通用矩阵乘(GEMM)优化与卷积计算
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
作者:黎明灰烬
来源:https://zhuanlan.zhihu.com/p/66958390
本文采用知识共享 署名-非商业性使用-禁止演绎 4.0 国际许可授权
引言
气象预报、石油勘探、核子物理等现代科学技术大多依赖计算机的计算模拟,模拟计算的核心是表示状态转移的矩阵计算。另一方面,计算机图形处理以及近年来兴起的深度学习也和矩阵乘高度相关。而矩阵乘对计算资源消耗较大,除了计算机体系结构的不断更新外,软件优化方面也有大量的研究工作。
本文简要介绍通用矩阵乘(GEMM,General Matrix Multiplication)优化的基本概念和方法、QNNPACK 对特定场景的矩阵乘的优化方法、以及用 GEMM 优化神经网络中卷积计算的一点方向。
旨在帮助大家在概念中建立一些直觉,无甚高论。
通用矩阵乘优化
基本概念
通用矩阵乘(下文简称 GEMM)的一般形式是 𝐶=𝐴𝐵C=AB, 其中 𝐴A 和 𝐵B 涵盖了各自转置的含义。图一是矩阵乘计算中为计算一个输出点所要使用的输入数据。三个矩阵的形状也如图所示。
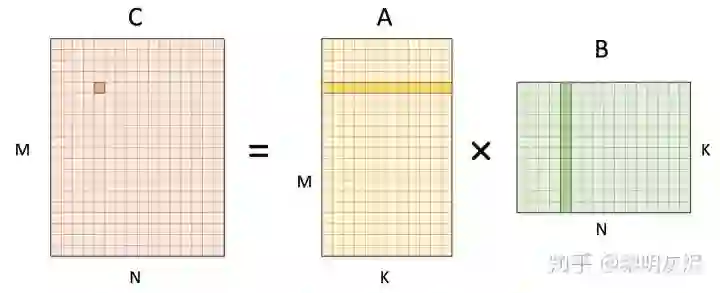
图一:矩阵乘一个输出元素的计算
该计算的伪代码如下。该计算操作总数为 
for (int m = 0; m < M; m++) {for (int n = 0; n < N; n++) {C[m][n] = 0;for (int k = 0; k < K; k++) {C[m][n] += A[m][k] * B[k][n];}}}
How to optimize gemm (https://github.com/flame/how-to-optimize-gemm/wiki)介绍了如何采用各种优化方法,将最基础的计算改进了约七倍(如图二)。其基本方法是将输出划分为若干个 4×4子块,以提高对输入数据的重用。同时大量使用寄存器,减少访存;向量化访存和计算;消除指针计算;重新组织内存以地址连续等。详细的可以参考原文。
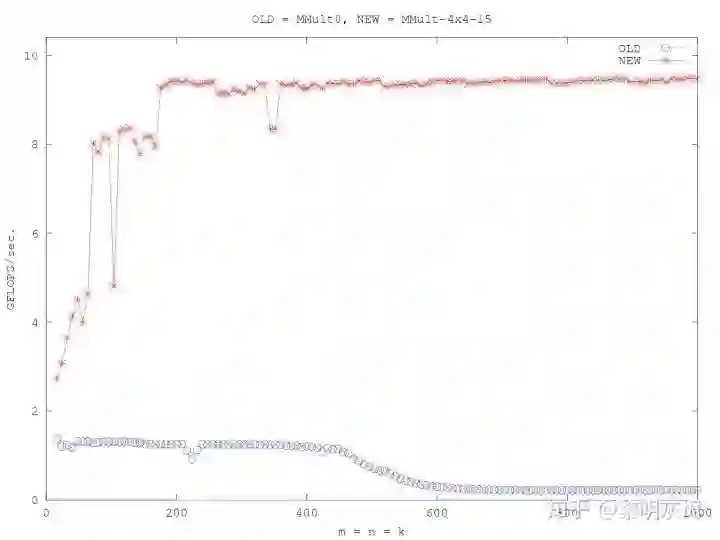
图二:How to optimize gemm 的优化效果
计算拆分展示
本节主要以图形化的方式介绍计算拆分。
图三 将输出的计算拆分为 1×4 的小块,即将 𝑁 维度拆分为两部分。计算该块输出时,需要使用 𝐴 矩阵的 1 行,和 𝐵 矩阵的 4 列。
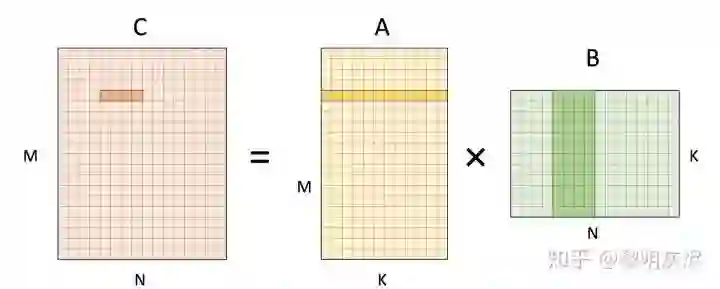
图三:矩阵乘计算 1×4输出
下面是该计算的伪代码表示,这里已经将 1×4 中 𝑁N 维度的内部拆分进行了展开。这里的计算操作数仍然是 2𝑀𝑁𝐾 ,这一点在本文中不会有变化。这里的内存访问操作数尚未出现变化,仍然是 4𝑀𝑁𝐾,但接下来会逐步改进。
