一文浅谈Transforme性能优化的常见方法

©作者 | Lukan
单位 | 厦门大学
研究方向 | 机器学习
前言
-
梯度累积(Gradient Accumulation) -
冻结(Freezing) -
自动混合精度(Automatic Mixed Precision) -
8位优化器(8-bit Optimizers) -
梯度检查点(Gradient Checkpointing) -
快速分词器(Fast Tokenizers) -
动态填充(Dynamic Padding) 均匀动态填充(Uniform Dynamic Padding)

梯度累积
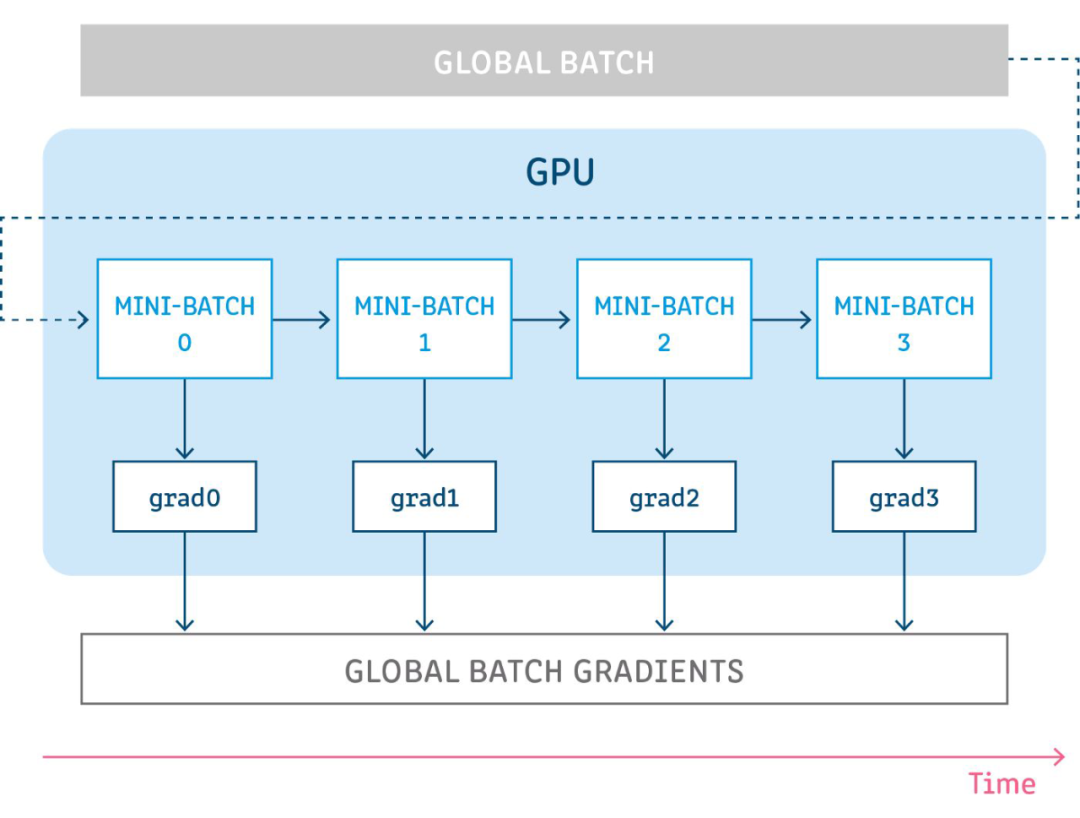
代码实现
steps = len(loader)
# perform validation loop each `validation_steps` training steps!
validation_steps = int(validation_steps * gradient_accumulation_steps)
for step, batch in enumerate(loader, 1):
# prepare inputs and targets for the model and loss function respectively.
# forward pass
outputs = model(inputs)
# computing loss
loss = loss_fn(outputs, targets)
# accumulating gradients over steps
if gradient_accumulation_steps > 1:
loss = loss / gradient_accumulation_steps
# backward pass
loss.backward()
# perform optimization step after certain number of accumulating steps and at the end of epoch
if step % gradient_accumulation_steps == 0 or step == steps:
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm)
optimizer.step()
model.zero_grad()
# perform validation loop
if step % validation_steps == 0:
validation_loop()
冻结
torch.Tensor
的属性
requires_ grad
设置。
代码实现
def freeze(module):
"""
Freezes module's parameters.
"""
for parameter in module.parameters():
parameter.requires_grad = False
def get_freezed_parameters(module):
"""
Returns names of freezed parameters of the given module.
"""
freezed_parameters = []
for name, parameter in module.named_parameters():
if not parameter.requires_grad:
freezed_parameters.append(name)
return freezed_parameters
import torch
from transformers import AutoConfig, AutoModel
# initializing model
model_path = "microsoft/deberta-v3-base"
config = AutoConfig.from_pretrained(model_path)
model = AutoModel.from_pretrained(model_path, config=config)
# freezing embeddings and first 2 layers of encoder
freeze(model.embeddings)
freeze(model.encoder.layer[:2])
freezed_parameters = get_freezed_parameters(model)
print(f"Freezed parameters: {freezed_parameters}")
# selecting parameters, which requires gradients and initializing optimizer
model_parameters = filter(lambda parameter: parameter.requires_grad, model.parameters())
optimizer = torch.optim.AdamW(params=model_parameters, lr=2e-5, weight_decay=0.0)

自动混合精度
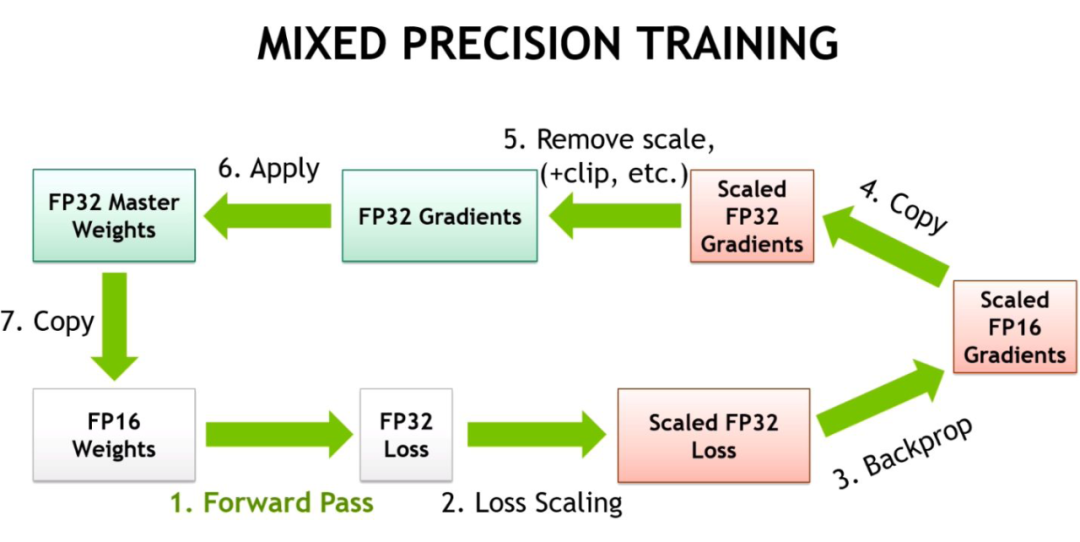
代码实现
from torch.cuda.amp import autocast, GradScaler
scaler = GradScaler()
for step, batch in enumerate(loader, 1):
# prepare inputs and targets for the model and loss function respectively.
# forward pass with `autocast` context manager
with autocast(enabled=True):
outputs = model(inputs)
# computing loss
loss = loss_fn(outputs, targets)
# scale gradint and perform backward pass
scaler.scale(loss).backward()
# before gradient clipping the optimizer parameters must be unscaled.
scaler.unscale_(optimizer)
# perform optimization step
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm)
scaler.step(optimizer)
scaler.update()

8-bit Optimizers
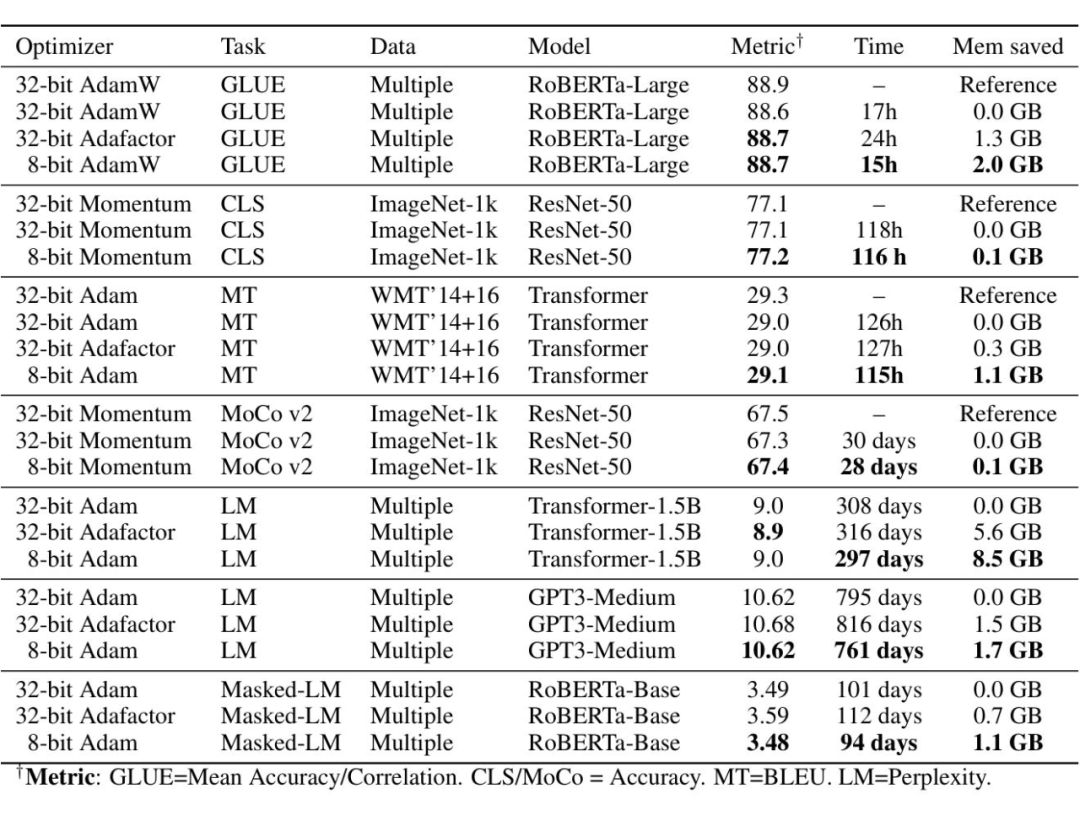
代码实现
!pip install -q bitsandbytes-cuda110
def set_embedding_parameters_bits(embeddings_path, optim_bits=32):
"""
https://github.com/huggingface/transformers/issues/14819#issuecomment-1003427930
"""
embedding_types = ("word", "position", "token_type")
for embedding_type in embedding_types:
attr_name = f"{embedding_type}_embeddings"
if hasattr(embeddings_path, attr_name):
bnb.optim.GlobalOptimManager.get_instance().register_module_override(
getattr(embeddings_path, attr_name), 'weight', {'optim_bits': optim_bits}
)
import bitsandbytes as bnb
# selecting parameters, which requires gradients
model_parameters = filter(lambda parameter: parameter.requires_grad, model.parameters())
# initializing optimizer
bnb_optimizer = bnb.optim.AdamW(params=model_parameters, lr=2e-5, weight_decay=0.0, optim_bits=8)
# bnb_optimizer = bnb.optim.AdamW8bit(params=model_parameters, lr=2e-5, weight_decay=0.0) # equivalent to the above line
# setting embeddings parameters
set_embedding_parameters_bits(embeddings_path=model.embeddings)
print(f"8-bit Optimizer:\n\n{bnb_optimizer}")

