业界 | 如何训练出专属的 OpenAI Five ?

AI 科技评论按:上周末,成功击败 Dota 2 世界冠军团队 OG 的 OpenAI Five 再次赢得全球瞩目。胜利的背后,OpenAI Five 有哪些不为人知的故事呢?OpenAI 官方博客近日发布了一篇涉及幕后的解读文章,我们将之编译如下。

OpenAI Five 是首个成功在电子竞技游戏中击败世界冠军的人工智能,在本周末与 Dota 2 世界冠军团队 OG 的最终对决中,接连赢得了两场比赛。在过去,无论 OpenAI Five 还是 DeepMind 的 AlphaStar 都曾私下击败过优秀的职业选手,却输掉现场的职业比赛,因此,我们也可以将该事件视作 AI 第一次在直播中击败电子竞技专家。
在 OpenAI Five 与人类世界冠军的最终对决中,我们发现了两个意外的惊喜:
OpenAI Five 自行发展出与人类队友打配合的基本能力,尽管我们的训练过程主要专注于如何击败其他机器人。这种将竞争性 AI 转变为合作型 AI 的可能性,让我们对未来 AI 系统将如何通过积极的开发工作造福人类充满了希望。
4 月 18 日——4 月 21 日期间,我们将 OpenAI Five 对全世界的 DOTA2 玩家开放,每个人都可以和 OpenAI Five 在线对战,无论是作为竞争者亦或是还是合作者。最终的测试结果将能回答一个重要的研究问——OpenAI Five 可以在多大的程度上被人类所利用与依靠。这可能是有史以来最大规模的高强度深层强化学习 agent 的部署行为,人们可以有意识地与之进行交互。
感兴趣的童鞋可点击以下网址与 OpenAI Five 一同比赛:
https://arena.openai.com/#/
为何是 Dota?
我们之所以启动 OpenAI Five 研究,目的是解决现有深度强化学习算法无法实现的问题。我们希望在这个当前方法所无法解决的问题上努力,原以为需要大幅提升工具的性能,比如复杂的算法思想(例如:分层强化学习),但我们却对最终的发现感到惊讶:该问题所需的根本改进在于规模。如何实现该规模并加以运用,其实并不容易,也是我们研究工作的主要内容!

