【作者解读】ERNIE-GEN : 原来你是这样的生成预训练框架!
写在前面
今年1月,百度发布了全新的生成式预训练模型ERNIE-GEN,我们在之前的一些文章中有过介绍:『芝麻街跨界NLP,没有一个ERNIE是无辜的』、『NLP简报(Issue#4)』,但都不是很深入,今天一起看看来自paper作者对ERNIE-GEN的解读。
『ERNIE-GEN』主要针对:
-
生成训练中的“曝光偏置(exposure bias)”问题; -
如何用人类写作习惯去训练自然语言生成; -
如何在预训练中增强encoder和decoder的交互。这三个问题,提出了一种 Multi-Flow结构的预训练和微调框架。
论文中,ERNIE-GEN利用更少的参数量和数据,在摘要生成、问题生成、对话和生成式问答4个任务共5个数据集上取得了SOTA效果。
-
论文链接:https://arxiv.org/pdf/2001.11314.pdf -
开源地址:https://github.com/PaddlePaddle
Motivation
之前的生成式预训练模型如MASS、UniLM、BART等,将 Mask LM学习任务和seq2seq框架结合,在一系列生成任务上取得了显著的提升,并刷新SOTA。但这些预训练模型却很少关注自然语言生成中的一些具体的问题,对此ERNIE-GEN从以下3个问题展开了实验:
-
「曝光偏置(exposure bias)」 问题:teacher forcing的生成训练,在训练中用Ground Truth作为decoder端的输入,而解码时用之前生成的序列作为decoder端的输入,导致训练和解码的产生偏差; -
「逐字符学习」问题:传统的seq2seq训练,采用逐字符(word-by-word)的学习方式,存在1)预测时过度依赖上一个词;2)与人类写作习惯 (实体、短语甚至句子同时构思,并非单个字符) 不一致的问题; -
「Encoder和Decoder相关性减弱」问题:在自监督的seq2seq预训练中,当输入序列很长时(假如encoder和decoder各50%),那么decoder和encoder的语义相关性减弱,模型学习将逐渐退化为Language Modeling。
针对以上3个问题,ERNIE-GEN提出一套基于Multi-Flow attention结构的预训练和微调框架:
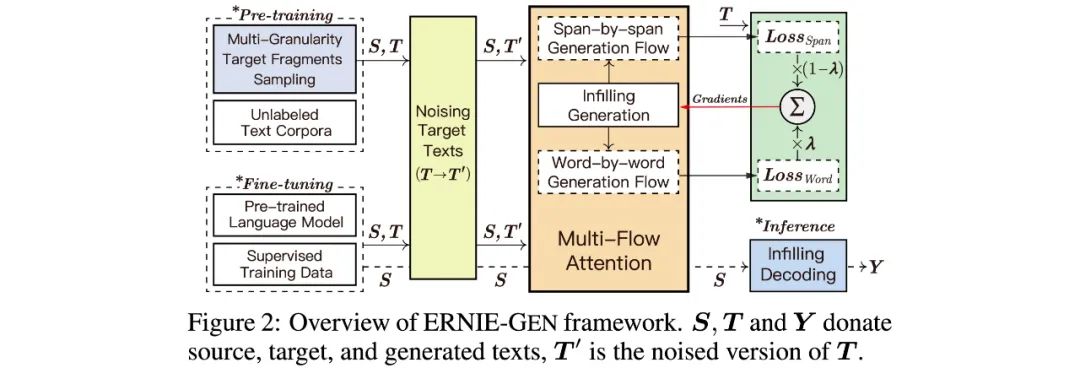
Methods
“曝光偏置(exposure bias)”问题
在基于Transformer的seq2seq框架中,decoder端第 个字符 的预测公式如下:
其中 , 分别表示预测字符向量和Ground Truth字符向量, 为encoder端的表示;对 的预测起着直接影响的是用来汇聚上文表示的 ,这也是训练和解码阶段产生差异最直接的地方。同时, 在训练和解码中也存在差异,但对 的影响相对较弱。
