OLAP引擎这么多,麻袋财富为什么选择用Kylin做自助分析?

为什么它会选择 Kylin 而不是其他解决方案呢?
更多干货内容请关注微信公众号“AI 前线”(ID:ai-front)
麻袋财富(原麻袋理财)成立于 2014 年 12 月底,是中信产业基金控股的网络借贷信息中介平台,经过 4 年平稳而快速的发展,截至目前,累计交易金额达 750 亿,已成为行业头部平台。庞大的业务量带来了数据量指数级增长,原有的数据分析处理方式已远远不能满足业务的需求:
流程耗时长:逻辑比较复杂的数据需求,可能会涉及到开发,产品经理,BI 等多方相关人员,通过反复的沟通,确认才能完成,而涉及人员过多增加了沟通成本,拉长项目周期
资源浪费:为了促进平台的销量增长,运营会设计各种产品促销或用户促活的短期活动, 每次活动后都会进行复盘,没有产品化的活动分析通常会导致分析人员的人力浪费
集群压力大:一些需要长期监测的复杂指标,每天都要进行重复的查询,而且每天都有几百个临时 SQL 提交到集群中处理,造成集群计算压力大,影响集群性能
查询慢:随着数据量越来越大,往往一条聚合 SQL 需要几分钟才能出结果,数据分析师需要的快速响应要求已远远不能满足
针对上述痛点,我们希望寻找一个工具能够给用户提供高效、稳定、便利的数据分析性能。
我们调研了市面上主流的 OLAP 引擎,对比详情如下所示:

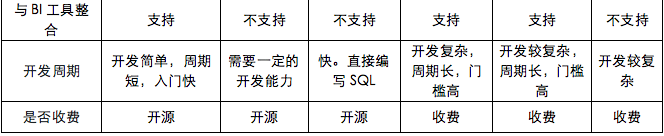
结合公司业务需求:
以 T+1 离线数据为主
可以整合 Tableau 使用,实现自助分析
常用 30 个左右的维度,100 个左右的指标,任意交叉组合,覆盖 80%+ 的固定和临时需求
业务方需要观察用户从进入到离开的整个生命周期的特征,涉及数据量大,但要快速响应
我们选择了 Kylin 作为 OLAP 分析引擎,原因如下:
Kylin 使用预计算,以空间换时间,能够实现用户查询请求秒级响应
可以结合现有 BI 工具——Tableau,实现自助分析
本来需要耗时一周的需求在几分钟内出结果,开发效率提升了 10 倍以上
本文主要介绍麻袋财富基于 CDH 大数据平台的自助分析项目实施,如何将 Apache Kylin 应用到实际场景中,目前的使用现状以及未来准备在 Kylin 上做的工作。
系统部署方面,主要分生产环境和预上线环境,生产环境主要负责查询分析,从生产集群 Hive 上跑计算,把预计算结果存储到 HBase。如果想新增一个 Cube 的话,需要分析人员先在预上线环境上操作,再由专人对 Cube 进行优化后迁移到生产环境。
麻袋财富的自助分析架构如下图所示:
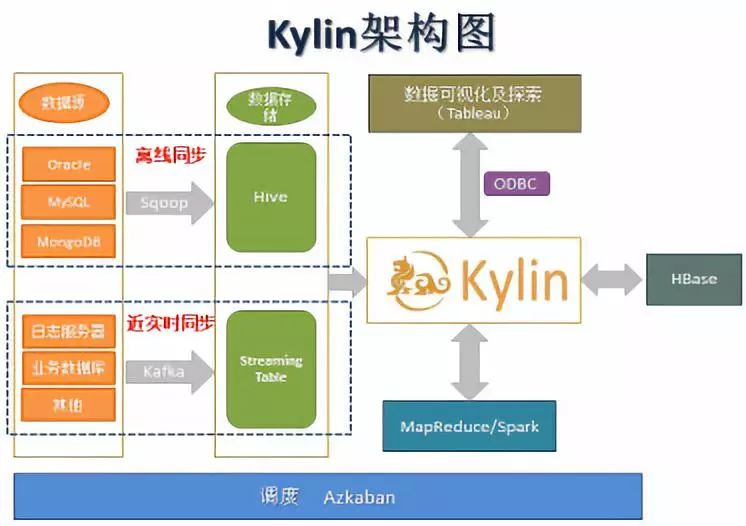
数据同步:Sqoop(离线场景)、Kafka(近实时场景)
数据源:Hive(离线场景)、Streaming Table(近实时场景)
计算引擎:MapReduce/Spark
预计算结果存储:HBase
自助分析工具:Tableau
调度系统:Azkaban
公司业务非常复杂,数据团队将各种业务需求高度抽象,确定好维度和度量,只需构建一个 Cube,基于该 Cube,形成通用的平台化数据产品,解放数据分析师,降低重复性工作。
数据建模对 Kylin 实施来说是最重要的工作。一般使用关系数据库模型中的星型模型,但是现实中由于业务的多样性,维表的基数很大,所以一般我们把表处理成宽表并且基于宽表建 OLAP 模型,宽表不仅能解决数据模型的数据粒度问题,还能解决多表 join 的性能问题,以及维度变化、或者超高基数维度等问题。
