AdaBERT:基于AutoML的BERT自适应压缩


BERT一经问世就刷新了多项NLP任务的SOTA结果。此后大厂玩家们堆卡堆数据不断刷榜,推出了XLNET、RoBERTa、ALBERT、T5、Megatron-LM、Turning-NLP等性能卓越的改进模型。但是这些模型体积愈发庞大,从BERT-large的3.4亿参数到Turing-NLP参数规模的170亿参数。大多数研究者和业界人员只能望而却步,难以训练及应用这些模型,特别是把它们部署到资源受限的实时场景。
近一年来,许多工作开始致力于BERT这类模型做的体积更小,以及有更快的inference速度[1]。比如通过对教师BERT模型的logits,hidden parameter,embedding等进行蒸馏,将大BERT的能力迁移到小模型上;比如对大BERT模型进行量化,使用低精度或混合精度来减轻模型大小;另外还有通过剪枝去掉大BERT中的冗余参数。
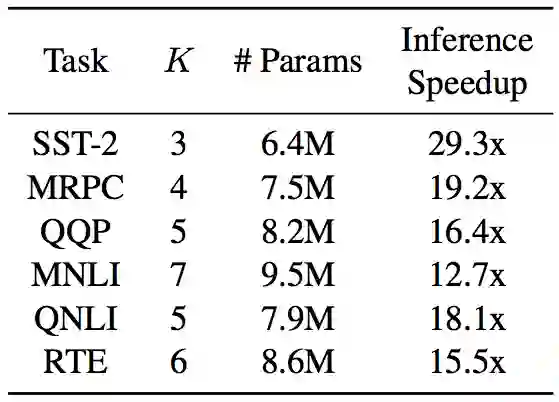
最近一篇paper “AdaBERT: Task-Adaptive BERT Compression with Differentiable Neural Architecture Search”[2](阿里+IJCAI2020)从另一个新角度AutoML探索了BERT压缩。作者认为对于不同的下游任务,大多数现有方法都是将大BERT压缩到同一个结构不变的参数规模更小的BERT。但是BERT从海量语料中学到了大量不同类型的知识,不同的任务往往以不同的方式应用BERT知识[3]。因此有必要根据任务的不同,调整小模型的结构和知识。为了达到这一目标,作者通过可微神经架构搜索(Differentiable Neural Architecture Search, DNAS)将BERT压缩成任务自适应的结构不同的小模型。在GLUE上取得了12.7到29.3倍的inference加速,以及比原始BERT小11.5到17倍的参数规模。
模型解析
AdaBERT的核心idea是把压缩后的小模型结构当做一组可学习的参数,这样不同任务压缩后应该使用什么模型结构就可以交由算法自动地搜索出来。那么如何表达这样一个学习目标呢?
作者给出的方案是把压缩后小模型放在知识蒸馏视角下,将搜索目标融入到学生模型的损失函数中。作者将该任务拆解为两个方面,其一是压缩后模型预测准,能有效的提炼、保留对目标任务有用的知识;其二是压缩后模型体积更小,推理速度更快。
如下图所示,作者综合考虑了两种不同的损失函数:一是面向任务的知识蒸馏损失,为模型搜索过程提供线索;二是模型效率感知型损失,为模型搜索提供约束。这两个损失项使得AdaBERT能在压缩后的模型效率和有效性之间搜索一个合适的trade-off。