for (int m = 0; m < M; m++) {for (int n = 0; n < N; n += 4) {C[m][n + 0] = 0;C[m][n + 1] = 0;C[m][n + 2] = 0;C[m][n + 3] = 0;for (int k = 0; k < K; k++) {C[m][n + 0] += A[m][k] * B[k][n + 0];C[m][n + 1] += A[m][k] * B[k][n + 1];C[m][n + 2] += A[m][k] * B[k][n + 2];C[m][n + 3] += A[m][k] * B[k][n + 3];}}}
简单的观察即可发现,上述伪代码的最内侧计算使用的矩阵 𝐴 的元素是一致的。因此可以将 𝐴[𝑚][𝑘] 读取到寄存器中,从而实现 4 次数据复用(这里不再给出示例)。一般将最内侧循环称作计算核(micro kernel)。进行这样的优化后,内存访问操作数量变为 (2+1/4)𝑀𝑁𝐾,其中 1/4是对 𝐴 优化的效果。
类似地,我们可以继续拆分输出的 𝑀 维度,从而在内侧循环中计算 4×4 输出,如图四。

图四:矩阵乘计算 4×44×4输出
同样地,将计算核心展开,可以得到下面的伪代码。这里我们将 1×4 中展示过的 𝑁 维度的计算简化表示。这种拆分可看成是 4×1×4,这样 𝐴 和 𝐵 的访存均可复用四次。由于乘数效应,4×4 的拆分可以将对输入数据的访存缩减到 2𝑀𝑁𝐾+1/4𝑀𝑁𝐾+1/4𝑀𝑁𝐾=(2+1/2)𝑀𝑁𝐾)。这相对于最开始的 4𝑀𝑁𝐾 已经得到了 1.6X 的改进,这些改进都是通过展开循环后利用寄存器存储数据减少访存得到的。
for (int m = 0; m < M; m += 4) {for (int n = 0; n < N; n += 4) {C[m + 0][n + 0..3] = 0;C[m + 1][n + 0..3] = 0;C[m + 2][n + 0..3] = 0;C[m + 3][n + 0..3] = 0;for (int k = 0; k < K; k++) {C[m + 0][n + 0..3] += A[m + 0][k] * B[k][n + 0..3];C[m + 1][n + 0..3] += A[m + 1][k] * B[k][n + 0..3];C[m + 2][n + 0..3] += A[m + 2][k] * B[k][n + 0..3];C[m + 3][n + 0..3] += A[m + 3][k] * B[k][n + 0..3];}}}
到目前为止,我们都是在输出的两个维度上展开,而整个计算还包含一个削减(Reduction)维度 𝐾。图五展示了在计算 4×4 输出时,将维度 𝐾 拆分,从而每次最内侧循环计算出输出矩阵 𝐶 的 4x4 部分和。
