Swin梅开三度!ETH 开源VRT:刷新视频复原多领域指标的Transformer

极市导读
在Swin Transformer+Image Restoration组合方面尝到“甜头”后,SwinIR的作者又瞄上了3D版组合:Video Swin Transformer + Video Restoration,又一次刷新了视频复原多个领域的“高度”。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

论文链接:https://arxiv.org/abs/2201.12288
代码链接:https://github.com/JingyunLiang/VRT
在过去的2021年里,Transformer以及MLP对CV各个领域进行疯狂的“降维打击”,占领了各个子领域的“高地”。其中最典型的当属Swin Transformer一文,其2D版轰动一时,同时也获得了ICCV2021最佳论文奖。后续,原班人马对其进行扩展得到了Video Swin Transformer并在视频相关领域持续发热。关于Swin Transformer相关解读以及code可参考如下:
-
Swin-Transformer-Image-Classification: https://github.com/microsoft/Swin-Transformer -
Swin-Transformer-Object-Detection: https://github.com/SwinTransformer/Swin-Transformer-Object-Detection -
Swin-Transformer-Semantic-Segmentation: https://github.com/SwinTransformer/Swin-Transformer-Semantic-Segmentation -
Video-Swin-Transformer: https://github.com/SwinTransformer/Video-Swin-Transformer -
Swin-MLP-Image-Classification: https://github.com/microsoft/Swin-Transformer -
Swin-Transformer-Contrasitive-Learning: https://github.com/SwinTransformer/Transformer-SSL -
图解Swin Transformer: https://zhuanlan.zhihu.com/p/367111046
在图像复原领域,也有不少Transformer相关的paper,比如SwinIR,相关解读可参考:
Transformer在图像复原领域的降维打击!ETH提出SwinIR:各项任务全面领先