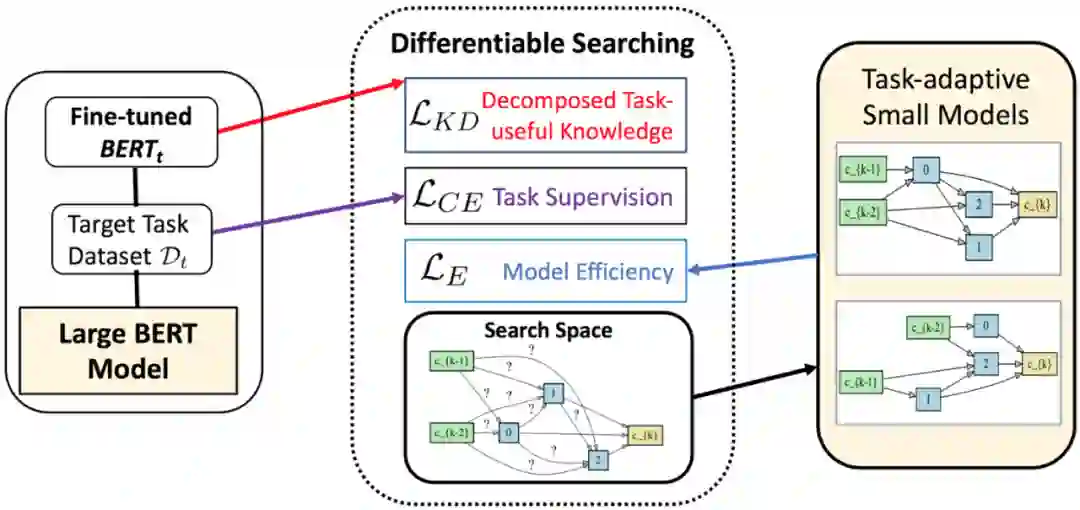
数学形式上,把在目标数据集 上fine-tune的BERT模型记为 ,模型结构的搜索空间记为 ,把搜索到的最优模型结构记为 ,那么整个模型的损失函数就是:
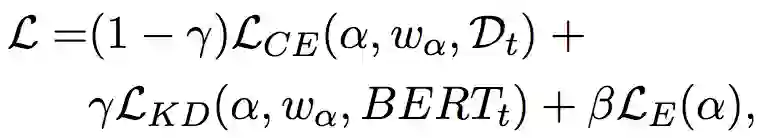
这里 是搜索到的结构 相对应的trainable权重(比如一个Linear Layer的weight和bias); 是与目标数据 相关的交叉熵损失; 和 分别是面向任务的知识蒸馏损失和模型效率损失。 和 是平滑这些损失项的超参。
搜索空间
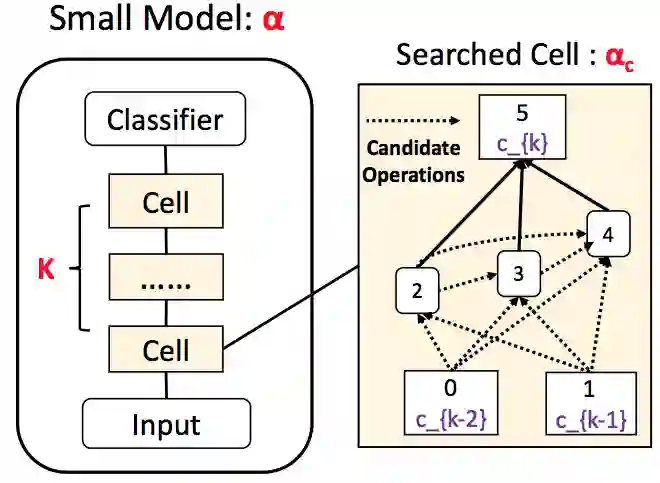
有了学生模型的搜索目标,另一个关键问题就是搜什么样的候选模型。作者采用了如下图所示的模型结构搜索空间,整个模型由若干个搜索基础单元(cell)堆叠而成,每个cell由输入、输出节点和内部隐状态节点组成有向无环图DAG。这样的话模型的搜索对象模型就是堆叠层数 和DAG节点之间的operation边,这些边表示的是hidden state之间的transformation,比如Linear Layer, Convolution等。具体来说,作者在这项工作中采用了一系列基于CNN的轻量级operations,比如不同大小的卷积核、多种pooling、identity(residual连接)、skip connect(空连接)等。此前一些工作已经展示了CNN能有效地处理NLP任务,另外一大原因主要还是对并行处理比较友好,推理速度快。
面向目标任务的知识蒸馏
探测对目标task有用的知识。 有了搜索空间,接下来就是指导搜索的第一项知识蒸馏损失函数项。为了提炼教师模型 对任务有用的知识,作者采用了一组探针分类器(probe model)对教师模型的每一层进行来探测分解,并逐层迁移其中有用的知识到学生模型中。
具体来说,fine tune后 的模型参数首先会被冻结,接着根据目标任务的ground truth label,每个隐藏层都会接一个Linear探针分类器,并进行一定轮数的训练优化。经过这个过程后,教师模型总共会学到 个分类器(BERT-base的 ),其中第 个分类器的分类logit可以被当做从第 层学习到的知识。
对于样本 和学生模型的第 层参数,如果把 记作 的第 层的隐藏表征, 记作压缩后学生模型的第 层隐藏表征,那么单层单样本task-dependent的知识蒸馏损失就是:
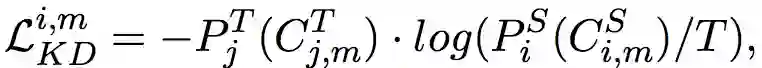
基于attention的分层知识迁移。 对于不同的下游任务,由于BERT中每一层的作用都不一样。作者用attention机制来综合transfer分解后的各层知识:
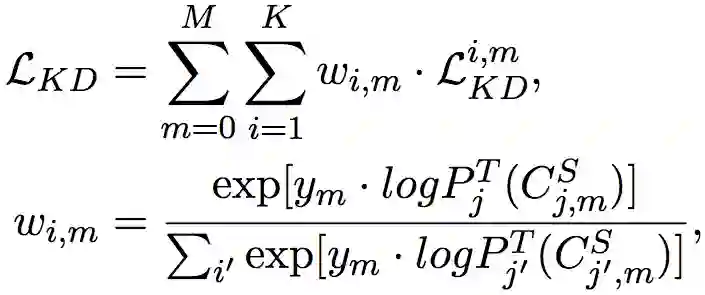
这里表示共 个训练样本, 是第 个样本的标签, 是每个样本依据教师模型探针模型的loss归一后的的权重。用loss来归一化的的动机是对于探针模型的预测结果越准确的层(loss越小),这些层训练的越好或者是越适合目标task,就会被赋予更高的权重。
Efficiency-aware Loss。 最后是和压缩相关的模型效率项,作者把对参数规模和推理时间的约束纳入该项。对于被搜索的模型结构 和模型层数 ,该项loss可以写为:
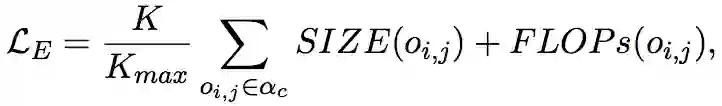
这里 是搜索时的预设最大层, 是需要搜索的模型operation。 和 是 对应的operation归一化后的参数量和浮点运算数目。
可微结构搜索
这篇文章跟现有BERT压缩方法一大不同是根据目标任务来自动搜索适合的模型结构。作者提到通过直接暴力穷举所有候选operation来优化整体损失 的方法是不现实的,因为候选op的组合意味着指数爆炸增长的搜索空间。为了解决这一问题,作者采用了一种可微的搜索方式,将需要搜索的结构变量建模为概率分布变量,以便能利用梯度信息和高效的优化器进行搜索。
为了将搜索目标表示为分布变量,最直接的方式是建模为one-hot变量。但是这样会带来一个问题,也就是离散的采样过程会使得梯度无法回传。因此作者引入了Gumbel Softmax技术,将one-hot的模型结构变量松弛为连续分布 和 。对于堆叠层数 相对应的第 维(表示模型结构最后堆叠 层的概率),以及候选Opearation的第 维(表示DAG中某条边最后导出第 种operation的概率):
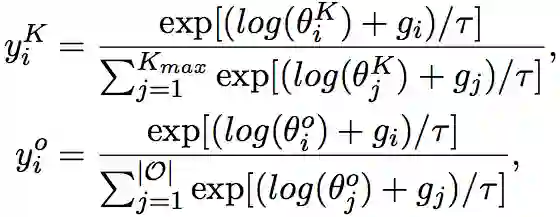
这里 是Gumbel分布中采样得到的随机噪声, 用于控制该连续分布接近one-hot分布的程度。通过这种近似, 和 成为了离散样本的可微代理变量,继而可以直接使用基于梯度的优化器来有效地优化整体loss。
实验表现
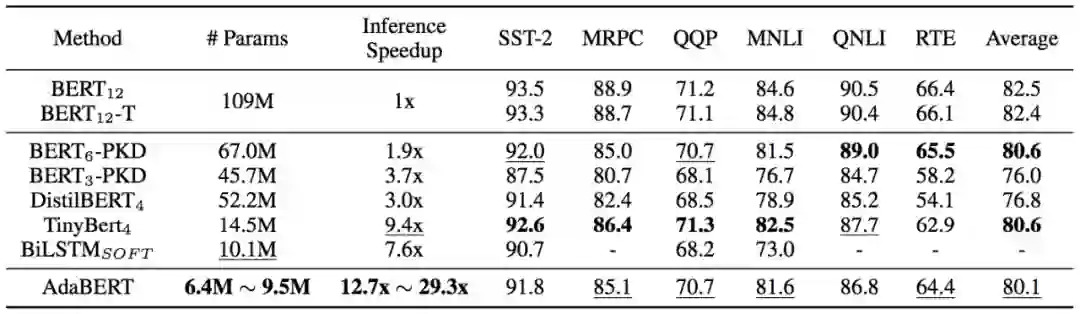
作者在GLUE的6个task上进行了评估,下表总结了AdaBERT的总体压缩效果,包括参数规模、推理速度和分类准确度。整体来看AdaBERT压缩效果显著,同时在这些测评数据集上保持了comparable的准确率。
AdaBERT在不同task上搜到了大小和层数不同的小模型:
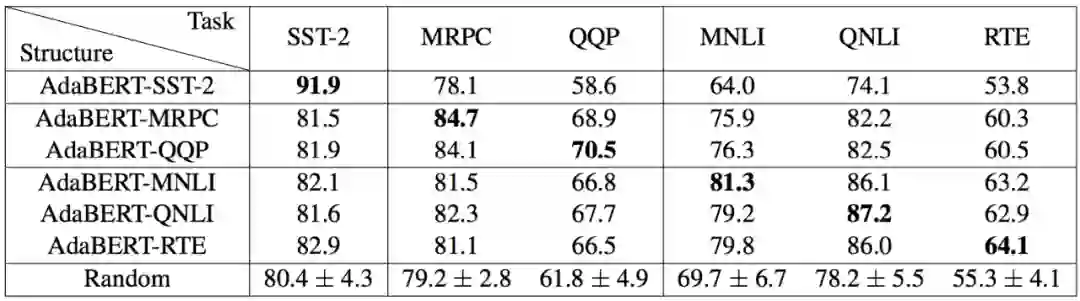