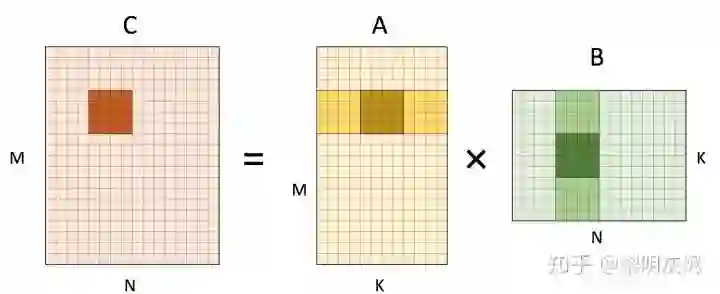
图五:矩阵乘计算 4×4 输出对 𝐾 维度的拆分
下面展示的是这部分计算的展开伪代码,其中维度 𝑀 和 𝑁 已经被简写。在这里,最内侧循环发生的计算次数已经从最朴素版本的 

for (int m = 0; m < M; m += 4) {for (int n = 0; n < N; n += 4) {C[m + 0..3][n + 0..3] = 0;C[m + 0..3][n + 0..3] = 0;C[m + 0..3][n + 0..3] = 0;C[m + 0..3][n + 0..3] = 0;for (int k = 0; k < K; k += 4) {C[m + 0..3][n + 0..3] += A[m + 0..3][k + 0] * B[k + 0][n + 0..3];C[m + 0..3][n + 0..3] += A[m + 0..3][k + 1] * B[k + 1][n + 0..3];C[m + 0..3][n + 0..3] += A[m + 0..3][k + 2] * B[k + 2][n + 0..3];C[m + 0..3][n + 0..3] += A[m + 0..3][k + 3] * B[k + 3][n + 0..3];}}}
在对 𝑀 和 𝑁 展开时,我们可以分别复用 𝐵 和 𝐴 的数据;在对 𝐾 展开时,我们可以将部分和累加在寄存器中,最内层循环一次迭代结束时一次写到 𝐶 的内存中。那么内存访问次数为 
到目前为止,我们已经对计算进行了三次维度拆分、展开并寄存器化(代码未展示)和访存复用。这对最基础版本计算似乎已经足够了,因为数百条稳定的顺序计算指令对处理器流水线已经很友好,且编译器可以帮助我们做好软件流水这样的指令调度。
然而一条计算指令只能完成一次乘加操作(MLA)效率还是比较低。实际上即使是最低端的移动手机处理器都会带有 SIMD 支持,访存和计算都可以向量化。因此我们可以再进一步,利用向量操作提高计算的性能。
在介绍向量化计算的细节时,伪代码是很难理解的,下面依据图六介绍量化计算的具体过程。图六左侧部分的三幅小图分别展示了两个 4×4 矩阵相乘向量化的要素:首先是计算一个输出元素使用到的输入元素;然后是对各个矩阵内存的编码,均以行优先的形式编号;最后是向量化的具体计算方法。
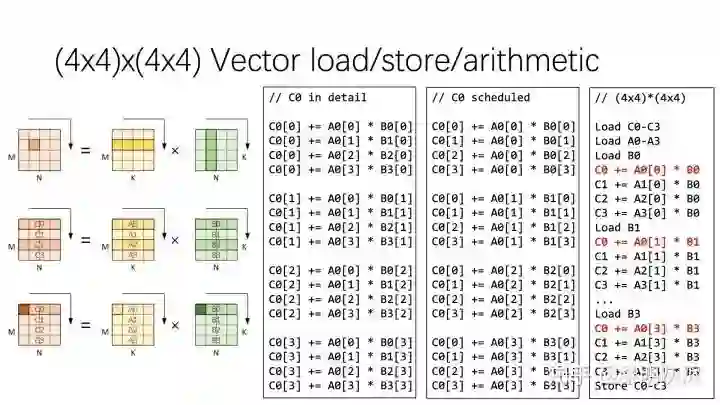
图六:两个 4×4矩阵相乘的向量化
这里的向量编号方式假定输入输出的内存布局都是行优先,那么两个输入各自的 16 个元素通过 4 次向量访存即可加载到寄存器中。由矩阵乘的规则可知,输入 𝐴 中的行可一次性用作输出的计算,而输入 𝐵B 的行则要拆分使用。这也是向量计算最容易出错的地方。
