作为一类领先的生成模型,扩散模型(Diffusion Models, DMs) 在强化学习(Reinforcement Learning, RL) 中展现出诸多关键优势,包括多模态表达能力、训练稳定性以及基于轨迹的规划能力。本文对基于扩散模型的强化学习研究进行了全面而前沿的综述。我们首先回顾强化学习的基本原理,并指出其面临的核心挑战,随后介绍扩散模型的基本概念,探讨其如何被融入强化学习框架以应对这些关键问题。 在此基础上,我们提出了一个双轴分类体系(dual-axis taxonomy),沿两条正交维度对该领域进行系统梳理: 1. 功能导向分类(function-oriented taxonomy) —— 阐明扩散模型在强化学习流程中的不同功能角色; 1. 技术导向分类(technique-oriented taxonomy) —— 按照在线(online)与离线(offline)学习范式对相关实现进行定位。
此外,我们还系统性地考察了基于扩散模型的强化学习从单智能体(single-agent) 向多智能体(multi-agent) 领域的演进过程,构建了多种 DM-RL 融合框架 并展示其实际应用价值。进一步地,本文总结了扩散模型强化学习在多个领域中的成功应用案例,讨论了现有方法面临的开放性问题,并指出了推动该领域未来研究的关键方向。最后,我们对全文进行了总结,展望了扩散模型强化学习的未来发展前景。 我们还维护了一个开源的 GitHub 资源库(https://github.com/ChangfuXu/D4RL-FTD),持续收录相关论文与资源,以促进扩散模型在强化学习中的研究与应用。
1 引言(Introduction)
1.1 背景(Background)
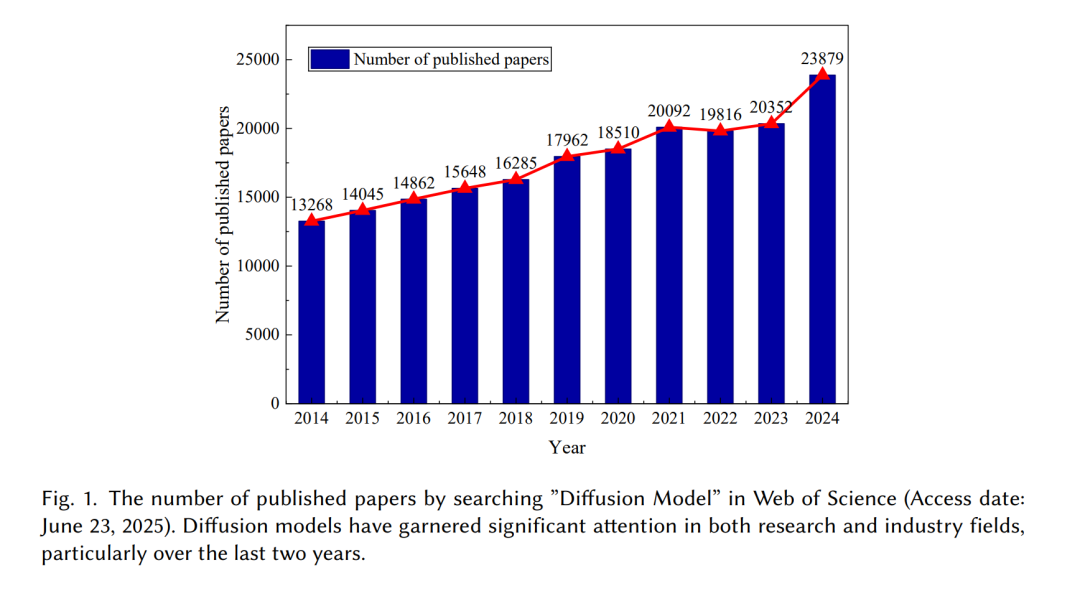
扩散模型(Diffusion Models, DMs) 近年来已成为最具影响力的生成模型之一,引起了机器学习领域的广泛关注 [1, 2]。最初,DMs 被用于高质量数据生成任务,如图像与视频合成 [3]。DM 是一种生成式去噪过程,通过学习逆向还原逐步被噪声污染的数据分布,从而实现对逼真数据样本的生成。与早期的生成方法(如变分自编码器(VAE) [4] 和 生成对抗网络(GAN) [5])相比,DMs 在生成高保真样本和训练稳定性方面具有显著优势。