点击率预估中的自适应参数生成网络

今天给大家分享一篇阿里发表的关于神经网络中网络参数自适应生成的文章,不仅可以做到不同的样本有不同的网络参数,同时通过拆分矩阵等操作大大提升了推理性能,一起来学习一下。
1、背景
2)更先进的网络结构设计:如设计多样的特征交叉模块,自动的网络结构搜索等等
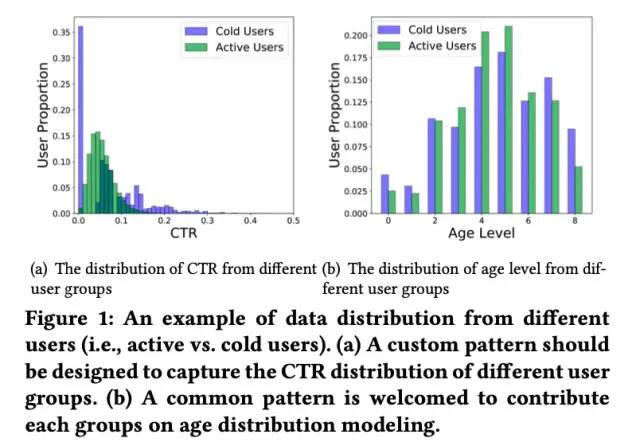
因此,除学习样本中的共性模式外,网络参数应该更加具有适应性,能够随着不同的输入样本动态改变来捕获样本中的特有模式。但是,想要实现针对不同样本的自适应参数生成,需要解决以下两方面的挑战:
1)高效的计算和存储
2)同时学习样本间的共性模式和单个样本内的特有模式
为了解决以上两方面的挑战,论文提出了Adaptive Parameter Generation network (以下简称APG),一起来看一下。
2、APG介绍
2.1 APG框架简介
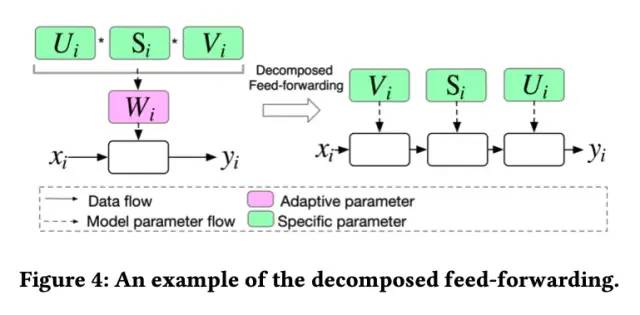
APG的整体框架如下图所示。可以看到,针对输入样本i,xi为样本i的输入特征,zi为样本i的状态(condition)向量。
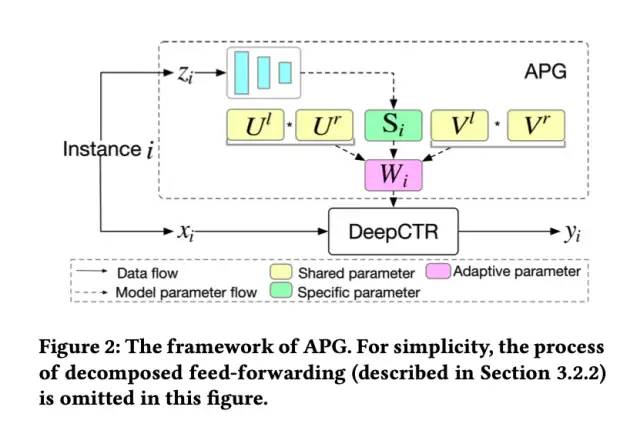
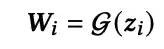
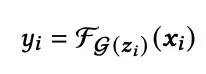
那么,样本i的状态向量zi是如何生成的呢?模型参数生成如何保证高效性和有效性呢?接下来的两节进行分别的介绍。
2.2 状态(condition)向量生成
论文给出了三种状态向量zi生成的方式,分别为Group-wise,Mix-wise和Self-wise。
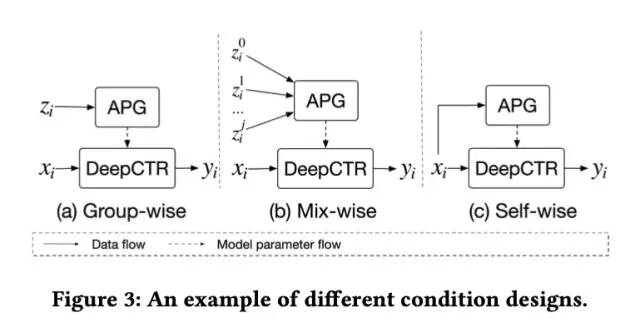
Group-wise
Group-wise基于一定的规则对样本进行聚类,同一类别下的样本使用相同的状态向量来生成网络参数,以此来学习不同类别的特有模式。如使用用户id的embedding作为状态向量,相同用户的不同样本使用相同的参数,不同的用户参数则不同。
Mix-wise
Mix-wise策略使用多个状态向量,如用户id的embedding和最近点击item的embedding的组合。不同的状态向量之间的组合可以有输入聚合和输出聚合两种聚合方式。
1)输入聚合(Input Aggregation):首先对不同的状态向量进行聚合,随后生成网络参数。聚合可以采用拼接,avg-pooling或者attention的方式。
2)输出聚合(Output Aggregation):不同的状态向量生成对应的网络参数,随后对参数进行聚合。聚合同样可以采用拼接,avg-pooling或者attention的方式。
Self-wise
前面两种方式需要额外的先验知识对状态向量进行设计,而Self-wise策略则使用简单易获取的知识进行状态向量设计,如网络的第1层对应的状态向量为样本输入向量xi,第l层对应的状态向量为网络第l-1层的输出。
