【IJCAI2020-Facebook】利用弱标记数据对声音进行大规模的视听学习

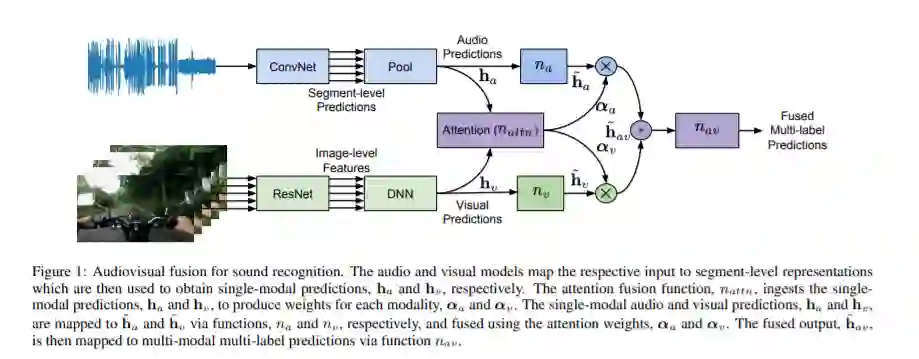
识别声音是计算音频场景分析和机器感知的一个关键方面。在本文中,我们主张声音识别本质上是一个多模态的视听任务,因为它更容易区分声音使用音频和视觉模态,而不是一个或另一个。我们提出了一种视听融合模型,该模型能够从弱标记的视频记录中识别声音。所提出的融合模型利用注意力机制,将单个音频和视频模型的输出动态地结合起来。在大型音频事件数据集AudioSet上进行的实验证明了该模型的有效性,其性能优于单模态模型、最先进的融合和多模态模型。我们在Audioset上实现了46.16的平均精度(mAP),比之前的技术水平高出大约4.35个mAP(相对:10.4%)。
https://arxiv.org/abs/2006.01595
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“LSAL” 可以获取《利用弱标记数据对声音进行大规模的视听学习》专知下载链接索引



登录查看更多
相关内容
Arxiv
7+阅读 · 2019年4月18日
Arxiv
3+阅读 · 2018年5月31日




相关VIP内容
相关资讯
相关论文
Arxiv
7+阅读 · 2019年4月18日
Arxiv
3+阅读 · 2018年5月31日