图六右侧列出了三份伪代码。第一份 C0 in detail 是计算 C0 中四个输出元素的朴素方法的展开,连续四次计算得到一个 C0 元素的结果。将计算过程稍作重排,即可得到 C0 scheduled 展示的计算,这里连续的四次计算分别处理了 C0 中四个元素的 1/4 结果。在连续的四次计算中,重排前只有对 𝐴A 的访存是连续的,重排后 𝐵 和 𝐶 的访存都是连续的。那么向量化这些访存和计算,即可得到第三列伪代码中红色 C0 部分。而第三列是通过对 C1、C2、C3 进行类似的处理得到的。
施行向量化操作后,原本需要 64 条计算指令的计算过程所需指令减少到 16 条,访存也有类似效果。而向量化对处理器资源的高效使用,又带来了进一步优化空间,例如可以一次计算 8×8 个局部输出。
处理内存布局
上一小节列出的是在输入输出原有内存布局上所做的优化。在最后向量化时,每次内存访问都是四个元素。当这些元素为单精度浮点数时,内存大小为 16 字节,这远小于现代处理器高速缓存行大小(Cache line size)——后者一般为 64 字节。在这种情况下,内存布局对计算性能的影响开始显现。
图七展示的是不同内存组织方式对的影响。图中两者都是行优先的内存排列,区别在于左侧小方块内部是不连续的,右侧小方块内部是连续的。图中用几个数字标记了各个元素在整个内存中的编号。

图七:不同的局部内存组织
想象一下在这两者不同内存组织方式的输入输出中访存,每次向量化内存加载仍是 4 个元素。对于一个局部计算使用到的小方块,左侧四次访存的内存都是不连续的,而右侧则是连续的。当数据规模稍大(一般情况肯定足够大了),左侧的连续四次向量化内存加载都会发生高速缓存缺失(cache miss),而右侧只会有一次缺失。
在常规的数据规模中,由于左侧会发生太多的高速缓存缺失,又由于矩阵乘这样的计算对数据的访问具有很高的重复性,将它重排成右侧的内存布局减少高速缓存缺失,可显著地改进性能。另一方面,矩阵乘中两个输入矩阵往往有一个是固定的参数,在多次计算中保持不变。那么可以在计算开始前将其组织成特定的形状,这种优化甚至可以将性能提高 2x。
到这里为止,对 4×4 计算已经有了足够的优化,可以开始考虑视野更广一些的全局优化。图八是一个关于全局优化的小示例。

图八:矩阵乘的全局优化一瞥
图中字母标记的是全局性的工作顺序,即输出数据中外层循环迭代方式。左侧小图是常规的行优先遍历方式,中间小图是列有限的遍历方式。这两者的区别是 𝑀 和 𝑁 两个维度的循环哪个在最外层。
上文已经对 𝑀 和 𝑁 两个维度分别进行了一次拆分,这里可以继续这种拆分。右侧的图例中是将 𝑀 和 𝑁 两个维度分别拆分为 𝑋,2,4 三部分,将外层拆分都交换到外层循环。下面是相应的伪代码。
