开源引擎GTS乾坤鼎:自动生产模型拿下FewCLUE榜单冠军
机器之心发布
在自然语言处理(NLP)领域,基于 Transformer 结构的预训练语言模型展示出了强大的语言理解能力,在各类 NLP 任务上都取得了巨大突破。
然而,在众多真实的业务场景中,有标注的数据是往往是严重稀缺的,而相关数据的获取和标注需要大量的人力和专家知识的投入。因此,小样本学习的研究已经成为业界的热点之一。
针对这一问题,IDEA 研究院认知计算与自然语言研究中心(下面简称 IDEA CCNL)研发了模型生产工具 GTS 乾坤鼎引擎以及 GTSfactory 模型自动生产平台,其基于封神榜开源模型体系,提出了首创的 GTS(Generator-Teacher-Student)训练体系,通过「用 AI 生产 AI」的方式,以自动化生产的模型在中文语言理解权威评测基准 FewCLUE 榜单上分别取得了第一名及第三名的好成绩。
FewCLUE 是中文语言理解权威评测 CLUE 的子榜,旨在探索小样本学习的最佳实践,先后吸引了包括百度、腾讯微信、美团、网易、奇点智源和浪潮人工智能研究院等工业界和学术界顶尖机构的参与。GTS 系列产品的这一次登顶,也预示着其模型自动化生产技术已经达到了顶尖的算法专家水平。
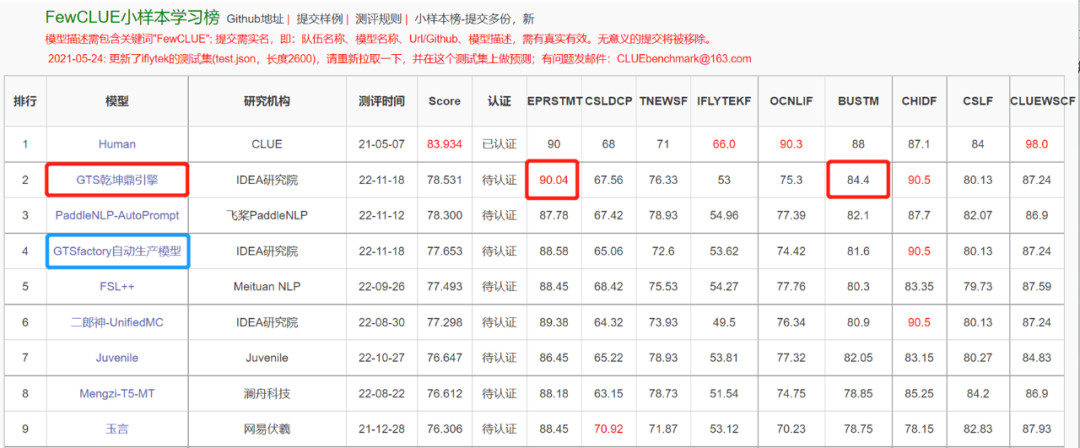
其中,GTS 乾坤鼎在 EPRSTMT(电商评论情感二分类)任务中超过了其他算法专家生产的模型,同时也刷新了 BUSTM(句子对相似度判断)任务的记录;而 GTSfactory 自动生产出的 1.1 亿参数的小模型在总分和单项任务中均接近算法专家的最好水平,这也是 FewCLUE 榜单中 TOP10 里模型参数最小的模型。
IDEA CCNL 目前已经开源 GTS 乾坤鼎(https://github.com/IDEA-CCNL/GTS-Engine),也将逐步开源 GTSfactory,让更多的人可以参与到 GTS 训练体系中来,将 IDEA-CCNL 坚持的「用 AI 生产 AI」的理念传播开来。
GTS 乾坤鼎登顶 fewCLUE,GTSfactory 达到算法专家水平
GTS 系列产品专注于研究在不同模型参数规模下的小样本 NLU 任务模型自动生产,其中,GTS 乾坤鼎引擎利用 13 亿参数规模的 Erlangshen-BERT 进行训练,而 GTSfactory 模型自动生产平台则搭建了 Generator(参数量几十亿及以上的生成模型)、Teacher(参数量 10 亿以上的大模型)及 Student(参数量 1 亿小模型)协同训练的体系,最终生产出可以落地部署的轻量级小模型。
在「GTS」训练体系的加持下,GTS 乾坤鼎通过自动化训练的方式,在没有模型集成的情况下,凭借单一模型登顶 FewCLUE,真的有点「鼎」。其中,EPRSTMT(电商评论情感二分类) 任务中取得了 90.04 分,超过曾经的第一 90.0 分,并刷新了该项任务的最高记录;BUSTM(句子相似度判断)任务中取得了 84.4 分,大幅度刷新了该项任务的最好成绩,其他几项任务也与 SOTA 接近,可以想象一下,如果在离线数据处理场景中使用 GTS 乾坤鼎自动化训练出的模型,那对于数据处理效率上的提升该有多么「鼎」。
GTS 乾坤鼎引擎致力于提供开箱即用的自然语言任务的处理能力,让你仅仅调用不到十行代码,即可低成本地训练出效果强大的模型。据介绍,GTS-Engine 未来将逐步开源全部的训练能力。
Github:https://github.com/IDEA-CCNL/GTS-Engine

如果说 GTS 乾坤鼎生产的 13 亿参数的大模型代表了小样本下的性能巅峰,那么 GTSfactory 生产的 1.1 亿参数的小模型则可能在开创小样本下的应用巅峰。在没有模型集成的情况下,GTSfactory 产出的单一小模型以 1.1 亿参数量取得了 FewCLUE 榜单第三名的成绩,超越一众参数量 10 亿、几十亿的重量级大模型,这说明在 Few-shot 场景下,GTS 训练体系产出的小模型可以兼具高性能及快速推理的能力。
传统的 AI 模型开发模式,一般是「一人负责一个模型」,一个算法工程师负责数据标注、算法尝试和调优、模型评估整个链路的工作,不但耗时耗力,生产的 AI 模型的效果还因算法工程师的水平而异。GTSfactory 平台的出现打破了这一桎梏,设想一下,当你需要进行实时意图识别时,你只需要提供几十条标注数据 + 几小时的训练等待时间,便可以在平台上获取一个性能相当优异的小参数量 AI 模型,业务的生产力将得到极大的释放。正如汽车工业中流水线的进步一样,GTS 打造了 AI 行业的模型自动化生产线,AI 生产工业化时代即将到来。
GTSfactory(gtsfactory.com)当前处于「免费公测」阶段,还有什么问题是免费 GPU 算力解决不了的呢?GTSfactory 背后的 GTS 八卦炉引擎,也将逐步开源所有的训练能力,这样本地也可以一键启动「炼丹」啦~

如何理解 GTS 训练体系?GTS 又如何实现「用 AI 生产 AI」?
首创的「GTS 训练体系」以模型间能力的传递为核心,依托于大模型的强大 NLU 能力,相较于传统基于 NAS 的自动化训练模式,可以极大地减少算力的消耗同时保持模型的性能。
具体的,GTS 训练体系在训练过程中会用到几十亿参数的生成模型 Generator,13 亿参数量及以上的 NLU 大模型 Teacher,最终将 Generator 及 Teacher 的大模型能力转化到 1 亿参数的小模型 Student 中。