因此,DMs 的通用性与强大能力已在多个领域得到验证,如图 1 所示,涵盖计算机视觉(CV) [3, 6]、自然语言处理(NLP) [7, 8]、音频生成 [9, 10],尤其是在序列决策(sequential decision-making)领域 [11–15]。 强化学习(Reinforcement Learning, RL) 已被广泛应用于机器人控制 [16]、自动驾驶 [17] 和任务调度 [18] 等多个领域。RL 的基本目标是学习一个将观测或状态映射到动作的策略(policy),以最大化长期累积奖励。结合深度神经网络(DNNs),RL 进一步发展为深度强化学习(Deep Reinforcement Learning, DRL)。DRL 的强大之处在于其能够直接从高维感知输入(如图像或原始传感数据)中学习,而无需手工设计特征。这种端到端学习范式使 DRL 智能体能够自动发现复杂模式与最优控制策略,这些策略往往难以通过人工定义获得。
DRL 主要包含两大类方法: 1. 基于价值(value-based)的方法:包括深度 Q 网络(DQN)[19]、双重 DQN [20] 和对偶 DQN [21]; 1. 基于策略(policy-based)的方法:基于 Actor-Critic 框架,可分为随机策略梯度方法,如信赖域策略优化(TRPO)[22]、近端策略优化(PPO)[23],以及确定性策略梯度方法 [24],如深度确定性策略梯度(DDPG)[25]、双延迟深度确定性策略(TD3)[26] 和软 Actor-Critic(SAC)[27]。
DRL 显著拓展了序列决策的应用范围,使其能够应对复杂和大规模问题。 然而,尽管取得了显著进展,DRL 仍存在若干关键局限: 1. 样本效率低:DRL 通常需要大量与环境的交互来学习有效策略; 1. 分布表达受限:许多 DRL 算法依赖单峰分布(如高斯分布)的随机采样,难以捕捉复杂或多模态动作空间 [28]; 1. 训练不稳定性:自举误差、离策略学习困难以及对超参数的高度敏感性会阻碍 DRL 模型的收敛 [29]; 1. 策略建模过于简单:传统 RL 通常将策略视为直接的状态到动作映射,这种形式可能过于简化决策过程,限制了策略的表示能力。
1.2 研究动机(Motivation)