for (int mo = 0; mo < M; mo += 8) {for (int no = 0; no < N; no += 8) {for (int mi = 0; mi < 2;mi ++) {for (int ni = 0; ni < 2; ni++) {int m = mo + mi * 4;int n = no + ni * 4;C[m + 0..3][n + 0..3] = 0;C[m + 0..3][n + 0..3] = 0;C[m + 0..3][n + 0..3] = 0;C[m + 0..3][n + 0..3] = 0;for (int k = 0; k < K; k += 4) {C[m + 0..3][n + 0..3] += A[m + 0..3][k + 0] * B[k + 0][n + 0..3];C[m + 0..3][n + 0..3] += A[m + 0..3][k + 1] * B[k + 1][n + 0..3];C[m + 0..3][n + 0..3] += A[m + 0..3][k + 2] * B[k + 2][n + 0..3];C[m + 0..3][n + 0..3] += A[m + 0..3][k + 3] * B[k + 3][n + 0..3];}}}}}
经过这样的调度,从整体计算来看,可看作是将 4×4 计算拓展成了 8×8 ,其实是同一种思路。
QNNPACK 的矩阵乘优化
QNNPACK (Quantized Neural Network PACKage) 是 Facebook 开源的专门用于量化神经网络的计算加速库。QNNPACK 和 NNPACK (Neural Network PACKage) 的作者都是 Marat Dukhan 。到目前为止,QNNPACK 仍然是已公开的,用于移动端(手机)的,性能最优的量化神经网络加速库。
QNNPACK 开源时附带了一份技术报告性质的博客。本节将结合上节的内容简要地从博客原作中抽取一些关于 GEMM 的内容。
量化神经网络
神经网络计算一般都是以单精度浮点(Floating-point 32, FP32)为基础。而网络算法的发展使得神经网络对计算和内存的要求越来越大,以至于移动设备根本无法承受。为了提升计算速度,量化(Quantization)被引入到神经网络中,主流的方法是将神经网络算法中的权重参数和计算都从 FP32 转换为 INT8 。

两种数值表示方法的方程如上。如果对量化技术的基本原理感兴趣,可以参考 Neural Network Quantization Introduction 。
应用量化技术后,计算方面显现了若干个新的问题。首先是 NNPACK 这样用于 FP32 的计算加速库无法用于 INT8 ,这导致我们需要新的加速计算方法。再者是输入输出都转化成 INT8 后,内存带宽需求直接下降为 1/4 。随之而来的内存容量需求变化出现了一些新的优化机会。而 QNNPACK 充分利用了这些优化方法,并结合神经网络领域的特点,大幅改进了计算性能。