另一个实验是为了验证AdaBERT的自适应性,作者将搜索得到的压缩模型结构应用到了不同的下游任务上。下表给出了跨任务验证的结果,可以看到搜索得到的结构在原始的目标任务上表现最佳,即表中对角线上的数字是最好的。
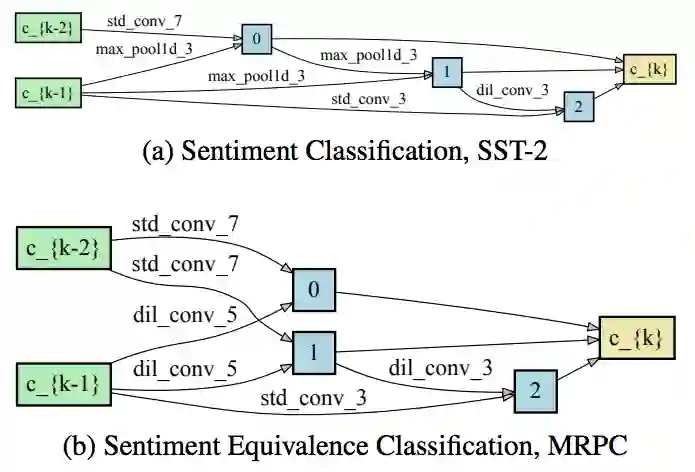
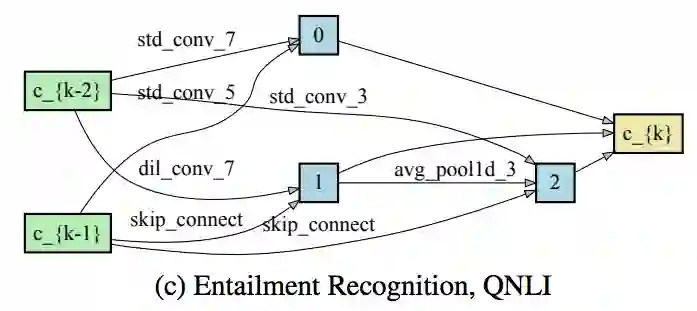
下面是不同任务上搜到的Cell结构基本单元:
总结
除了针对更小更快的压缩目标外,AdaBERT对BERT的任务自适应性也加以考虑。通过task-dependent的知识蒸馏和模型效率两个损失项来指导小模型的搜索,这个思路简洁容易理解,从结果上看也取得了很不错的压缩表现。
把NAS用在BERT压缩中是比较新颖的一个角度,相信这项探索会启发更多AutoML和具体任务的结合应用。而理解BERT这种“通才”模型的工作机制,将其在不同具体任务上发挥“专才”优势也是一个很有意思的问题,毕竟No free lunch。另外文章目前是基于CNN的搜索空间,基于Transformer或其它搜索空间说不定还能做到更高的性能。
参考文献
[1] Prakhar Ganesh, Yao Chen, Xin Lou, Mohammad Ali Khan, Yin Yang, Deming Chen, Marianne Winslett, Hassan Sajjad, Preslav Nakov. Compressing Large-Scale Transformer-Based Models: A Case Study on BERT. arXiv 2020. https://arxiv.org/abs/2002.11985
[2] Daoyuan Chen, Yaliang Li, Minghui Qiu, Zhen Wang, Bofang Li, Bolin Ding, Hongbo Deng, Jun Huang, Wei Lin, and Jingren Zhou. AdaBERT: Task-Adaptive BERT Compression with Differentiable Neural Architecture Search. IJCAI-2020. https://arxiv.org/abs/2001.04246
[3] Anna Rogers, Olga Kovaleva, Anna Rumshisky. A Primer in BERTology: What we know about how BERT works. arXiv 2020. https://arxiv.org/abs/2002.12327
推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏


