Yoshua Bengio团队最新强化学习研究:智能体通过与环境交互,「分离」变化的独立可控因素

原文来源:arXiv
作者:Valentin Thomas、Emmanuel Bengio∗、William Fedus、Jules Pondard、Philippe Beaudoin、Hugo Larochelle、Joelle Pineau、Doina Precup、Yoshua Bengio
「雷克世界」编译:嗯~阿童木呀
人们普遍认为,一个良好的表征(representation)在于能够对变化的潜在可解释性因素进行分离。然而,对于什么样的训练框架可以实现这一目标,仍然是一个悬而未决的问题。
尽管以往的大多数研究重点主要集中于静态设置(例如,使用图像),但我们假设,如果允许学习者与其环境进行交互的话,就可以从中发现一些因果因素。
智能体可以尝试不同的操作并观察其所产生的效果。更具体地说,我们假设这些因素中的一些与环境的某些可独立控制的方面相对应,即对于环境中的每一个这样的方面来说,都存在一个策略和可学习的特征,从而使得该策略可以在该特征中产生相应的变化,同时对其他特征进行最小程度的更改,从而对所观察到数据中的统计变化进行解释。
我们提出了一个特定的目标函数以找到这些因素,并通过实验验证,它确实可以在没有任何外部奖励信号的情况下,对环境的独立可控制方面进行分离。
在解决强化学习问题时,想要将好的结果从随机策略中区分开来往往需要具有正确的特征表征即使使用函数近似(function approximation),相较于盲目地去尝试解决给定的问题,学习正确的特征将可能会带来更快的收敛性(Jaderberg 等人于2016年提出)。
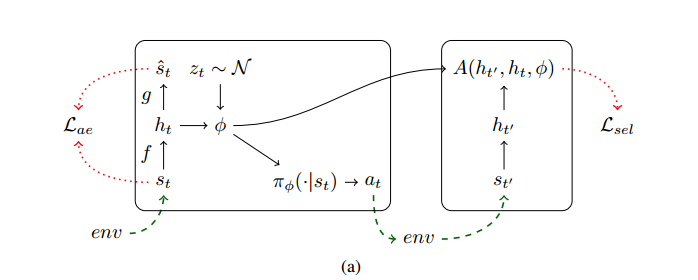
我们架构的计算模型。其中,st是第一个状态,由其编码ht和噪声分布z产生。φ是生成的,φ用于对在环境中运行的策略πφ进行计算。序列ht、ht’通过选择性损失和ht上的可选择性自编码器损失,用于对我们的模型进行更新。
在监督学习研究(Bengio于2009年、Goodfellow等人于2016年提出)和强化学习研究(Dayan于1993年、Precup于2000年提出)领域中存在着这样一种观点,学习一个好的,而非新的表征对于解决大多数现实世界中的问题来说具有至关重要的作用。
而另一种观点是,这些表征通常不需要被显式地进行学习,这种学习可以通过内部奖励机制来进行引导,而这种奖励机制通常称为“内在动机(intrinsic motivation)”(Barto等人、Oudeyer和Kaplan于2009年、Salge等人于2013年、Gregor等人于2017年提出)。
在以前研究成果的基础上(Thomas等人于2017年提出),我们构建了一个表征学习机制,它与内在动机机制和因果关系密切相关。该机制显式地将智能体对其环境的控制与智能体所学习到的环境表征联系起来。更具体地说,这种机制的假设是,环境中变化的潜在因素大部分可以由另一个变化的智能体独立控制。
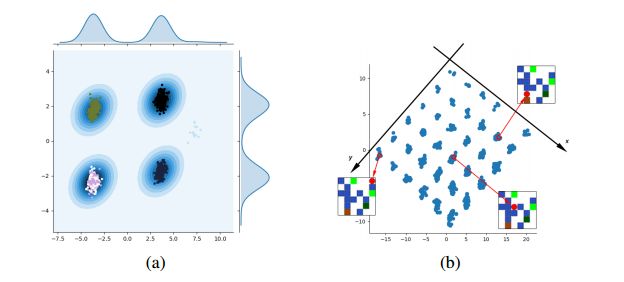
(a)对随机可控因素φ进行采样时,对1000次变化h’—h及其核密度估计的采样。我们观察到我们的算法在4种主要模式下对这些表征进行分离,每种模式都对应于智能体所实际采取的行动