另一方面,Gemmlowp 是 Google 开源的低精度 GEMM 加速库。在加速之外,Gemmlowp 的特别之处是提供了一套用定点计算模拟浮点计算的机制。例如 
计算划分与削减维度
和上节所述类似,QNNPACK 的计算也是基于对输出的划分,拆分成如图九的 𝑀𝑅×𝑁𝑅MR×NR 小块。这里需要注意的一点是,原文图例中对 𝐵B 的标记有笔误,𝐵B 的列高度应该是 𝐾K 而非 𝑁N。(我们向 QNNPACK 报告了这一问题,目前尚未得到修正。)
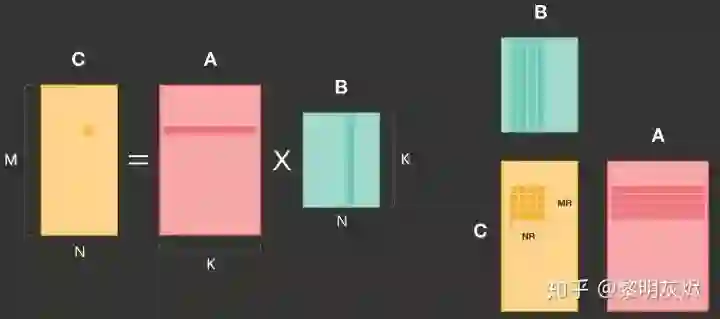
图九:QNNPACK 矩阵乘划分示例
QNNPACK 实现了 4×8 的和 8×8 两种计算核(micro kernel),分别用于支持 armv7 和 arm64 指令集的处理器。这两种计算核在原理上区别不大,后者主要利用了更多的寄存器和双发射(Dual Issue)以提高计算的并行度。
拆分后 𝑀𝑅×𝑁𝑅 计算块使用的内存为 𝑀𝑅∗𝑁𝑅+𝑀𝑅∗𝐾+𝑁𝑅∗𝐾。由于常规的神经网络计算 𝐾<1024 , 那么这里的内存消耗一般不超过 16KB,可以容纳在一级高速缓存(L1 Cache)中。QNNPACK 的这一发现是其矩阵乘优化的基础。
如图十所示,在计算 𝑀𝑅×𝑁𝑅 小块时,传统的方法(即上一节的方法)是在 𝐾 维度上拆分,在一次计算核的处理中,仅计算 𝐾 维的局部。那么在每次计算核的处理中,都会发生对输出的加载和存储——要将本次计算产生的部分和累加到输出中。
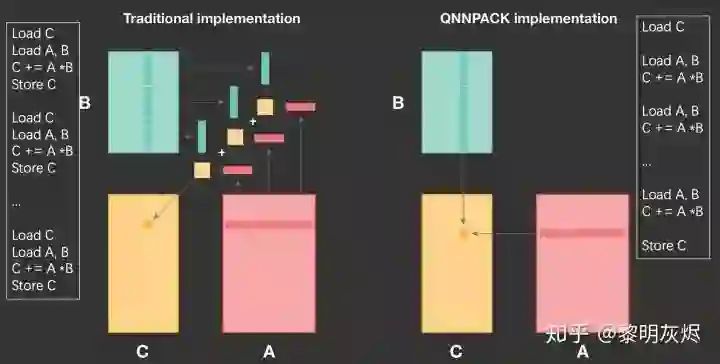
图十:QNNPACK 和传统方法计算削减维度的对比
而 QNNPACK 的做法是将整个 𝐾K 维全部在计算核中处理完,这样就几乎完全消除了输出部分和的访存。两种的差异的细节可以参考图十两侧的伪代码。这里所说的「将整个 𝐾 维全部」并不是指 𝐾 维不拆分——在实际计算中 𝐾K 维还是会以 8 为基础拆分——而是指拆分后不和其他维度交换(interchange)。
内存组织的特点
上节中曾提到,对内存的重新组织(Repacking)可以改进高速缓存命中率,从而提高性能。但是这种重新组织也是有开销的。
计算核中最小的计算单元处理的是两个 4×4 矩阵相乘。传统的方法由于 𝐾 可能很大,需要对输入内存进行重新组织,防止相邻的访存引起高速缓存冲突,如图十一。
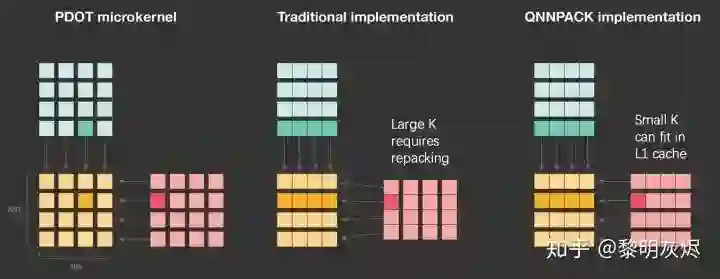
图十一:QNNPACK 和传统矩阵乘对局部计算的处理
而在量化神经网络中,由于 𝐾K 比较小,计算核处理中使用到的内存完全可以容纳在一级高速缓存中,即使不重新组织内存,高速缓存的重用率也足够高。