各个业务线不同的数据特点和业务特点决定了 Kylin 的使用场景及模型设计优化方式:
是数据规模和模型特点。从数据规模上来讲,宽表的数据量近百亿,每天的增量数据千万级以上。我们根据业务指标通过 OLAP 建模的高度抽象分析,定义了维度和度量值的关系以及底层数据粒度。
维度基数特点。维度基数最理想的情况是相对较小,但实际上有些维度超过了百万级接近千万级,这和业务需求及行业特点有关。除此之外指标上要用部分维度之间的笛卡尔积组合,造成很难简化 OLAP 模型,生成数据相应的开销也比较大。
维度粒度特点。从维度的角度来看,地域维度包含省份和城市;时间维度上需要一级划分年月日,增加了维度的复杂度。
指标也是维度特点。有一些指标既是维度也是度量,例如:我们需要分析在投金额为 0 的用户的行为,又需要计算用户的在投金额,所以在投金额即为维度又是度量。
从 Kylin Cube 模型上来说,由于 Cube 需要满足多种场景的需求,业务上需要多个维度互相灵活组合,与分析人员反复沟通,最终确认 Cube 的维度及度量。
Cube 模型概况:
19 个维度:包括省市、操作系统、设备型号、性别、绑卡状态、投资等级等
10 个度量:包括数据量、访问次数、登录用户数、浏览量、投资金额、年化金额等
增量构建:某一 Cube 源数据增量为 300 万,Build 完一天数据 Cube 大小为 87.79GB
Cube Build 过程中常见遇到的是性能问题,例如 SQL 查询过慢、Cube 构建时间过长甚至失败、 Cube 膨胀率过高等等。究其原因,大多数问题都是由于 Cube 设计不当造成的。因此,合理地进行 Cube 优化就显得尤为重要。
优化方案:
维度精简:去除查询中不会出现的维度,如数据创建日期
强制维度:把每次查询都需要的维度设为强制维度(Mandatory Dimensions)
层次维度: 把有层次的维度(省市或年月日)设为层次维度(Hierarchy Dimensions)
联合维度:把用户关心的维度组合设成联合维度(Joint Dimensions)
调整聚合组:设置多个聚合组,每个聚合组内设置多组联合维度。不会同时在查询中出现的维度分别包含在不同聚合组。
调整 Rowkeys 排序,对于基数高的维度,若在这个维度上有过滤、查询,则放在前面,常用的维度放在前面。
根据上面的优化方案, 把 assist_date 和 source 设为强制维度,把 province,city 设为层次维度,再根据使用频率和基数高低排序,最终的优化成果如下:
查询性能:秒级响应
构建时间:缩短 31%
Cube 大小:减小 42%
查询性能详情:业务明细表:10 亿
SQL 语句:求每个城市的在投金额

为了减低 OLAP 分析的延时,在 Kylin 中添加 Streaming Table 实现准实时分析的功能,Kylin 以 Streaming Table 为数据源,Streaming Table 消费 Kafka 中的数据。模型中多增加一个 timestamp 类型的字段,用作时间序列。在实践过程中,模型优化了如下参数:
kylin.Cube.algorithm=inmem
kylin.Cube.algorithm.inmem-concurrent-threads=8
kylin.Cube.max-building-segments=600
公司采用 Kylin 2.4.0 版本和 Tableau 9.0 版本, 在前者提供预计算结果的前提下, 希望结合 Tableau 能够给数据分析师提供更方便、快速的数据自助分析。
