预训练永不止步,游戏问答语言模型实操

©PaperWeekly 原创 · 作者|程任清、刘世兴
单位|腾讯游戏知几AI团队
研究方向|自然语言处理

简介
https://share.weiyun.com/S0CeWKGM (UER版)
https://share.weiyun.com/qqJaHcGZ(huggingface版)

基于UER-PY——中文预训练初探
2.1 MLM预训练
-
步骤 1:准备训练数据(这里需要注意:语料的格式是一行一个句子,不同文档使用空行分隔,前提是 target 是 bert(包括 mlm 和 nsp,如果 targe 只有 mlm 的话,不需要空行分隔,当时踩了这个坑) -
步骤 2:对语料进行预处理 -
步骤 3:进行预训
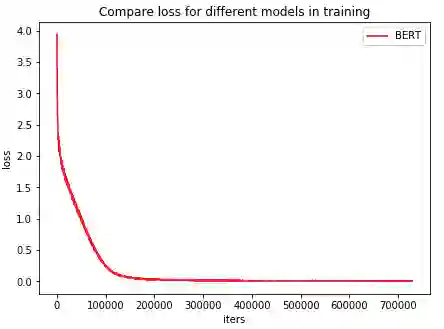
2.2 词粒度预训练
#构建领域词典
python3 scripts/build_vocab.py --corpus_path ../data/all_qa_log.txt \
--vocab_path ../data/zhiji_word_pre/zhiji_word_vocab.txt \
--workers_num 10 \
--min_count 30 \
--tokenizer space
python3 scripts/dynamic_vocab_adapter.py --old_model_path ../data/wiki_word_model/wiki_bert_word_model.bin \
--old_vocab_path ../data/wiki_word_model/wiki_word_vocab.txt \
--new_vocab_path ../data/zhiji_word_pre/zhiji_word_vocab.txt \
--new_model_path ../data/zhiji_word_pre/zhiji_bert_word_model.bin
#将下行
w = line.strip().split()[0] if line.strip() else " "
#替换为
w = line.strip("\n") if line.strip("\n") else " "

3.1 全词掩码预训练
3.1.1 准备训练数据
For Chinese models, we need to generate a reference files, because it's tokenized at the character level.
**Q :** Why a reference file?
**A :** Suppose we have a Chinese sentence like: `我喜欢你` The original Chinese-BERT will tokenize it as`['我','喜','欢','你']` (character level). But `喜欢` is a whole word. For whole word masking proxy, we need a result like `['我','喜','##欢','你']`, so we need a reference file to tell the model which position of the BERT original tokenshould be added `##`.

```bash
export TRAIN_FILE=/path/to/dataset/train.txt
export tokens_RESOURCE=/path/to/tokens/tokenizer
export BERT_RESOURCE=/path/to/bert/tokenizer
export SAVE_PATH=/path/to/data/ref.txt
python examples/contrib/run_chinese_ref.py \
--file_name=path_to_train_or_eval_file \
--tokens=path_to_tokens_tokenizer \
--bert=path_to_bert_tokenizer \
--save_path=path_to_reference_file
#训练数据样例
我喜欢你
兴高采烈表情怎么购买
我需要一张国庆投票券
#对应生成的reference file
[3]
[2, 3, 4, 5, 6, 8, 10]
[3, 7, 8, 9, 10]
#以 兴高采烈表情怎么购买 为例
分词后:['兴高采烈表情', '怎么', '购买']
bert分词后:['[CLS]', '兴', '高', '采', '烈', '表', '情', '怎', '么', '购', '买', '[SEP]']
reference file对应的为:[2, 3, 4, 5, 6, 8, 10] (每个值为对应的bert分词结果的位置索引,并需要和前字进行合并的)
结合bert分词和reference file可以生成:['[CLS]', '兴', '##高', '##采', '##烈', '##表', '##情', '怎', '##么', '购', '##买', '[SEP]']
3.1.2 进行 wwm 训练
data_dir="/home/tione/notebook/data/qa_log_data/"
train_data=$data_dir"qa_log_train.json"
valid_data=$data_dir"qa_log_val.json"
pretrain_model="/home/tione/notebook/data/chinese-bert-wwm-ext"
python -m torch.distributed.launch --nproc_per_node 8 run_mlm_wwm.py \
--model_name_or_path $pretrain_model \
--model_type bert \
--train_file $train_data \
--do_train \
--do_eval \
--eval_steps 10000 \
--validation_file $valid_data\
--max_seq_length 64 \
--pad_to_max_length \
--num_train_epochs 5.0 \
--per_device_train_batch_size 128 \
--gradient_accumulation_steps 16 \
--save_steps 5000 \
--preprocessing_num_workers 10 \
--learning_rate 5e-5 \
--output_dir ./output_qalog \
--overwrite_output_dir
3.1.2.1 踩坑:transformers 新版本数据读写依赖了 datasets,这个库带来了什么问题?