参考图七左侧部分,QNNPACK 计算核一次会使用 8 行输入(假定图中绘制以 8 为基础分块)。尽管对第一个 8×8 矩阵块的向量化加载可能全部是高速缓存缺失(Cache miss),第二个 8×8 则全部命中——因为它们已经作为同在一个高速缓存行的内容随第一个矩阵块加载到了高速缓存中。其他矩阵块也是类似情况。
采用了这些基于神经网络领域先验知识的优化方法后,QNNPACK 击败了所有神经网络量化领域的用于移动端加速库。不过,QNNPACK 的拆分着眼于削减维度,没有在输出维度上做全局调度。我们在 QNNPACK 基础上实现了 𝑀 和 𝑁 维度的外层循环拆分调度,简单的实验获得了相对于 QNNPACK 1.1x 的性能表现。
卷积与矩阵乘
卷积(Convolution)是神经网络的核心计算。而卷积的变种极为丰富,本身计算又比较复杂,因此其优化算法也多种多样,包括 im2col、Winograd 等等。本节重点关注卷积和矩阵乘的关系。
im2col 计算方法
作为早期的深度学习框架,Caffe 中卷积的实现采用的是基于 im2col 的方法,至今仍是卷积重要的优化方法之一。
im2col 是计算机视觉领域中将图片的不同通道(channel)转换成矩阵的列(column)的计算过程。Caffe 在计算卷积时,首先用 im2col 将输入的三维数据转换成二维矩阵,使得卷积计算可表示成两个二维矩阵相乘,从而充分利用已经优化好的 GEMM 库来为各个平台加速卷积计算。
图十二是卷积的 im2col 过程的示例。随着卷积过滤器在输入上滑动,将被使用的那部分输入展开成一行大小为 𝐼𝐶×𝐾𝐻×𝐾𝑊 的向量。在滑动结束后,则得到特征矩阵 (𝐻×𝑊)×(𝐼𝐶×𝐾𝐻×𝐾𝑊) 。将过滤器展开成 (𝑂𝐶)×(𝐼𝐶×𝐾𝐻×𝐾𝑊) 的矩阵,那么卷积即可表示成这两个矩阵相乘的结果(特征矩阵要进行转置操作)。
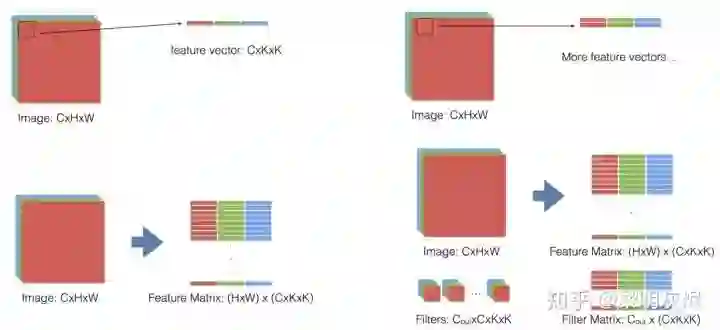
图十二:im2col 过程
im2col 计算卷积使用 GEMM 的代价是额外的内存开销,输入会使用额外的 𝐾𝐻×𝐾𝑊 倍内存。当卷积核尺寸是 1×1 时,由于不需要重排输入,GEMM 可以直接在原始输入上运行,并且不需要使用额外的内存。
内存布局与卷积性能
神经网络中卷积的内存布局主要有 NCHW 和 NHWC 两种。最后重点分析一下 im2col 1×1 卷积性能和内存布局的关系。
对于不需要额外调整输入的 1×1 卷积,将 NCHW 内存布局的卷积对应到矩阵乘 𝐶=𝐴𝐵 时,𝐴 是卷积核(filter),𝐵 是输入(input)。各个矩阵的维度如图十二所示。
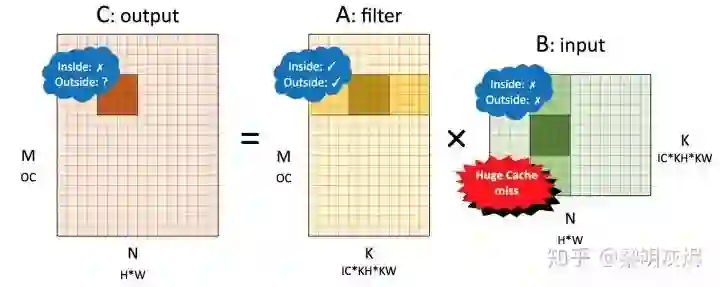
图十二:NCHW 内存布局卷积转换成的矩阵乘
对该矩阵施行划分后,将计算核的访存局部性表现标记在图十二中。其中 Inside 表示小块矩阵乘内部的局部性,Outside 表示在削减维度方向的局部性。