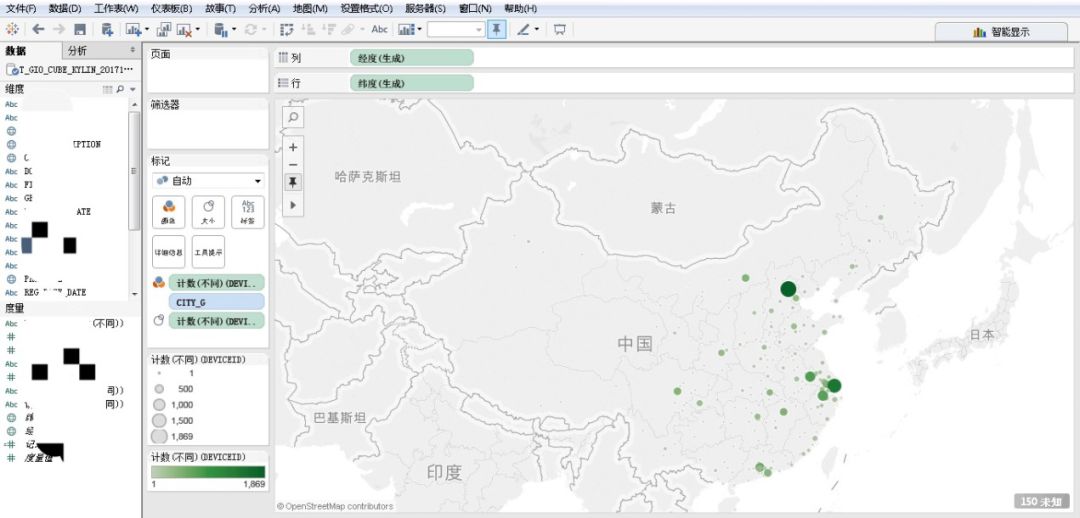
在本机上安装与 Tableau 版本对应的 Kylin ODBC Drive,Tableau 连接 Kylin 时选择 Kylin 的 ODBC Driver,然后选择 Kylin 的数据源 Fact Table 和 Join Table,并按 Kylin Cube 模型 join 起来,就可以实现拖拉出结果的即席查询,上钻、下钻、旋转等目标。分析人员摆脱了编写冗长 SQL,漫长等待的过程,可以根据自己的需求进行数据分析。其中一个使用场景如下图所示,展示每个地区的活跃人数:
1) Tableau 拖拉维度出结果慢
解决:查看 kylin.log,发现耗时最长的都是 select * from fact,所以让这条 SQL 尽可能快的失败,可以修改 kylin.properties 的参数:
kylin.query.max-scan-bytes 设置为更小的值
kylin.storage.partitin.max-scan-bytes 设置成更小的值
2) Kylin 整合 Tableau 创建的计算字段一定是 Cube 中包含的,若 Cube 中没有包含该计算字段,那么在 Tableau 中计算会显示通信错误,因为 Cube 的预计算中不含此值。
3) 使用实时增量时报错:
解决:这是由于 Kylin 2.4.0 版本和 Kafka 的 3.0.0 版本不匹配,把 Kylin 降了一个版本 Kylin 2.3.2 即可。
4) 字段类型转换:在 double 类型的数据转换为 String 时,会自动转换为保留一位小数的字符串,例如 112 转换成了 112.0,导致 join 的时候无法 join 成功。
解决:当我们要转换的数值只有整形没有小数时,我们可以先把数值类型转换成 bigint 类型,使用 bigint 类型存储的数值不会采用科学计数法表示。
5) 空值产生的数据倾斜:行为表中对游客的 user_id 是置空的,如果取其中的 user_id 和 用户表中的 user_id 关联,会碰到数据倾斜的问题。
解决:把空值的 user_id 变成一个字符串加上随机数,把倾斜的数据分到不同的 reduce 上,由于 null 值关联不上,处理后并不影响最终结果。
6) Kylin ODBC Driver 安装是根据 Tableau 版本的,不是根据操作系统而定的。例如,windows 版本是 64 位的,Tableau 版本是 32 位,就需要装 32 位的 ODBC。
Kylin 给我们带来了很多便利,节约了查询时间和精力。随着技术的不断进步,还有许多问题需要解决,还需要不断探索和优化,例如 Kylin 对明细数据的查询支持不理想,但是有时需要查询明细数据;删除 Cube,HBase 中的表不会自动删除,影响查询性能,需要手动清理等。
作者介绍:
大数据平台部门:麻袋财富大数据平台部门负责公司企业级数据仓库的搭建、实时监控系统、智能化应用平台等工作,团队以大数据核心平台为基础,展开大数据管理与应用开发,落地人工智能运用场景。
小福利!10月26日,Apache Kylin Meetup@杭州将正式拉开帷幕,届时将会有来自eBay、丁香园、店+ 、Kyligence 等企业的大数据专家,为大家讲解Apache Kylin的优秀应用案例,以及 Kylin v2.5的最新特性。对Kylin感兴趣、想要了解更多实践案例的同学可以点击 阅读原文 报名参加活动!

如果你喜欢这篇文章,或希望看到更多类似优质报道,记得给我留言和点赞哦!