2.3 参数设计
基本思路
这一节,我们以最简单的一层全链接网络作为DeepCTR部分进行介绍。
当状态向量获取后,最基本的思路是通过MLP层得到网络参数,用于DeepCTR部分的前向计算:
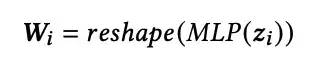
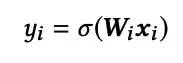
Low-rank parameterization降低复杂度
论文采用了Low-rank parameterization的方式,将网络参数Wi拆解为三个矩阵:
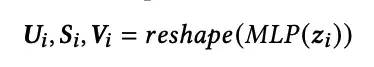
此时DeepCTR部分的前向计算过程变为:
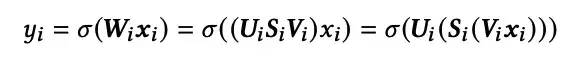
进行如上的优化后,网络的存储复杂度变为O((NK+MK+KK)D),由于K往往远小于N和M的最小值,因此存储复杂度可以近似为O((NK+MK)D),而计算复杂度为O((NK+MK)(D+1))(参数生成的计算复杂度为O((NK+MK)D),DeepCTR部分的计算复杂度为O(NK+MK))。
Parameter sharing学习共性模式
背景中提到,APG需要解决两方面的挑战,上述Low-rank parameterization的方式,使得模型的计算和存储更加高效。接下来需要解决的挑战是:如何同时学习样本间的共性模式和单个样本内的特有模式?
论文采用的是参数共享的方式,即U和V矩阵所有实例共享,学习所有样本的共性模式,S矩阵为样本独有,学习样本的特有模式:
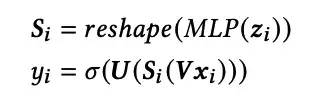
Over Parameterization提升模型表达能力
虽然已经解决了APG所面临的两方面的挑战,但是共享的矩阵U和V由于维度K的限制(K<<min(N,M)),在一定程度上约束了模型的表达能力,因此论文提出了一种过度参数化(Over Parameterization)的方法,进一步将矩阵U和V拆解为两个大矩阵的相乘:
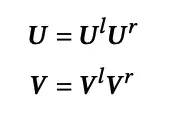

尽管使用了过度参数化的方法,但模型训练完成后,可以直接存储V和U,不必存储对应的拆分的大矩阵,因此并没有带来额外的线上的预测耗时和存储空间。
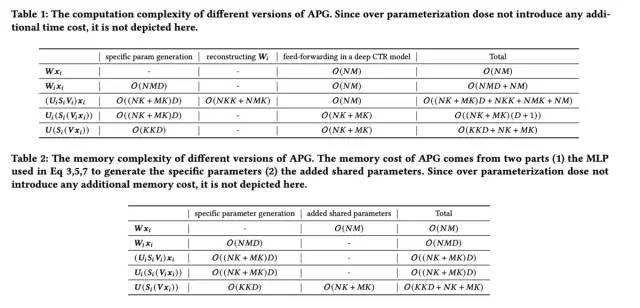
2.4 复杂度分析
关于模型的复杂度咱们前面也介绍过一些了,这里就不再做更详细的介绍,直接贴论文给出的总结表格,感兴趣的同学可以详细看下:
3、实验结果及分析
最后来看下实验结果:
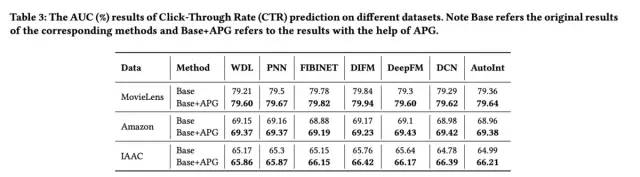
好了,本文就介绍到这里,思路还是比较新颖的,感兴趣的同学可以阅读原文~
欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。