SwinIR直接将2D版的Swin Transformer应用到图像复原领域,在各个子领域取得了“全面领先”的性能,同时也获得了ICCV-AIM2021最佳论文奖。🌟🌟🌟
在Swin Transformer+Image Restoration组合方面尝到“甜头”后,SwinIR的作者又瞄上了3D版组合:Video Swin Transformer + Video Restoration,又一次刷新了视频复原多个领域的“高度”。
Method
假设输入低质序列为 ,目标序列为 (s表示尺度因子,对于超分来说,s表示超分倍率;对于去模糊/降噪来说,s=1)。视频复原的目标则旨在以 为输入,对 进行预测。视频复原主要包含视频超分、视频去模糊、视频降噪三大任务,学术界的研究也主要聚焦于这三个任务。
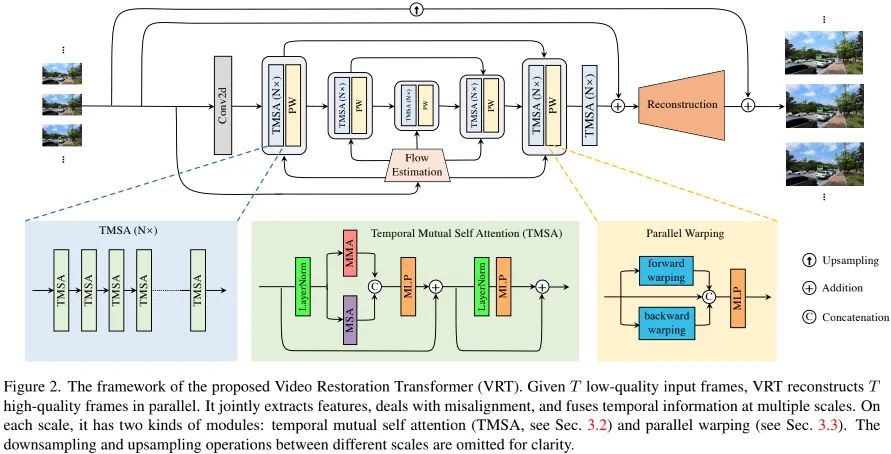
上图给出了本文所提VRT整体架构示意图(注:上图仅为核心部分示意图,还有一部分光流对齐的预处理部分并未示出,同时上图可视化部分为2D形式,而实际则是3D形式)。VRT可以划分为特征提取与图像重建两部分。
Feature Extraction: 在开始部分,我们采用一个2D卷积提取浅层特征 。然后,我们基于UNet架构设计了一种多尺度网络在不同分辨率进行特征对齐。在不同尺度,我们可以采用两个模块(Temporal Mutual Self-Attention与Parallel Warping)进行特征提取以及运动处理。最后,我们采用多个TMSA模块进一步进行特征提炼得到深层特征 。
Reconstruction: 在完成特征提取后,我们同时利用浅层特征与深层特征进行高质量图像重建。为缓解特征学习负担,我们采用了全局残差学习机制。实际上,对于视频超分而言,其重建模块采用了PixelShuffle方式进行特征上采样;对于视频去模糊、视频降噪,单个卷积足矣进行重建。
Loss Function: 为与现有方案公平对比,在损失函数方面,我们采用了Charbonnier损失:
注: 表示重建高质量图像, 。
正如前面所提到,VRT的关键模块是TMSA与Parallel Warping。接下来,我们将对这两个关键模块进行详细介绍。
Temporal Mutual Self Attention
Mutual Attention 给定参考帧(原文为reference)特征 与近邻帧(原文为supporting)特征 ,我们可以通过如下方式计算注意力三元素:
然后,我们采用 对 进行索引以得到注意力图并用于与 进行加权:
由于 分别来自 ,那么注意力图A可以反映参考图像与近邻图像之间的相关性。为更好说明,我们将前述公式的i元素重写为如下形式:
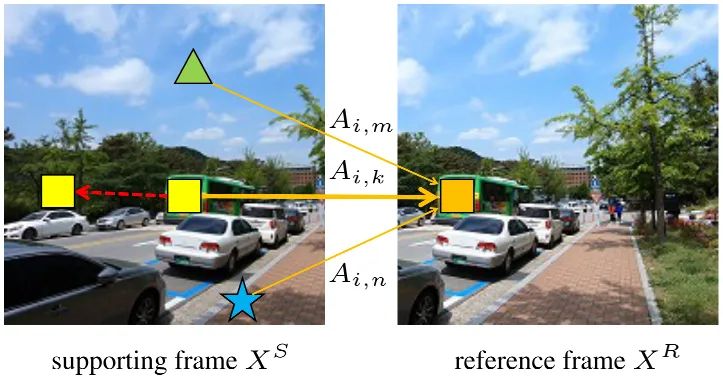
如上图所示,近邻帧中的 与参考帧中的 最为相似,那么 ,进一步可描述如下:
在极限情况下,它等价于基于光流的图像仿射(Image Warping)。当 无法满足时,上述描述可视作“soft”版图像仿射。实际上,参考帧与近邻帧可相互替换,进而达成互对齐。此外,类似于多头自注意力,我们构建了多头互注意力,即MMA。相比显示的运动补偿+图像仿射组合,互注意力具有如下三个优势:
-
互注意力可以自适应保持源自近邻帧的信息,同时可以避免“空洞”伪影问题; -
互注意力无需局部归纳偏置,避免了CNN光流估计面试相邻目标不同方向运动方向时的性能下降问题; -
互注意力等价于特征层面的运动估计与仿射的联合优化,而光流估计仅适用于RGB图像且鲁棒性差。
Temporal Mutual Self Attention(TMSA): 为提取并保持当前帧特征,我们同时采用了互注意力与自注意力。假设 表示两帧特征,可拆分为。我们采用MMA进行两次处理: 。仿射所得特征将与自注意力特征进行拼接并送入后续MLP模块进行融合。整体过程可以描述如下:
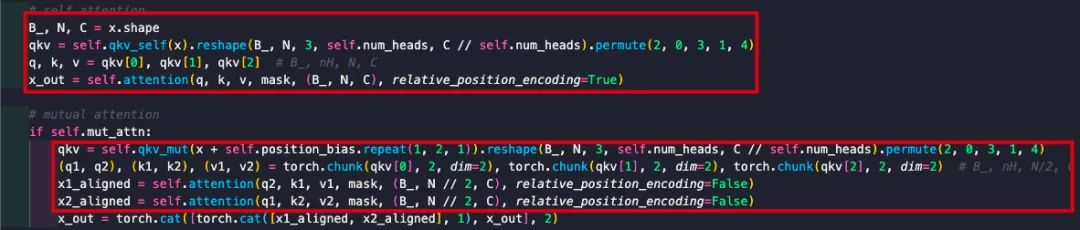
给出了上述计算流程的核心实现,事实上可以看到:自注意力与互注意力的 关键区别体现在Position信息,移除掉Position信息部分后,MMA相当于两路并行MSA(通过调整qkv_mut参数可以等价转换)。自注意力采用的是Position Embedding 的进化版Relative Position Embedding,而互注意力采用的是Sine Position Encoding。
关于两者的区别可以参考:
position embedding和position encoding是什么?有什么区别? :https://www.zhihu.com/question/402387099
关于Position Encoding的介绍可以参考:
Transformer中的Position Encoding:https://blog.csdn.net/weixin_42715977/article/details/122135262
如何理解Transformer中的Position Encoding?:https://www.zhihu.com/question/347678607)
关于Relative Position Embedding可以参考:
图解Swin Transformer:https://zhuanlan.zhihu.com/p/367111046
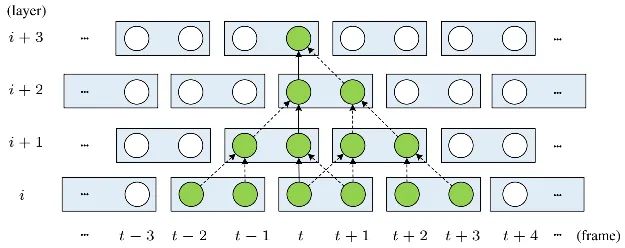
受限于互注意力的设计,上面过程一次只能处理两帧。最笨的方式是逐帧方式处理多次,但这会导致较高的计算复杂度。受启发于Video Swin Transformer,我们提出了TMSA以缓解该问题。TMSA首先将序列拆分为非重叠2帧片段并执行上述过程,然后参考下图方式进行时序移位以促进跨片段信息交互。时序感受野会随多个TMSA模块堆叠而提升,具体来说,对 层,其时序感受野可以达到 。