针对上述局限,近期研究开始将扩散模型引入强化学习框架,以优化 RL 技术。DMs 在离线轨迹建模、**规划(planning)与目标条件控制(goal-conditioned control)等任务中表现出强劲性能,尤其在 DRL 中(如图 2 所示)。代表性工作 Diffuser [13] 通过 DM 从离线数据集中学习轨迹分布,并通过引导采样(guided sampling)**实现目标导向的规划。在此基础上,大量后续研究将 DMs 融入 RL 流程的不同环节 [30, 31],例如: * 用 DM 替代传统的高斯策略分布 [32]; * 利用 DM 增强经验数据 [33]; * 通过 DM 提取潜在技能表示 [34]。
这些方法在多任务强化学习 [35]、模仿学习(Imitation Learning, IL)[36]、轨迹生成 [37] 等多种场景中均表现出优异性能。值得注意的是,DMs 强大的分布建模能力为 RL 的长期难题提供了新的解决思路,如高效探索、策略表达力提升以及不确定性下的规划。 因此,当 DMs 应用于 RL 时,可以将**状态—动作轨迹(state-action trajectory)**整体视为从学习到的分布中采样得到的样本,而非逐步预测动作,从而带来以下显著优势: * 改进的探索能力(Improved Exploration):DMs 能自然地表示复杂的多模态动作或轨迹分布,从而生成更多样化的行为模式,提升探索效率 [13]。 * 基于轨迹的推理(Trajectory-level Reasoning):DM 策略可基于任务目标生成完整的动作序列,而非逐步选择动作,从而实现更优的长期规划 [11]。 * 稳定性与泛化性(Stability and Generalization):基于去噪扩散过程的训练方式可获得更平滑的优化空间,提升泛化能力,尤其适用于离线 RL 场景 [29]。 * 与 RL 的兼容性(Compatibility with RL):DMs 可基于固定数据集学习有效策略,从而缓解传统 RL 中的分布偏移与外推误差问题 [38]。
在此背景下,一系列新的基于扩散的决策模型相继涌现,如 Diffuser [13]、Decision Diffuser [11] 与 Deep Diffusion-based SAC (D2SAC) [14] 等。这些模型结合了生成建模与决策优化的优势,为实现鲁棒、高效且具有表达力的策略学习开辟了新的方向。
1.3 主要贡献(Contribution)
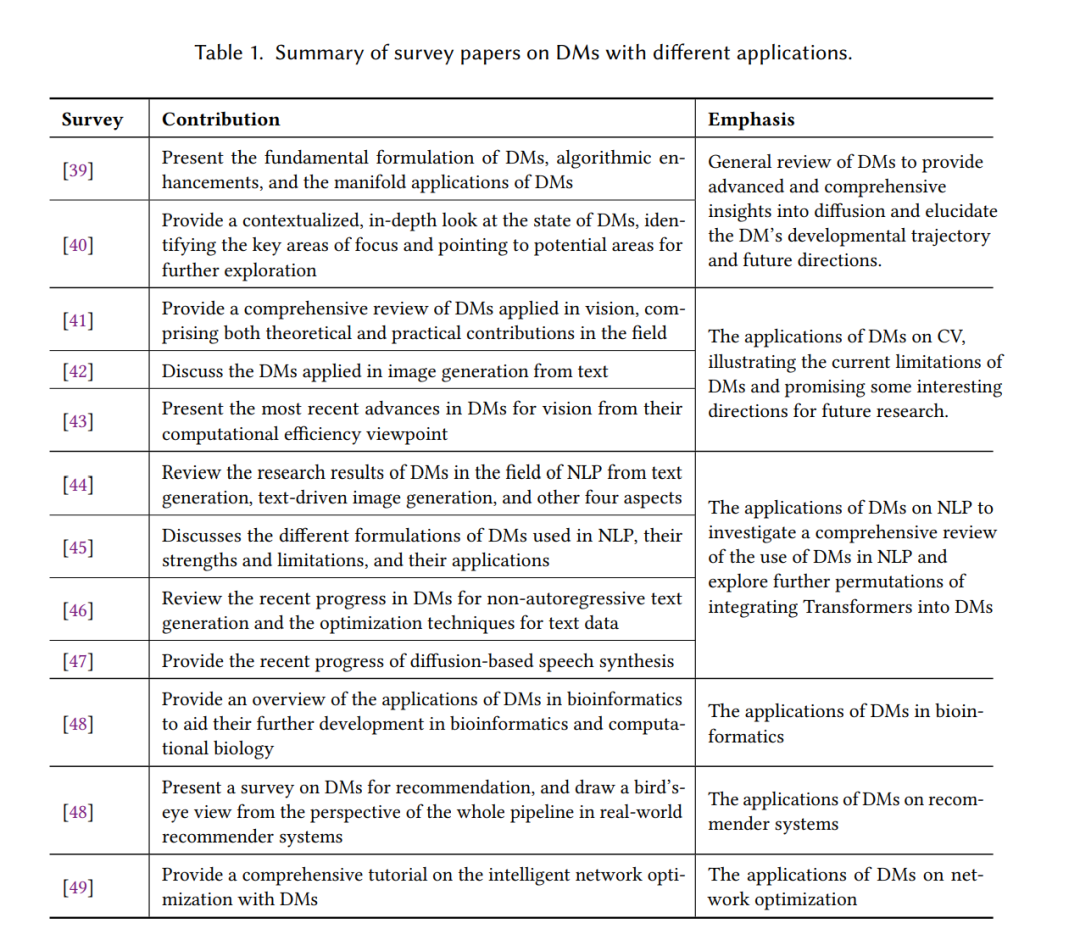