OpenAI Five 将世界视作一堆必须破译的数字,使用的是同样的通用学习代码,无论这些数字代表的究竟是 Dota(约 20,000 个数字)还是机器臂(约 200 个数字)。
为了打造 OpenAI Five,我们创建一个名为 Rapid 的系统,可以让我们以前所未有的规模来运行 PPO。最终结果超出了我们最高期望值,我们成功打造出世界级别的 Dota 机器人,基本不存在任何的基本性能限制。
当今 RL 算法令人惊叹的强大能力是以大量的经验作为代价的,要想脱离游戏或模拟环境来实现是不切实际的。当然,这种局限可能并没有听起来的那么糟糕——比如我们可以通过 Rapid 系统控制机械臂以灵巧地移动方块,首先在全模拟环境中进行训练,然后在物理机器人上执行。不过,我们认为如何减少对经验的依赖是 RL 的下一个挑战。
我们今天宣布,作为竞争性 AI 的 OpenAI Five 已经退役了,但它所取得的进步与技术进展将继续推动我们未来的工作发展。总之,这不是我们 Dota 工作的终点——我们认为,比起现在惯用的标准环境,Dota 对于 RL 开发而言更具有趣味性与难度(如今已很好理解!)。
计算力
将 OpenAI Five 周六的胜利与 The International 2018 的 losses 相比,会发现胜利是基于该项重大变化:增加了 8 倍的训练计算量。在项目的许多前期阶段,我们都是通过提升训练规模来推动研究进程。但在 The International 以后,我们已将项目的绝大部分算力用于培训单一的 OpenAI Five 模型。因此,我们只能以唯一可行的方式来增加计算规模:更长的训练时间。
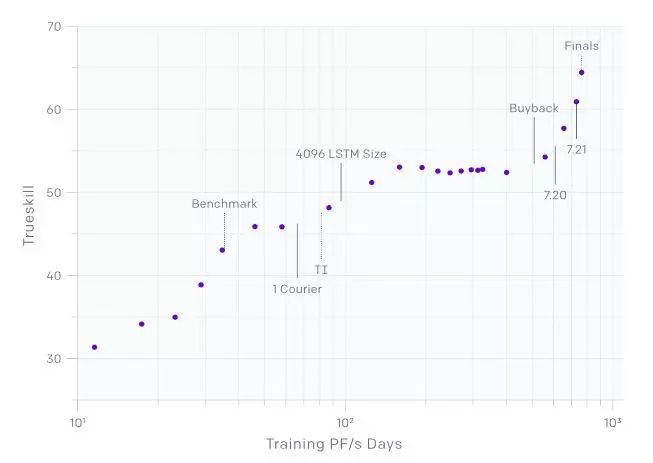
OpenAI Five 的 TrueSkill,由于增加了额外的训练算力,其中线条划分了主要系统的变化(转向单一快递;将 LSTM 的大小增加至 4096 units;升级至 7.20 和 7.21 补丁版本;以及开始学习 buyback)。该图大致上是线性的,这意味着 OpenAI Five 从额外的算力中不断受益(请注意,这是一个对数 - 对数图,x 轴是计算的对数,而 TrueSkill 大致对应于指数的进展)。该图表评估了在最终游戏规则(1 个 courier,7.21 补丁,等)上所有机器人的表现——包括那些在旧游戏规则上进行训练过的机器人。任何在这些之后的陡坡则表明 OpenAI Five 适应了这种变化;根据这种变化,该评估可能对早前版本的有些不公平。
总的来说,当前版本的 OpenAI Five 已经消耗了 800 petaflop / s-days,并且在 10 个实时月的时间内经历了大约 45,000 年的 Dota 自行游戏(从 The International 的 1.5 个实时月份开始算起的话,大约晋级了 10,000 年),即是平均每天 250 年的模拟经验。总决赛版本的 OpenAI Five 与 TI 版本相比,胜率为 99.9%。
迁移学习
尽管模型大小和游戏规则发生了变化(包括一些相当大的游戏补丁更新和新实现的功能),但自 2018 年 6 月以来,当前版本的 OpenAI Five 一直在持续训练。在每一种情况下,我们都能够转移模型,并继续对其他领域的 RL 进行训练,这是一个开放的挑战。据我们所知,这是第一次对 RL 代理进行长期训练。
为了实现这一点,我们继续完善我们的工具,这样我们就可以从经过训练的参数开始,直至从根本上更改架构。
更多英雄
我们看到从 5 到 18 位英雄的训练速度几乎没有慢下来。我们假设更多的英雄也会有同样的情况,而在国际上,我们投入了大量的努力来整合新的英雄。
我们花了几周时间训练多达 25 个英雄的英雄池,使这些英雄达到大约 5 千 MMR(约 95% 的 DOTA 玩家的水平)。虽然他们还在进步,但他们的学习速度不够快,无法在决赛前达到专业水平。我们还没有时间来调查原因,但我们认为原因可能是模型能力、需要更好地匹配扩展的英雄池、需要更多的训练时间让新英雄赶上旧英雄等。
我们相信这些问题是可以从根本上解决的,解决它们本身就很有趣。总决赛版本与 17 个英雄一起比赛,我们移除了巫妖,因为他的能力在 DOTA7.20 版本中发生了显著变化。
合作模式
感觉真好,我的冥界亚龙在某个时刻为我献出了生命。他试图帮助我,他认为「我确定她知道她在做什么」,但显然我不知道。但你知道,他非常信任我。我对(人类)队友不太了解。——Sheever

OpenAI Five 与人类一起玩的能力为人类和人工智能交互的未来提供了一个美好的愿景,在未来,人工智能系统将与人类协作并增强人类体验。我们的测试人员说,他们感觉得到了机器人队友的支持,他们从与这些先进系统一起玩的过程中学到了经验,总体来说,这是一次有趣的体验。
值得注意的是,OpenAI Five 展示了零样本迁移学习——它被训练为让所有英雄都由自己的副本控制,但是可以控制英雄的一个子集,与人类是战友或者敌人。我们很惊讶这项工作做得这么好。事实上,我们曾经考虑过在国际比赛中举行一场合作赛,但这需要进行专门的训练。
Arena
我们将推出 OpenAI Five Arena,这是一个公共实验,我们将让任何人以竞争和合作的方式玩 OpenAI Five。我们的 1v1 机器人可以通过巧妙的策略加以利用,但我们不知道 OpenAI Five 在多大程度上可以做到这样,我们很高兴邀请社区帮助我们发现这一点!
Arena 将于太平洋时间 4 月 18 日下午 6 点开放,并将于 4 月 21 日下午 11:59 关闭。请注册账号,以便我们确保您所在地区有足够的服务器容量!所有比赛的结果将自动报告到 Arena 的公共排行榜。

我们非常感谢 DOTA 社区在过去两年里给予我们的所有支持,我们希望 Arena 也能成为回报的社区的一个小途径。玩得开心!
接来下是什么
我们回顾了 Openai Five Arena 的成果,接下来,我们将发布 Openai Five 的更加技术性的分析。
之后,我们将继续在 OpenAI 中使用 DOTA2 环境。在过去两年,我们见证了 RL 能力的快速发展,我们认为 DOTA 2 将继续帮助我们推进未来的研究——无论是用更少的数据获得更好的表现,亦或是真正实现人和人工智能的合作。
via https://openai.com/blog/how-to-train-your-openai-five/