在大模型能力的转化过程中,GTS 训练体系融合了「Collaborative Learning」、「Meta Learning」、「Self-Training」、「Prompt」等多种学习范式,开发者将 GTS 训练体系管道化、模块化,实现「N 个算法工程师」共建一个训练体系的算法开发模式,真正的构筑成了一种物理意义上的训练系统。因此,GTS 训练体系,从系统的角度去解读 G、T、S,又可以变为「General Training as a System」。
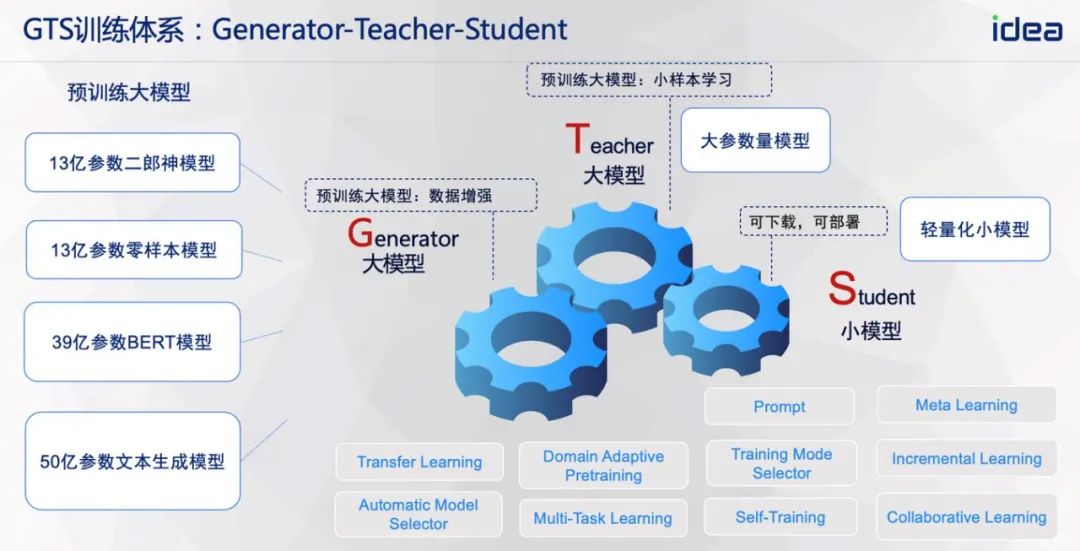
GTS 训练体系下,Generator 扮演了「存储 + 计算」一体的知识库这样的角色,源源不断地输出下游任务需要的数据,而 Teacher 则是扮演「数据校验」的角色,辅助 Generator 对生成数据进行校验;最终,Student 进一步整合来自 Generator 和 Teacher 的大模型能力。在整个能力传递的过程中,本质上是一个 AI 模型将能力传递到另一个 AI 模型,因此也类似于 AI 模型间的「教学」,这也即是 GTS 训练体系「用 AI 生产 AI」理念的由来。
GTS 乾坤鼎引擎技术揭秘
在 13 亿参数规模的大模型上进行训练,关键在于如何提升模型在小样本数据下的泛化能力。GTS-Engine 主要使用了以下几种关键的技术:
1.有监督预训练
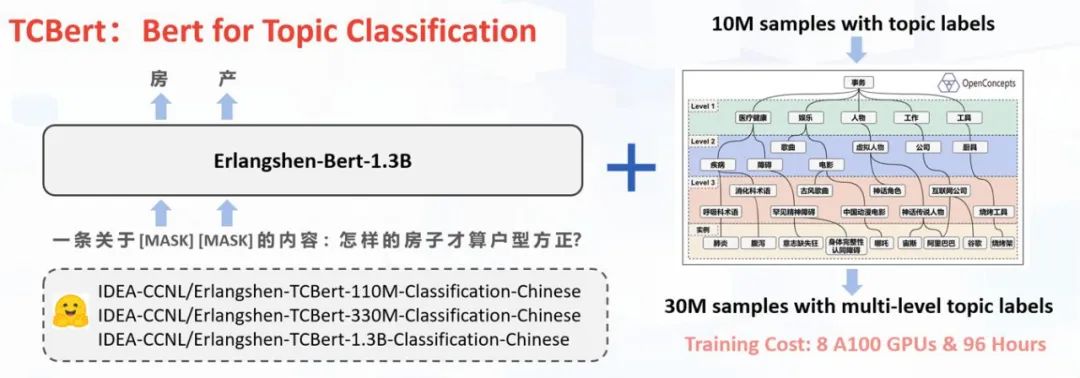
它收集了百万级别带有标签的文本数据,并通过开源的中文概念图谱进行多标签层级的扩充,构造了一个涵盖所有主题的有监督分类数据集,利用这一规模庞大的数据集进行了有监督预训练,主要用于解决主题分类的任务。IDEA 研究院已经在 huggingface 上开源了模型。
2.新的学习范式
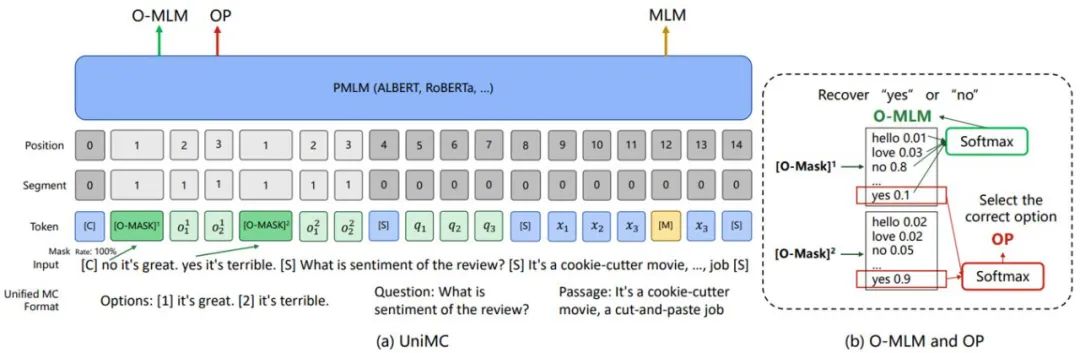
GTS-Engine 使用 UniMC(https://arxiv.org/abs/2210.08590)作为学习范式。UniMC 同样也是 IDEA-CNNL 提出的统一 NLU 学习范式,发表在了 EMNLP2022 会议上。它不仅在零样本 NLU 任务上表现优异,在小样本任务上同样效果卓越,在自然语言蕴含和句子对相似任务上,它使用这一范式进行微调。
3.检索增强
GTS-Engine 利用训练数据集构造了一个索引,通过编码器获得的句子向量作为索引的 key,标签作为索引的 value。通过 kNN 的方式对索引进行检索,把 kNN 预测的概率和分类器预测的概率进行插值作为最后的分类概率输出。同时,它也可以利用 TCBert 对句子编码器和分类器进行同时训练,进一步提高性能。
4.数据增强