Parallel Warping
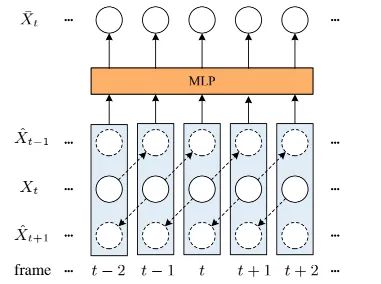
由于窗口划分,互注意力可能无法处理大于东问题。在每个网络阶段尾部,我们采用特征仿射处理大运动。对于任意帧特征 ,我们计算它与近邻帧 的光流并进行双向仿射得到 (可参考上图)。然后,我们将所得仿射特征与原始特征进行拼接并融入MLP进行特征融合与特征降维。具体来说,参考BasicVSR++,我们采用光流模块预测残差光流并采用形变卷积进行对齐。注:上面的图示与描述为2近邻模式,同样的机制可以适用于四近邻与六近邻。
在实际实现过程中,对于连续6帧输入,作者采用了2近邻模式(如视频去模糊、视频降噪);对于连续8帧输入,作者采用了4近邻模式(如Vimeo数据集上的视频超分);对于连续16帧输入,作者采用了6近邻模块(如REDS数据上的视频超分)。
Experiments
为更好说明所提方案的优异特性,作者在三大视频复原任务上进行了实验。
VideoSR
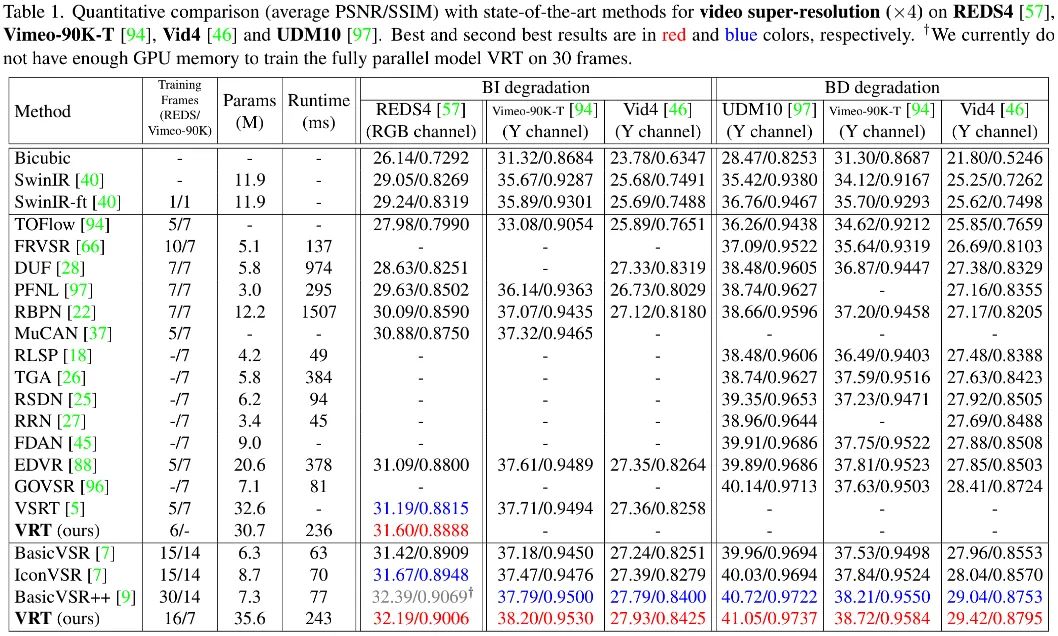
上表给出了BI与BD两种退化方案下不同数据集性能对比,可以看到:
-
无论是BI还是BD退化,VRT均取得了最佳性能,且大幅超越已有方案; -
相比VSRT,轻量版VRT指标高出0.41dB; -
相比EDVR,VRT指标高出0.5-1.57dB不等; -
相比BasicVSR++,VRT指标高出0.2-0.5dB不等; -
不得不提的一点是:VRT的处理速度以及参数量均远大于BasicVSR++。

Deblurring
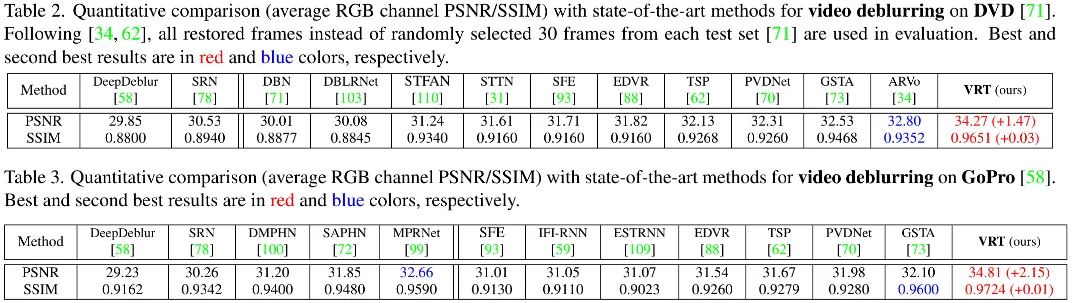
上面两个表格给出了DVD与GoPro两个数据集上不同方案的性能对比,从中可以看到:
-
在DVD数据集上,VRT以1.47dB指标优于此前最佳方案ARVo; -
在GoPro数据集上,VRT以2.15dB指标优于此前最佳方案GSTA; -
从参数量角度来看,VRT为18.3M,少于EDVR的23.6M与PVDNet的23.5M; -
从推理速度来看,VRT处理 的速度为2.2s。

Denoising
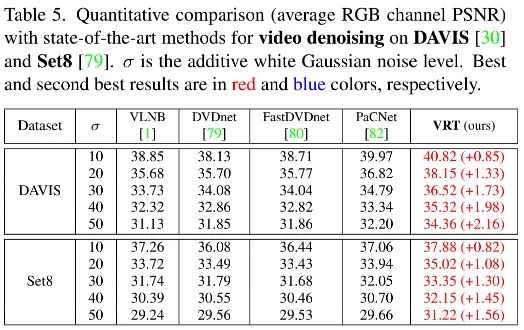
上表给出了DAVIS与Set8数据集上的性能对比,从中可以看到:VRT均取得了超越已有方案的性能,性能提升0.82-2.16dB不等。
公众号后台回复“数据集”获取30+深度学习数据集下载~

# 极市平台签约作者#

happy
知乎:AIWalker
AIWalker运营、CV技术深度Follower、爱造各种轮子
研究领域:专注low-level,对CNN、Transformer、MLP等前沿网络架构
保持学习心态,倾心于AI技术产品化。
公众号:AIWalker
作品精选