为了在预训练阶段减小下游任务的“曝光偏置(exposure bias)”问题,ERNIE-GEN提出了两种适用于大规模无监督预料的生成训练方法:1)填充生成机制(Infilling Generation);2)噪声感知生成方法(Noise-aware Generation)。
-
「Infilling Generation Mechanism 填充生成机制」
针对训练和解码中 存在的差异,Infilling Generation通过在decoder端每个字符后填充符号[ATTN]作为 来汇聚上文表示,统一了训练和解码中 的差异:
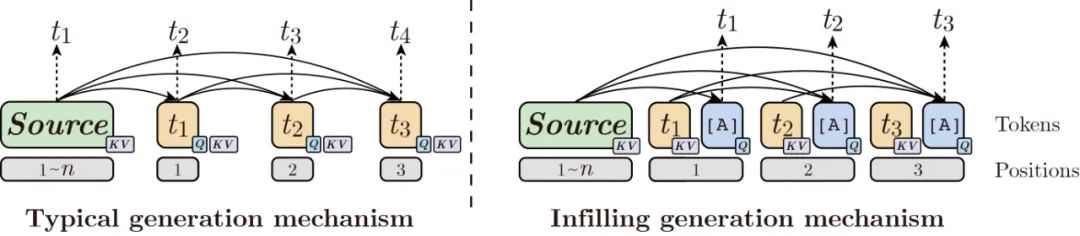
Infilling Generation的好处有两点:
-
减弱了预测 时对 上一个字符 (训练时)或者 (解码时)的依赖,将预测的注意力转移到更全局的上文表示,从而在解码阶段,有利于缓解 预测错误对 的影响,增强生成的鲁棒性。同时在训练阶段,有利于缓解局部过度依赖; -
统一了训练和解码中 的差异,有利于减弱"曝光偏置"。
-
「Noise-aware Generation Method 噪声感知生成」
针对训练和测试中 的差异,ERNIE-GEN在训练中对decoder的输入序列添加随机噪声,来训练模型感知错误,并通过调整attention权重来减弱错误对后续生成的影响;
但最好的方式是用模型先生成一遍目标序列,再根据生成的分布进行采样,这种方式是最本质解决”曝光偏置“的方法,如ACL2019最佳论文,将模型生成序列和Ground Truth序列融合输入decoder进行学习。考虑到预训练基于大规模的无监督预料,ERNIE-GEN只采用简单的随替换,来缓解“曝光偏置”。
逐字符学习的问题
传统的自回归seq2seq训练采用逐字符(word-by-word)的学习范式,而人类写作,往往是实体、短语甚至句子同时构思好的,并非逐字思考;而且逐字符学习很容易局部过拟合,过度依赖上一个字符的表示。
针对逐字符学习的不足,ERNIE-GEN提出了逐片段(span-by-span)的学习范式,即训练时,每步不只预测一个字符,而是预测一个语义完成的片段:
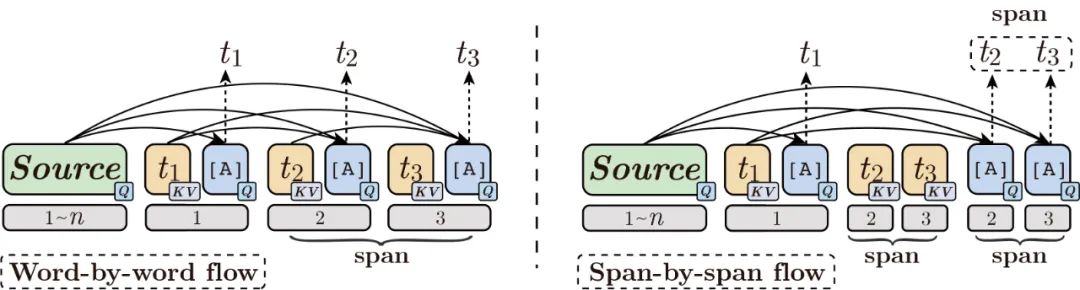
图中 为一个语义完整的span。逐字符学习(word-by-word)的目标序列的概率为:
逐片段学习(span-by-span)的目标序列的概率为:
在 内, 和 是同时预测的,它们都依赖相同的上文 。使模型在 位置具有生成下一个语义片段span的能力,让模型更具「远见」,并提高生成质量。
为了连续地采样语义完整片段(semantically-complete span),ERNIE-GEN通过「T-检验」来统计训练数据中的 片段:
-
「step1:」 基于初始假设 : “一个随机的 不是一个具备统计意义的片段“,可以计算得到训练数据中所有 和 的 t-统计值,公式如下:
其中 为 的统计概率, 为 的方差(伯努利分布); 为 的总数;
-
「step2:」 筛选出t-统计值. top 20w的bi-gram和top 5w tri-gram以及全部uni-gram来构造span词典 ;*注:_t-统计值_越高表示越否定假设 , 越可能是统计意义下完整的片段。 -
「step3:」 根据词典 在ground truth序列中采样span,按照tri-gram bi-gram uni-gram的顺序在 中查询,直到一个gram被查到。
Encoder和Decoder相关性减弱的问题
在构造预训练数据时,UniLM和MASS都采样一段连续的子序列作为生成目标,当输入序列很长时,由于目标序列较长,decoder端对encoder的依赖减弱,模型训练有退化为language model的风险,不利于encoder和decoder的联合预训练。对此ERNIE-GEN采用「多片段-多粒度采样」的策略来构造预训练数据:
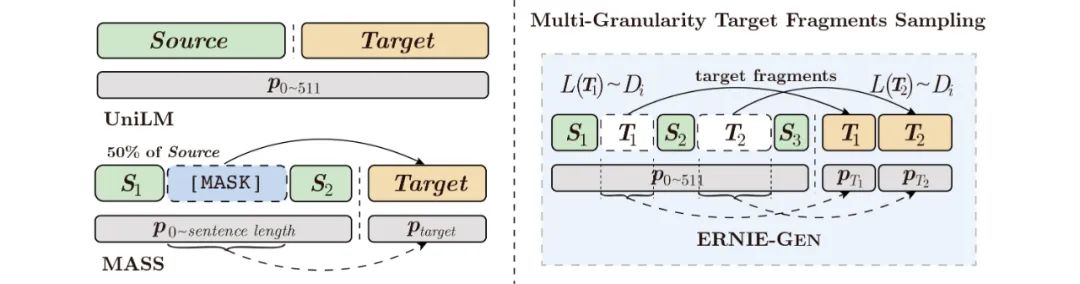
给定输入序列 ,ERNIE-GEN先采样一个长度分布 ,根据 在 中采样子序列,直到所有子序列 的总长度到 的 25%。拼接后的的序列 为预训练学习的目标序列,采样后的 记作 。如此一来,采样的子序列和 的语义相关性很强,encoder和decoder的相关性也进一步得到增强,有利于encoder和decoder的联合预训练。
Model Architecture
「Multi-Flow Attention」 多流attention结构
基于Infilling generation机制,ERNIE-GEN在预训练中将word-by-word和span-by-span的训练任务进行联合学习。在具体实现中,ERNIE-GEN将infilling generation中插入的[ATTN]符号抽出,拼接成了一个[ATTN]符号序列 用于预测。模型通过输入两个等长的符号序列 来预测word-by-word任务和span-by-span任务的生成结果。
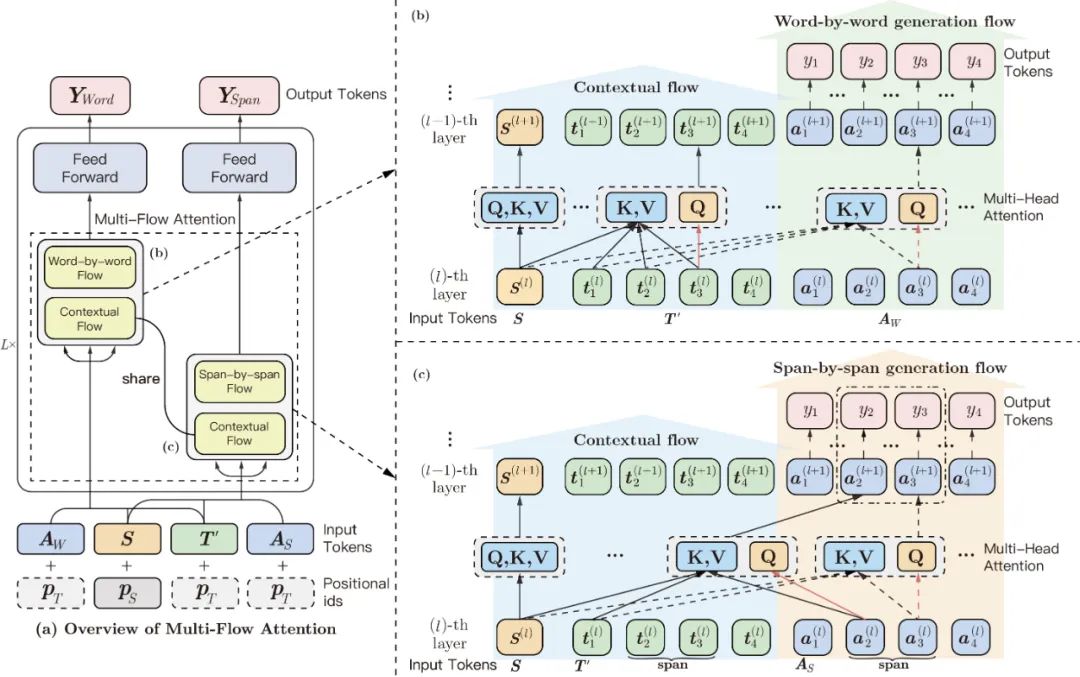
图中蓝色区域为「Contexture Flow」,用于提供上文表示,其 层到 层更新如下:
其中,encoder序列为 ,加噪后的decoder输入序列为
图中绿色区域为基于Infilling generation机制的「Word-by-word generation flow」,用于学习逐字符地生成,其 层到 层更新如下