#如新建spv环境
conda create --prefix=~/notebook/python_envs/spv
conda activate notebook/python_envs/spv/
这个库需要连接外网来获取数据读取脚本(会出现 ConnectionError)。解决的方法是去 datasets 的 git 上下载我们需要的脚本到本地,比如我们需要 text.py 的脚本(即一行一行读取训练数据),在下方链接下载 text.py,并修改 run_mlm_wwm.py 代码。
https://github.com/huggingface/datasets/tree/1.1.2/datasets/text
#将
datasets = load_dataset(extension, data_files=data_files)
#修改为:
datasets = load_dataset("../test.py",data_files=data_files)
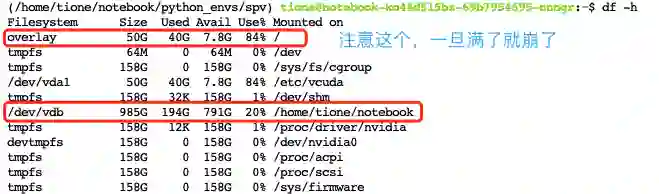
3.1.2.2 踩坑:训练数据太大(数据千万级),程序容易被 kill,可以通过下面方法去避免。
#这里增加cache_file_names,制定cache路径。
#这里其实还有一个坑,我们一直以为datasets的是Dataset类,所以指定的参数是cache_file_name,然后它却是DatasetDict,参数为cache_file_names
tokenized_datasets = datasets.map(
tokenize_function,
batched=True,
num_proc=data_args.preprocessing_num_workers,
remove_columns=[text_column_name],
load_from_cache_file=not data_args.overwrite_cache, cache_file_names={"train":"/home/tione/notebook/wwm/process_data/processed_train.arrow","validation":"/home/tione/notebook/wwm/process_data/processed_validation.arrow"},
)
在使用 reference file 的时候很容易被 kill 掉。调试的时候会卡到第 5 行,然后就被 kill 了。
def add_chinese_references(dataset, ref_file):
with open(ref_file, "r", encoding="utf-8") as f:
refs = [json.loads(line) for line in f.read().splitlines() if (len(line) > 0 and not line.isspace())]
assert len(dataset) == len(refs)
dataset_dict = {c: dataset[c] for c in dataset.column_names}
dataset_dict["chinese_ref"] = refs
return Dataset.from_dict(dataset_dict)
import json
with open("qa_log_data/qa_log_train.json","w") as fout:
with open("qa_log_data/qa_log_train.txt","r") as f1:
with open("qa_log_data/ref_train.txt","r") as f2:
for x,y in zip(f1.readlines(),f2.readlines()):
y = json.loads(y.strip("\n"))
out_dict = {"text":x.strip("\n"),"chinese_ref":y}
out_dict = json.dumps(out_dict)
fout.write(out_dict+"\n")
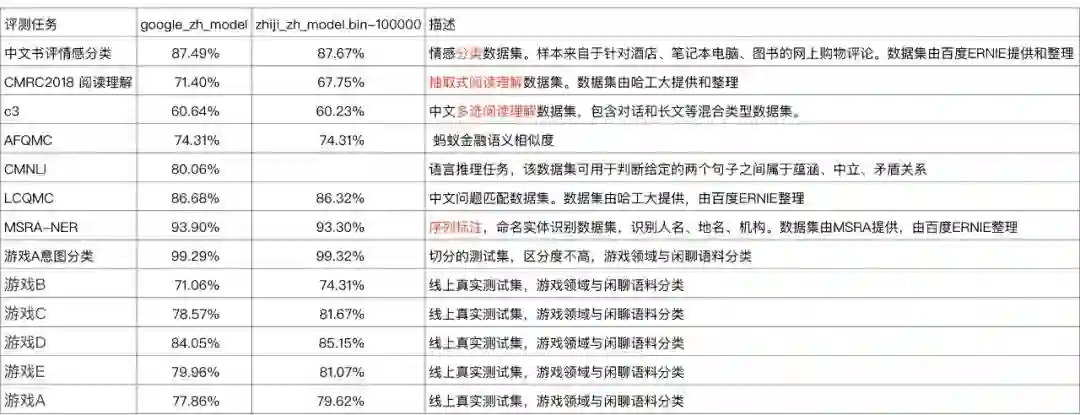
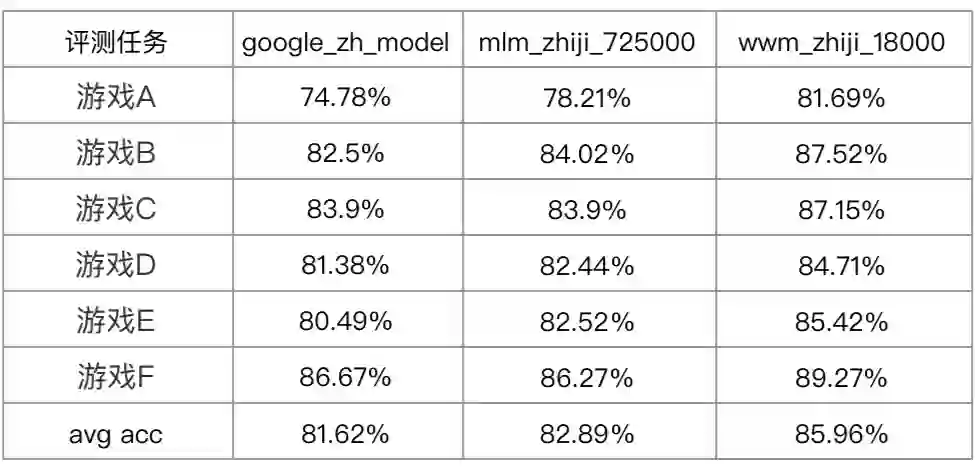
3.1.3 wwm评测
3.2 多任务预训练
3.2.1 任务描述
句子顺序预测(SOP)
替换词检测(RTD)
词语混排(wop)
句子对相似度预测(psp)
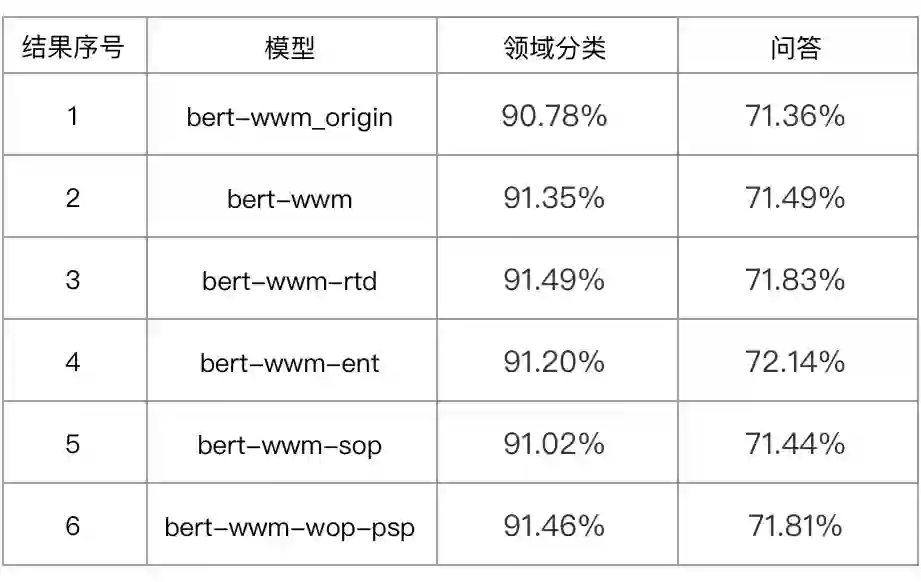
3.2.2 效果对比及分析

总结

参考文献
[1] Gururangan S, Marasović A, Swayamdipta S, et al. Don't Stop Pretraining: Adapt Language Models to Domains and Tasks[J]. arXiv preprint arXiv:2004.10964, 2020.
[2] Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
[3] Li X, Meng Y, Sun X, et al. Is word segmentation necessary for deep learning of Chinese representations?[J]. arXiv preprint arXiv:1905.05526, 2019.
[4] Cui Y, Che W, Liu T, et al. Pre-training with whole word masking for chinese bert[J]. arXiv preprint arXiv:1906.08101, 2019.
[5] Lan Z, Chen M, Goodman S, et al. A Lite BERT for Self-supervised Learning of Language Representations[J]. arXiv preprint arXiv:1909.11942, 2019.
[6] Clark K, Luong M T, Le Q V, et al. Electra: Pre-training text encoders as discriminators rather than generators[J]. arXiv preprint arXiv:2003.10555, 2020.
[7] Li X, Yan H, Qiu X, et al. Flat: Chinese ner using flat-lattice transformer[J]. arXiv preprint arXiv:2004.11795, 2020.
[8] Liu W, Zhou P, Zhao Z, et al. K-bert: Enabling language representation with knowledge graph[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2020, 34(03): 2901-2908.
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。