尽管已有若干综述研究总结了 DMs(如表 1 所示),但多数工作仅提供了广义概述(如 [39], Yang et al. [40]),或聚焦于特定领域(如 CV [41, 42] 或 NLP [44, 45]),尚缺乏针对决策优化(decision-making optimization)的系统性综述。本文旨在弥补这一空白,通过系统回顾近期进展、梳理关键方法,并指出现存挑战与未来研究方向。我们的目标是为研究者与实践者提供一个清晰、结构化且前沿的领域全景。 此外,虽然 [28] 也探讨了基于扩散的 RL 方法,但在研究范围、方法论与目标上与本文显著不同。具体而言,相较于 [28],本综述的创新与贡献包括: 1. 全面综述:涵盖基于扩散的 RL 的背景、挑战、集成策略与多领域研究趋势(如机器人、自动驾驶、边缘计算等); 1. 系统分类体系:提出系统化的分类结构,总结代表性方法与应用; 1. 结构与采样分析:深入探讨 DMs 在 RL 中的架构与采样机制,分析其在单智能体与多智能体、在线与离线 RL 场景下的作用; 1. 前沿进展与应用总结:汇总近期在各领域的进展与推广; 1. 开放问题与未来展望:揭示尚未充分研究的关键方向与新兴议题。
本文的主要贡献如下: * (1)提供了扩散模型结合强化学习的系统性教程:全面阐述 DMs 的起源、发展与核心优势,并梳理其在各历史阶段中对 RL 技术的作用。 * (2)提出六类功能性划分:将 DMs 在 RL 中的角色分为六类——基于扩散的轨迹优化、策略学习、模仿学习、探索增强、环境仿真与奖励建模,并给出了相应问题定义与统一解法框架。 * (3)多维视角分析:从**功能分类(function taxonomy)与技术分类(technique taxonomy)**两方面深入分析单智能体与多智能体、在线与离线场景下的 DM-RL 研究,验证其实用性与有效性。 * (4)应用综述与趋势展望:总结 DM-RL 在机器人、自动驾驶、边缘计算等领域的应用成果,并讨论未来研究方向,为 DMs 在 RL 技术演进中的潜在影响提供启示。
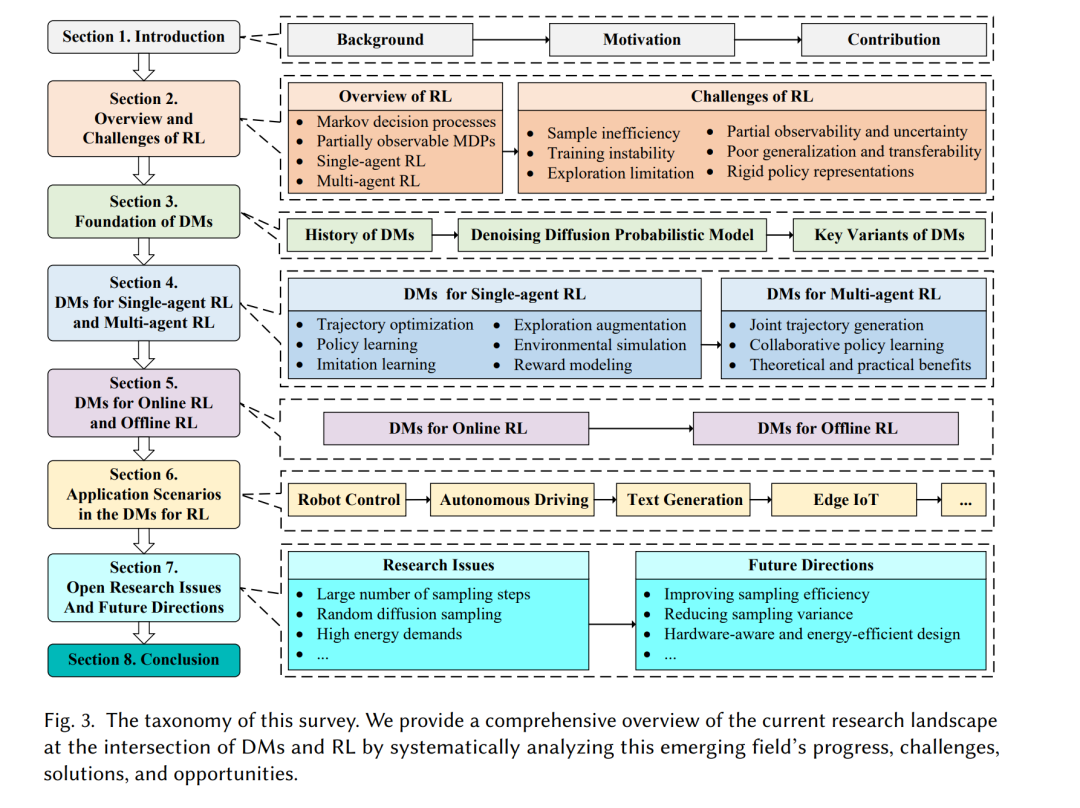
如图 3 所示,本文余下内容结构如下: 第 2 节回顾 RL 概述与挑战;第 3 节介绍 DMs 的基本概念与主要变体;第 4 节讨论单智能体与多智能体场景下的 DMs(功能分类视角);第 5 节分析在线与离线 RL 中的 DMs(技术分类视角);第 6 节总结最新进展与应用;第 7 节探讨开放问题与未来方向;第 8 节为全文总结与结论。