(b)潜在空间中的分离结构。x轴和y轴是分离的,这样我们就可以通过查看其潜在的编码h = f(s)来恢复任何观测值中智能体的x和y位置。当智能体位于橙色块上时,这个网格上的缺失点其所不能到达的唯一位置。
我们为这个机制提出了一个通用且容易计算的目标,可以用于任何一个使用函数近似学习潜在空间的强化学习算法中。
我们的研究结果表明,我们的机制可以推动模型学习以一种有意义的方式对输入进行分离,并学习对要采取多种行动才能得以的改变的因素进行表征,此外,研究结果还表明,这些表征可以在已学习的潜在空间中执行基于模型的预测,而不是在低级输入空间(例如像素)中。
学习分离表征
Hinton和Salakhutdinov于2006年提出的,用于学习表征的规范的深度学习框架就是一个典型的自编码框架。然而,这并不一定意味着已学习的潜在空间会对变化的不同因素进行分离。出于这些问题的考虑,我们提出了本文中所阐述的方法。
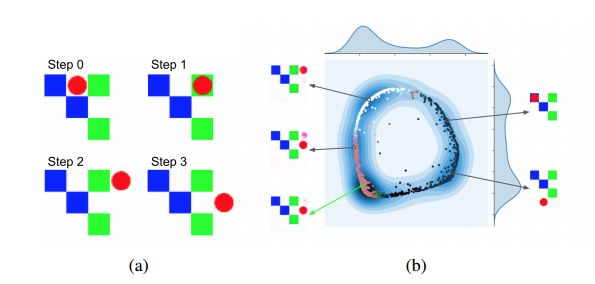
(a)智能体所实际完成的3步轨迹;
(b)空间φ(h0, z), z ∼ N (0, 1)的PCA视图。每个箭头指向由不同的φ所形成的预测Tθ(h0,φ)的重构。
(a)中的策略使用的是绿色箭头开始处的φ。需要注意的是它的预测是如何对实际的最终状态进行准确预测的。
其他作者提出了一些用于分离变化的潜在因素的机制。诸如变分自编码器(Kingma和Welling于2014年提出)、生成对抗网络(Goodfellow等人于2014年提出)或非线性版本的ICA(Dinh等人于2014年、Hyvarinen和Morioka于2016年提出)等之类的许多深度生成式模型,试图通过假设它们的联合分布(对所观察到的s进行边缘化处理)是因式分解后的结果(即它们是边缘独立的),对变化的潜在因素进行分离。
在本文中,我们沿着另一个方向进行探讨,试图利用学习智能体在环境中行动的能力,以便对表征施加进一步的约束。我们假设,交互是学习如何对智能体所面临的观察流的各种因果因素进行分离的关键所在,并且这种学习可以在一种无监督的方式下完成。
可以这样说,到目前为止,将表征延展到模型的独立可控特征中取得了一些令人鼓舞的成功。 我们的特征的可视化清楚地展示了简单环境中的不同可控方面,但是,我们的学习算法也存在一定的缺陷,即它是不稳定的。甚至可以这样说,我们方法的优势似乎也可能是它的弱点所在,因为先前的独立迫使已学习表征中的关注点进行非常严格地分离,而这些应该是可以缓和的。
与此同时,一些不稳定性的来源似乎也减缓了我们的进程:学习一个有关可控方面的条件分布,往往会产生少于预期的模式。学习随机策略,通常会非常乐观地收敛域一个单一的动作中,由于模型具有多个部分因此往往需要对许多超参数进行调整。尽管如此,对于我们目前所采取的方法和措施,我们仍然报以希望。分离会发生,但对我们的优化过程以及我们目前的目标函数进行详细的了解将是推动进一步发展的关键点所在。
未来智能实验室是人工智能学家与科学院相关机构联合成立的人工智能,互联网和脑科学交叉研究机构。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”





