布到底是哪个取值集合我们不确定(为什么?这就是贝叶斯派的核心思想,把未知参数当作是随机变量,不再认为是某一个确定的值),但其先验分布是dirichlet 分布,所以可以从无穷多个主题分布中按照dirichlet 先验随机抽取出某个主题分布出来。如下图所示(图截取自沈博PPT上):
文档d产生主题z(准确的说,其实是Dirichlet先验为文档d生成主题分布Θ,然后根据主题分布Θ产生主题z)的概率,主题z产生单词w的概率都不再是某两个确定的值,而是随机变量。
但在贝叶斯框架下的LDA中,我们不再认为主题分布(各个主题在文档中出现的概率分布)和词分布(各个词语在某个主题下出现的概率分布)是唯一确定的(而是随机变量),而是有很多种可能。但一篇文档总得对应一个主题分布和一个词分布吧,怎么办呢?LDA为它们弄了两个Dirichlet先验参数,这个Dirichlet先验为某篇文档随机抽取出某个主题分布和词分布。
举个文档d产生主题z的例子。给定一篇文档d,主题分布是一定的,比如{ P(zi|d), i = 1,2,3 }可能就是{0.4,0.5,0.1},表示z1、z2、z3,这3个主题被文档d选中的概率都是个固定的值:P(z1|d) = 0.4、P(z2|d) = 0.5、P(z3|d) = 0.1,如下图所示(图截取自沈博PPT上):
文档d产生主题z的概率,主题z产生单词w的概率都是两个固定的值。
pLSA中,主题分布和词分布确定后,以一定的概率(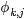
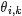
20.请简要说说EM算法
@tornadomeet,本题解析来源:http://www.cnblogs.com/tornadomeet/p/3395593.html
有时候因为样本的产生和隐含变量有关(隐含变量是不能观察的),而求模型的参数时一般采用最大似然估计,由于含有了隐含变量,所以对似然函数参数求导是求不出来的,这时可以采用EM算法来求模型的参数的(对应模型参数个数可能有多个),EM算法一般分为2步:
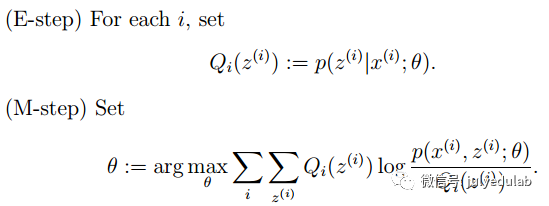
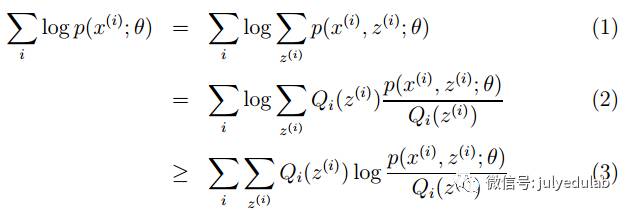
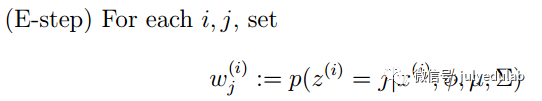
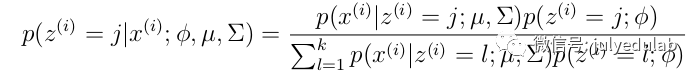

有好的见解欢迎在评论区留言,一起交流探讨。
欢迎转发,让更多小伙伴收益!