其中 表示 l-th层,符号序列 的 第 个隐层向量。
图中橘色区域为基于Infilling generation机制的「Span-by-span generation flow」,用于学习逐片段地生成。在给定采样span的边界序列 时,其 层到 层更新如下:
其中 表示 l-th层,符号序列 的 第 个隐层向量,也即第 个span的第 个隐层向量, 。片段 是在给定上文时,同时预测的。
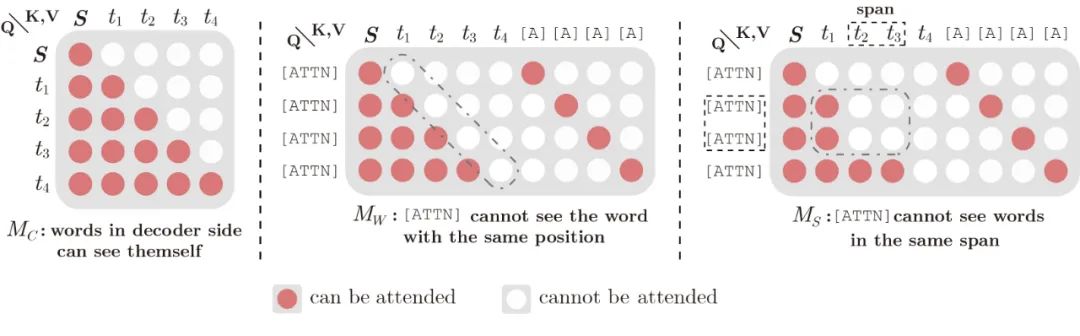
在实现中,「Contexture Flow」、「Word-by-word Flow」和「Span-by-span Flow」的输入分别是 和 ,并通过不同的_attention mask_矩阵 来实现具体的逻辑:
「Contextual Flow」中 是双向可见的, 是单向可见的 (seq2seq);而「Word-by-word Flow」中的符号序列 不能看见相同位置的目标字符;「Span-by-span Flow」中,符号序列 不能看见同一个span中的所有目标字符,如图中的 。
「Word-by-word Flow」和「Span-by-span Flow」的loss加权更新,Pre-train阶段,ERNIE-GEN同时训练两个任务 ;Finetune阶段 ,ERNIE-GEN只学习word-by-word的生成任务:
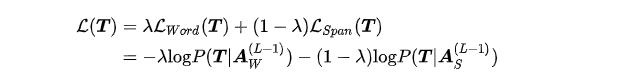
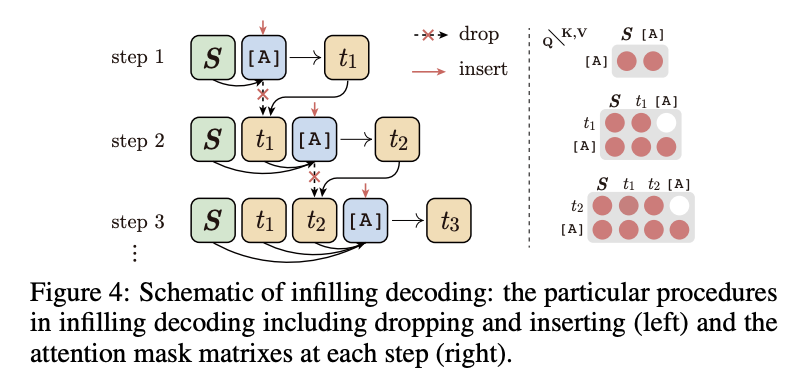
「Infilling Decoding」填充解码
训练时,ERNIE-GEN通过[ATTN]符号序列 来生成序列,而在解码时,则需要一步一步地插入[ATTN]符号来汇聚上文表示,预测当前位置的字符。为了保证解码的效率,ERNIE-GEN在[ATTN]预测完毕后,会将[ATTN]的表示从序列中去除。具体的解码步骤如下图所示:
Experiments
Pre-training
ERNIE-GEN使用和BERT、UnilM相同的训练数据(16G),base和large模型分别用BERT-base和BERT-large热启,训练40W步左右。预训练阶段,在decoder输入序列中加入比例为 的噪声。ERNIE-GEN在最近补充了用160G预训练数据(同Roberta)下的模型性能,多个生成数据集上取得了SOTA。
Fine-tuning
ERNIE-GEN在摘要生成、问题生成、对话和生成式问答4中任务上进行了实验,都验证了策略的有效性。
-
Finetune参数配置

Ablation Studies
-
Infilling Generation 和 传统生成机制