GTS-Engine 使用 Masking、Dropout、Mixup 等方式进行数据增强,其中 Mixup 通过对输入数据进行简单的线性变换,构造新的组合样本和组合标签,可以增强模型的泛化能力。同时,它也引入了 R-Drop 对同一个句子做两次 Dropout,并且强制由 Dropout 生成的不同子模型的输出概率保持一致,使得模型更具有泛化性。
5.对比学习
GTS-Engine 使用 batch 内样本构造正负例,加入对比损失来训练模型。更进一步地,它也引入了 kNN 对同一个 batch 内的样本进行正负例的扩充,让对比学习能看到更多更丰富的语义,这也进一步提升了效果。
6. 系统化
最后,作者将上述提到的技术,通过训练流水线的方式有机地结合在一起,并加入 Self Training 驱动各个技术间的训练和融合,最终产出一个 13 亿级别参数的大模型。
IDEA 研究院已将部分训练细节进行了开源,GTS 乾坤鼎引擎后续将会逐步更新,将全部的模型生产能力全部开源,让你仅编写不到十行 Python 即可生产最好的 NLU 模型。
GTSfactory 技术揭秘
GTSfactory 的目标是生产出轻量化、可自由部署、高性能的小模型,从算法角度,可以分成离线算法和在线算法。
1.模型离线预训练技术:
A.基于 Meta Learning 的线下大规模有监督数据预训练
B.基于全词 MLM 的线下特定领域数据的无监督预训练 Domain Adaptive Pretraining
2.模型在线训练技术:
A.基于文本检索系统的任务相关预训练 Task Adaptive Pretraining
B.基于 3D 信息对齐的多模型协同训练
C.深度改造的 Prompt Learning
D.Self-Training / 伪标签等半监督技术的运用
E.RDrop、KNN、多任务学习、自适应模型验证等众多 Trick 的整合
小结
GTS 训练体系瞄准当前 AI 产业界的两大痛点:1)数据少、2)人力贵,类似于福特 1913 年发明的汽车生产流水线,IDEA CCNL 希望 GTS 训练体系成为「用 AI 生产 AI」的模型生产线,后续 GTS 训练体系还会纳入更多的 NLP 及多模态任务,如信息抽取、摘要、AIGC 等,为 AI 产业化贡献力量。GTS 系列产品面向更广泛的使用者,能够更快地接入业务轨道,节省硬件、软件、人力等成本,在激烈的市场竞争中,为千百万个尚在萌芽阶段的 ideas 抢救出更多的成长时间。
「让机器拥有与人一样的认知能力」,是一个非常高远的目标,等到它实现并掀起下一次人工智能浪潮,也许时间已经过去了许久。但正是每一次小小的进步,每一次手舞足蹈着宣布的「idea」,坚定地牵引着那一天的到来。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