对输出而言,小块内向量化访存局部性较差,外部表现取决于全局计算方向——行优先则局部性较好,列优先则较差。由于卷积核可以事先重排内存,因此视其局部性都较好。输入则小块内外都较差,因为削减维度是列优先的,几乎每次加载输入都会发生高速缓存缺失。
图十三是与之相对的 NHWC 内存布局的示例。值得注意的是,NHWC 和 NCHW 中 𝐴、𝐵 矩阵所代表的张量发生了调换——𝑂𝑢𝑡𝑝𝑢𝑡=𝐼𝑛𝑝𝑢𝑡×𝐹𝑖𝑙𝑡𝑒𝑟。具体的拆分方式仍然一样。
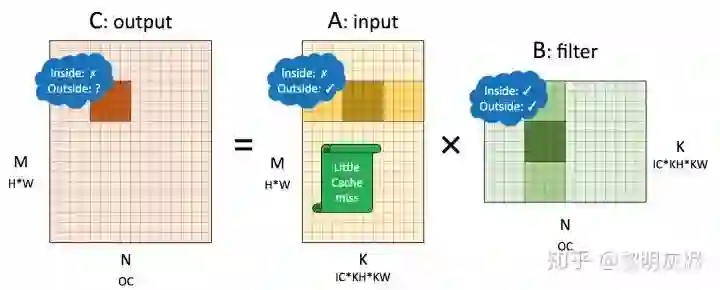
图十三:NHWC 内存布局卷积转换成的矩阵乘
在 NHWC 中,输出的局部性表现和 NCHW 一样。同样的,卷积核也视作局部性表现较好。对于输入,小方块的内部局部性表现不是很好,因为几次向量加载的地址不连续;而外部局部性表现则较好,因为在削减维度滑动使用的内存是连续的——这一点在「处理内存布局」小节中已有阐述。
可以看到,对于 1×1如果采用 im2col 方法计算,且不对输入输出进行额外的内存重排,那么 NHWC 的访存特征是显著优于 NCHW 的。
总结
至此,本文介绍了 GEMM 优化的基本方法概念,在神经网络领域中 QNNPACK 基于量化对 GEMM 的优化,和 im2col 方法对卷积计算及其内存布局的意义。GEMM 优化实质上是个非常重要,且和特定领域绑定很强的话题,更进一步的内容需要进入到特定领域深入研究。如果对 GEMM 各种优化技巧所带来的性能收益感兴趣,可以参考 How to optimize gemm。如果对 GEMM 优化和体系结构结合的理论感兴趣,可以参考 Anatomy of High-Performance Matrix Multiplication 。
参考
https://github.com/flame/how-to-optimize-gemm/wiki
https://github.com/pytorch/QNNPACK
https://dl.acm.org/citation.cfm?id=1356053
https://github.com/Yangqing/caffe/wiki/Convolution-in-Caffe:-a-memo
*延伸阅读
你也可以训练超大神经网络!谷歌开源GPipe库
开放下载!复旦大学邱锡鹏教授发布教科书《神经网络与深度学习》
神经网络训练tricks
李飞飞高徒、AI“网红”Karpathy:训练神经网络不得不看的33个技巧
点击左下角“阅读原文”,即可申请加入极市目标跟踪、目标检测、工业检测、人脸方向、视觉竞赛等技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按关注极市平台
觉得有用麻烦给个在看啦~