梯度检查点
有时候,即使用了上面的几种方法,显存可能还是不够,尤其是在模型足够大的情况下。那么梯度检查点(Gradient Checkpointing)就是压箱底的招数了,这个方法第一次在 “Training Deep Nets With Sublinear Memory Cost”,作者表明梯度检查点可以显著降低显存利用率,从 降低到 ,其中 n 是模型的层数。这种方法允许在单个 GPU 上训练大型模型,或者提供更多内存以增加批量大小,从而更好更快地收敛。
梯度检查点背后的思想是在小数据块中计算梯度,同时在正向和反向传播过程中从内存中移除不必要的梯度,从而降低内存利用率,但是这种方法需要更多的计算步骤来再现整个反向传播图,其实就是一种用时间来换空间的方法。
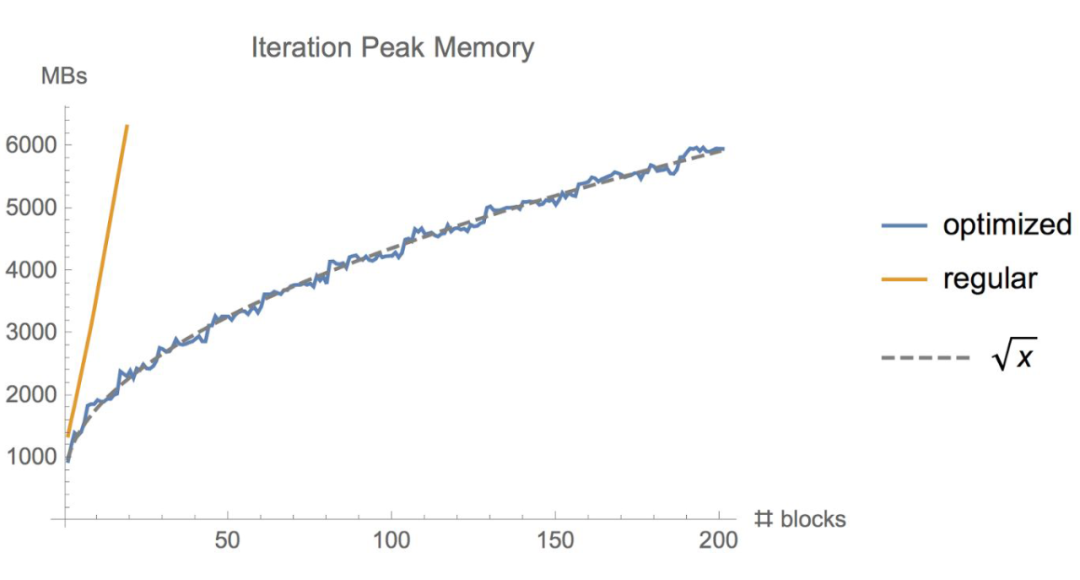
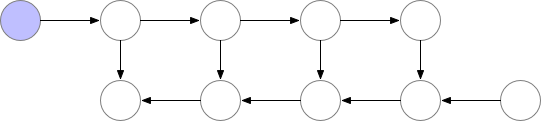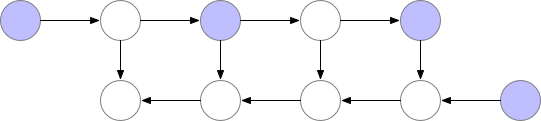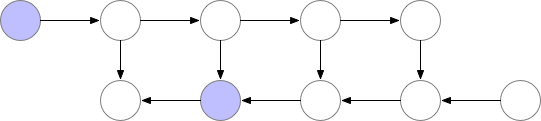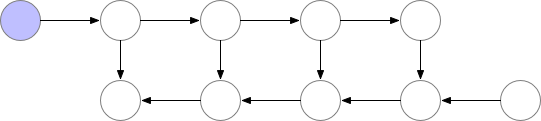
▲ 梯度检查点如何在正向和反向传播过程中工作
PyTorch框架里也有梯度检查点的实现,通过这两个函数:torch.utils.checkpoint.checkpoint 和 torch.utils.checkpoint.checkpoint_sequential 这边引用一段 torch 官网对梯度检查点的介绍。
梯度检查点通过用计算换取内存来工作。检查点部分不是存储整个计算图的所有中间激活以进行反向计算,而是不保存中间激活,而是在反向过程中重新计算它们。它可以应用于模型的任何部分。具体而言,在前向传播中,该函数将以 torch.no_grad() 的方式运行,即不存储中间激活。然而,前向传播保存了输入元组和函数参数。在反向传播时,检索保存的输入和函数,然后再次对函数进行前向传播,现在跟踪中间激活,然后使用这些激活值计算梯度。
代码实现
from transformers import AutoConfig, AutoModel
# https://github.com/huggingface/transformers/issues/9919
from torch.utils.checkpoint import checkpoint
# initializing model
model_path = "microsoft/deberta-v3-base"
config = AutoConfig.from_pretrained(model_path)
model = AutoModel.from_pretrained(model_path, config=config)
# gradient checkpointing
model.gradient_checkpointing_enable()
print(f"Gradient Checkpointing: {model.is_gradient_checkpointing}")