ERNIE-GEN在3个小数据集上(Gigaword-10k, CNN/DM-10k和SQuAD)上对比了Infilling generation和传统生成机制。对比结果分别用Infilling generation机制和传统生成机制pre-train和finetune,实验结果如下:
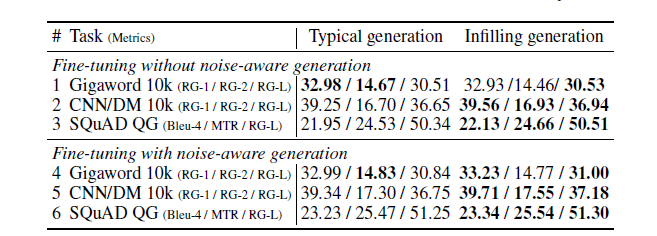
当finetune不加噪声时,Infilling generation机制在CNN/DM-10k和SQuAD上较传统机制更好,但在Gigaword-10k上持平;当finetune加入噪声时,两种生成机制的效果都有明显的提升,且infilling机制在摘要生成任务上的涨幅为明显。
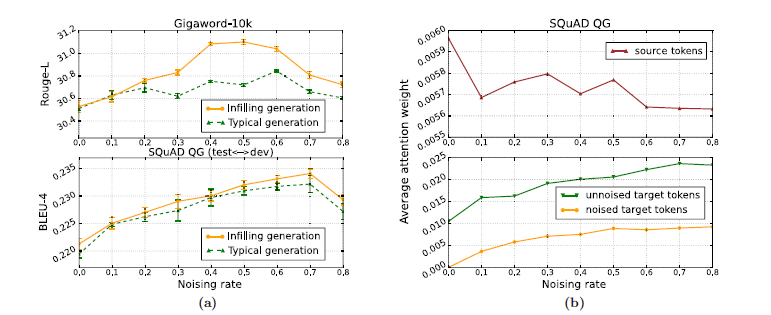
左图指出,infilling generation机制在不同的噪声 比例下,都较传统生成机制性能更好;为了进一步说明噪声对生成训练起的作用,论文中分析了不同噪声比例下,比较了encoder字符、未加噪的decoder字符和加噪的decoder字符在最后一层的平均attention权重。有意思的是,随着噪声比例增加,模型将更多的注意力分配到decoder端,用于检测decoder端的错误,并且给错误的字符分配更小的权重,给正确的字符分配更高的权重,从而增加了生成的鲁棒性。
-
Span-by-span 训练任务 和 Noise-aware 生成方法
表中上方的对比实验指出,span-by-span训练任务和Noise-aware生成方法都起到了显著的性能提升作用。
UniLM利用Mask LM的方式进行finetune,实质上是在输入序列中加入[MASK]噪声,随后预测噪声位置的真实字符。这种噪声finetune方式存在Mask(噪声)和预测耦合的问题,学习性能不高 (UniLM在finetune中的mask比例为 )。因此,为了验证ERNIE-GEN的Noise-aware生成方法相较于Mask LM方式更有效,论文也列出了ERNIE-GEN使用Mask LM(0.7)方式进行finetune训练的实验结果结果,并验证了Noise-aware生成方法的有效性。
总结
ERNIE-GEN针对生成任务的具体问题,如“曝光偏置”、局部强依赖性等,提出了一套在预训练中可行的解决方案,增强了自然语言生成学习的鲁棒性。通过设计一套pre-train和fine-tune的统一的学习框架,ERNIE-GEN缩小了pre-train和fine-tune间的差异;同时,通过infilling generation机制和noise-aware generation方法,也缩小了training和decoding之间的差异。最终,ERNIE-GEN在多项生成任务上取得了最好的效果,验证了所提出策略的有效性。
- END -