快速分词器
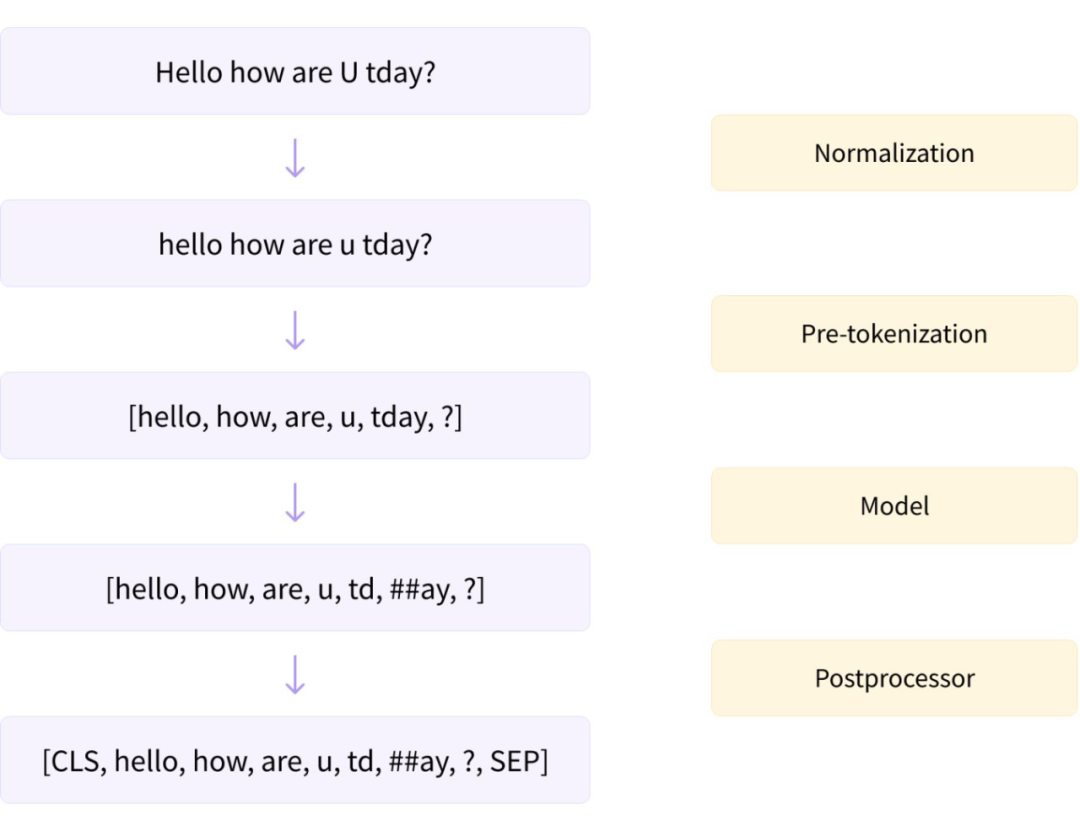
HuggingFace Transformers 提供两种类型的分词器:基本分词器和快速分词器。它们之间的主要区别在于,快速分词器是在 Rust 上编写的,因为 Python 在循环中非常慢,但在分词的时候又要用到循环。快速分词器是一种非常简单的方法,允许我们在分词的时候获得额外的加速。要使用快速分词器也很简单,只要把 transformers.AutoTokenizer 里面的 from_pretrained 方法的 use_fast 的值修改为 True 就可以了。
代码实现
from transformers import AutoTokenizer
# initializing Base version of Tokenizer
model_path = "microsoft/deberta-v3-base"
tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False)
print(f"Base version Tokenizer:\n\n{tokenizer}", end="\n"*3)
# initializing Fast version of Tokenizer
fast_tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=True)
print(f"Fast version Tokenizer:\n\n{fast_tokenizer}")

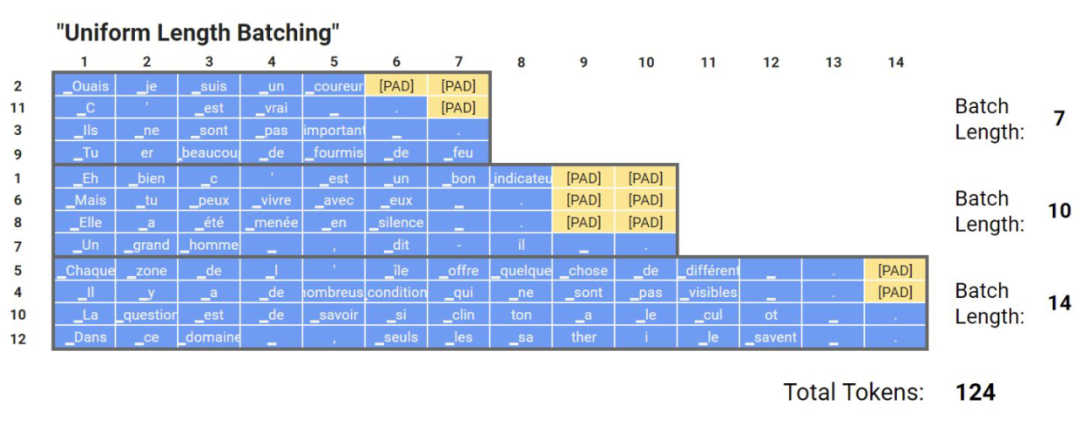
动态填充



均匀动态填充


参考文献
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编



