基于双目视觉的自动驾驶技术
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:黄浴
https://zhuanlan.zhihu.com/p/56236308
本文已授权,未经允许,不得二次转载
单目视觉是Mobileye(ME)的看家法宝,其实当年它也考虑过双目,最终选择放弃(:。
单目的测距和3-D估计靠什么?是检测目标的Bounding Box(BB),如果无法检测的障碍物,该系统就无法估计其距离和3-D姿态/朝向。没有深度学习的时候,ME主要是基于BB,摄像头标定得到的姿态和高度以及路面平直的假设估算距离。
有了深度学习,可以根据3-D的ground truth来训练NN模型,得到3D大小和姿态估计,距离是基于平行线原理(single view metrology)得到的。不久前百度Apollo公布的单目L3解决方案讲的比较清楚了,参考论文是“3D Bounding Box Estimation by Deep Learning and Geometry".
双目当然可以算视差和深度了,即使没有检测出障碍物(因为有附加的深度信息,检测器会比单目好),也会报警。问题是,双目视觉系统估计视差没那么容易,立体匹配是计算机视觉典型的难题,基线宽得到远目标测距准,而基线短得到近目标测距结果好,这里是存在折衷的。
目前市场上ADAS存在的双目视觉系统就是Subaru EyeSight,据说性能还行。

百度推出的阿波龙L4摆渡车量产100台,就安装了双目系统。还有欧盟自主泊车项目V-Charge也采用了前向双目视觉系统,另外自动驾驶研发系统Berta Benz也是,而且和雷达系统后融合,其中双目匹配的障碍物检测算法Stixel很出名。以前Bosch和Conti这些Tier-1公司也研制过双目视觉解决方案,但没有在市场上产生影响力,据说被砍掉了。
谈到双目系统的难点,除了立体匹配,还有标定。标定后的系统会出现“漂移”的,所以在线标定是必须具有的。单目也是一样,因为轮胎变形和车体颠簸都会影响摄像头外参数变化,必须在线做标定修正一些参数,比如仰角(pitch angle)和偏角(yaw angle)。
双目在线标定就更复杂些,因为双目匹配尽量简化成1-D搜索,所以需要通过stereo rectification将两个镜头光轴方向平行并和基线垂直。所以针对获得的gain相比,增加的复杂度和成本,如果不划算商家就会放弃。
最近重提双目视觉,是因为硅谷芯片公司安霸(Ambarella)在2014年收购意大利帕尔马大学的Vis Lab,研制了双目的ADAS和自动驾驶芯片,去年CES之后就开始进军车企和Tier-1。而且,安霸目前正在继续研究提升该系统的性能。
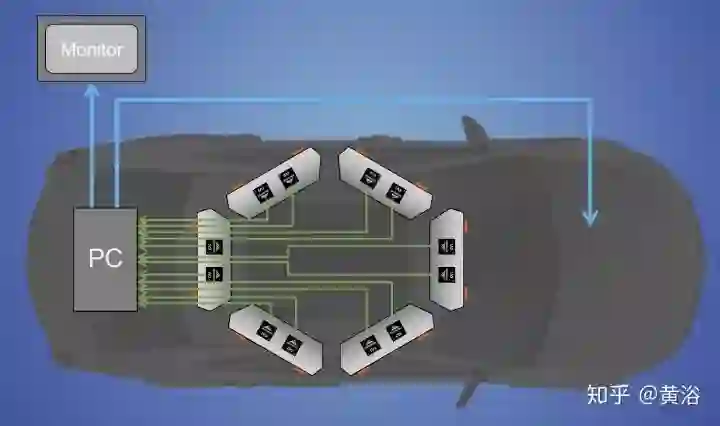
下图就是它在车顶安装6对立体视觉系统的示意图,其中它们的基线宽度可以不一样的,相应地有效检测距离也就不同。笔者曾坐过它的自动驾驶车,远处可以看到200米,近处20-30米。它确实可以做在线标定,随时调整一些双目视觉的参数。
先说立体匹配,即视差/深度估计。如图假设左右摄像头焦距f,基线(两个光心连线)宽B,3-D点X的深度z,而其视差(投影到左右图像的2-D点,其坐标差)即
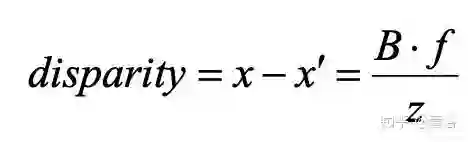
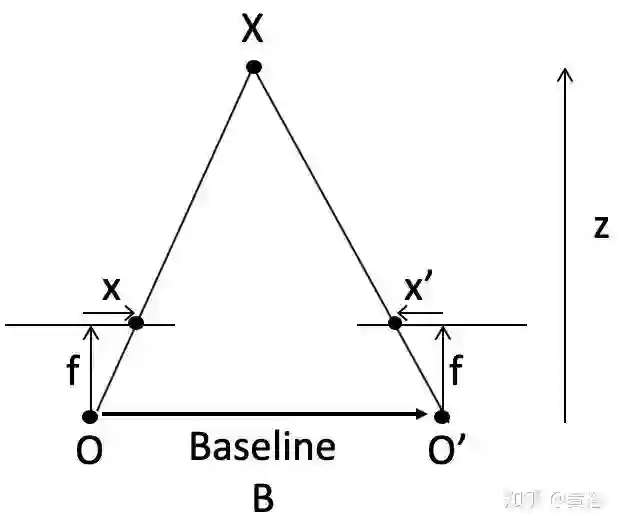
可见视差能够反算深度值。但是这里最难的就是左右镜头看到的图像如何确定是同一个目标,即匹配问题。
匹配方法分两种,全局法和局部法,双目匹配的四个步骤:
匹配成本(matching cost)计算;
成本聚集(aggregation);
视差(disparity)计算/优化;
视差修正(refinement)。
最著名的局部法就是SGM(semi-global matching),很多产品在用的方法都是基于此的改进,不少视觉芯片都采用这种算法。
SGM就是把一个全局优化近似成多个局部优化的问题组合,如下公式是2-D匹配的优化目标函数,SGM实现成为多个1-D优化路径之和
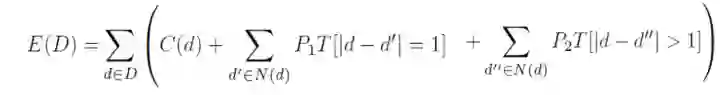
下图是沿着水平方向的路径优化函数
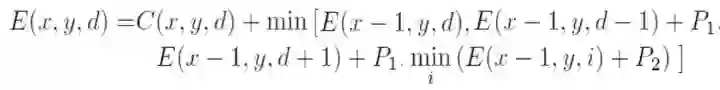
Census Transform是将8/24比特的像素变成一个2进制序列,另外一个2值特征叫LBP(local binary pattern)和它相似。立体匹配算法就是基于这个变换将匹配变成一个Hamming距离的最小化搜索。Intel的RealSense当年就是收购了一个成立于1994年基于该技术的双目视觉创业公司,还收购另外几个小公司把他们合在一起做出来的。
下图是CS变换的示意图:
PatchMatch是一个加速图像模版匹配的算法,被用在光流计算和视差估计上。之前微软研究院曾经做过一个基于单目手机相机3-D重建的项目,仿造以前成功的基于RGB-D算法KinectFusion,名字也类似MonoFusion,其中深度图估计就是采用一个修正的PatchMatch方法。
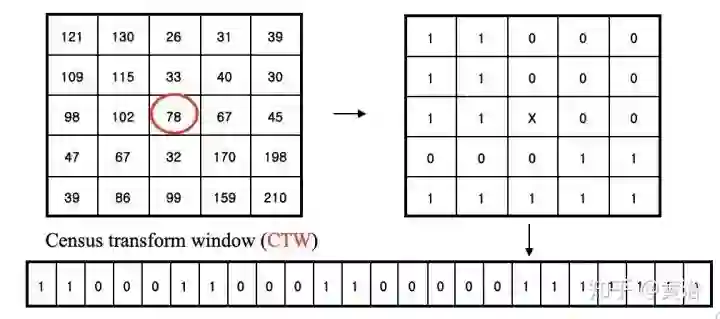
其基本思想就是对视差和平面参数随机初始化,然后通过邻域像素之间信息传播更新估计。PM算法分五个步骤:
1) 空间传播(Spatial propagation): 每个像素检查左边和上边邻居视差和平面参数,如果匹配成本变小就取代当前估计;
2) 视角传播(View propagation): 其他视角的像素做变换,检查其对应图像的估计,如果变小就取代;
3) 时域传播(Temporal propagation): 前后帧考虑对应像素的估计;
4) 平面细化(Plane refinement): 随机产生样本,如果估计使匹配成本下降,更新。
5) 后处理(Post-processing): 左右一致性和加权中值滤波器去除出格点(outliers)。
下图是PM的示意图:
再说在线标定。
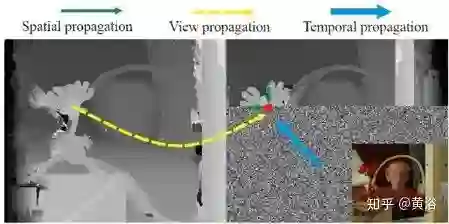
这是一个利用路上标志线(斑马线)的标定方法:已知斑马线的平行线模式,检测斑马线并提取角点,计算斑马线模式和路面实现匹配的单映性变换(Homography)参数,得到标定参数。
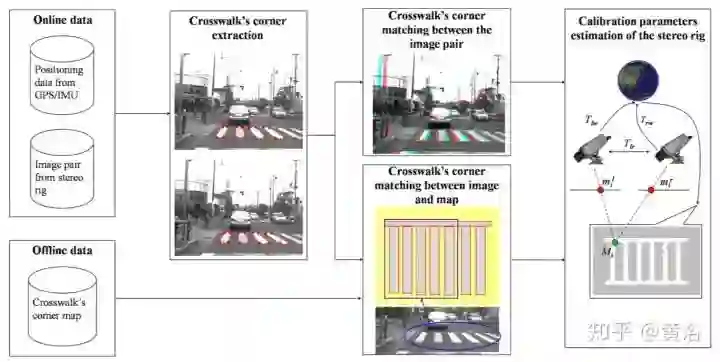
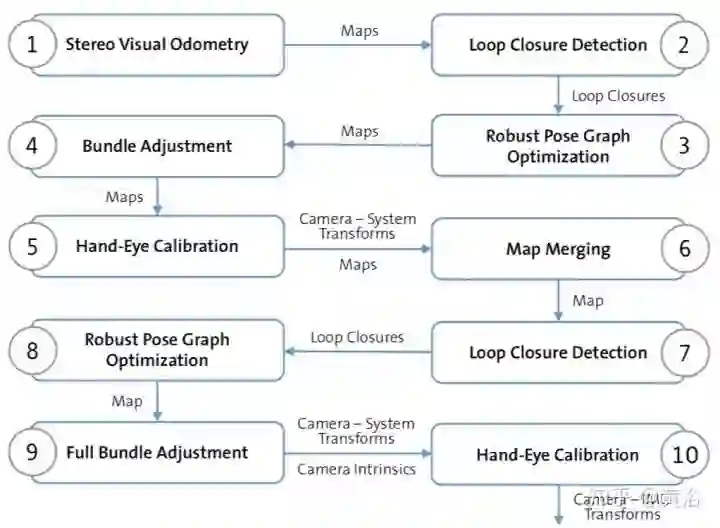
另外一个方法基于VO和SLAM,比较复杂,不过可以同时做基于地图的定位。采用SLAM做在线标定,不适合高频率操作,下图是其算法的流程图:1-4步, 通过立体视觉SLAM获取全局连续地图;第5步给出双目相机变换初始估计,第6步把所有立体相机的地图聚合成一个地图;7-8步获取多个相机之间的姿态。
和单目方法类似,采用车道线平行和路平面这个假设可以快速完成在线标定,即消失点(vanishing point)理论:假设一个平坦的道路模型,清晰的纵向车道线,没有其他目标的边缘和它们平行;要求驾驶车辆速度慢,车道线连续,左右相机的双目配置要左摄像头相对路面的仰角/斜角(yaw/roll angles)比较小;这样跟初始化的消失点(与线下标定相关)比较可以算出双目外参数的漂移量(图5-269),其算法就是从消失点估计摄像头仰角/斜角。

下面介绍几个典型的双目自动驾驶系统。
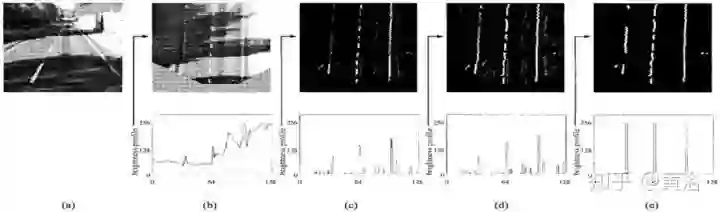
Berta Benz采用的障碍物检测算法Stixel基于以下假设:场景中的目标描述为列,重心的原因目标是站立在地面上,每个目标上的上部比下部的深度大。下图(a-d) 介绍了SGM视差结果如何生成Stixel分割结果:

下图是Stixels 计算的示意图:(a)基于动态规划的自由驾驶空间计算 (b) 高度分割中的属性值 (c) 成本图像 (灰度值反过来) (d) 高度分割。

这是他们加上深度学习做视差融合之后再做Stixel的框图和新结果:


介绍一个VisLab早期双目障碍物的算法,Generic Obstacle and Lane Detection system (GOLD)。基于IPM(Inverse Perspective Mapping),检测车道线,根据左右图像的差计算路上障碍物:

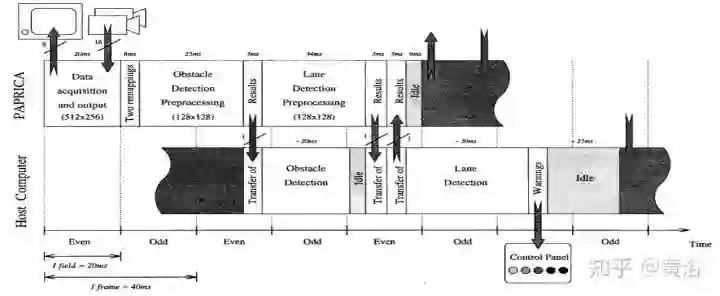
这是VisLab参加自动驾驶比赛VIAC (VisLab Intercontinental Autonomous Challenge)的车辆,除了双目摄像头以外,车上还有激光雷达作为道路分类的辅助。

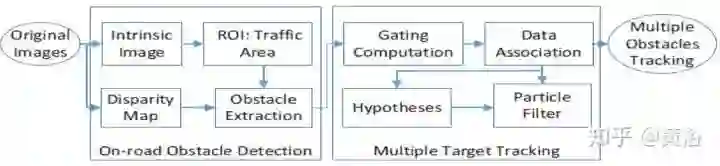
这是其双目障碍物检测流程图:视差估计利用了SGM算法和基于SAD的相关算法。

后处理中加了两个DSI(Disparity Space Image)空间的滤波器,见图5-274,一个是平滑处理,另一个是基于惯导(IMU)的运动轨迹处理。

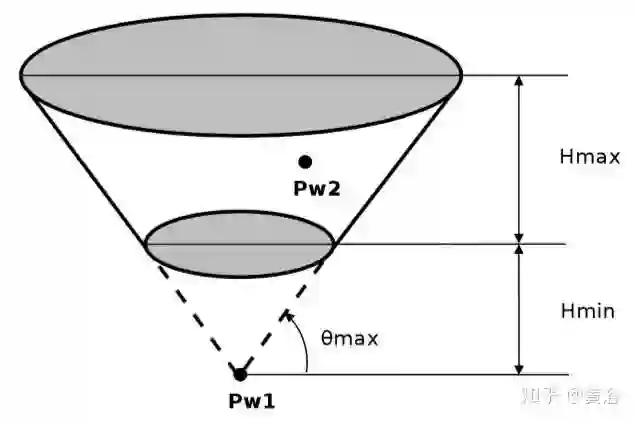
障碍物检测算法采用了JPL的方法,基于空间布置特性以及车辆的物理特性聚类得到障碍物。物理特性包括最大的高度(车辆),最小高度(障碍物)和最大道路可通过范围,这些约束定义了一个空间截断锥(truncated cone), 如图所示,那么在聚类过程中凡是落在截断锥内的点划为障碍物。
为加速视差估计算法,采用了划分DSI的方法:
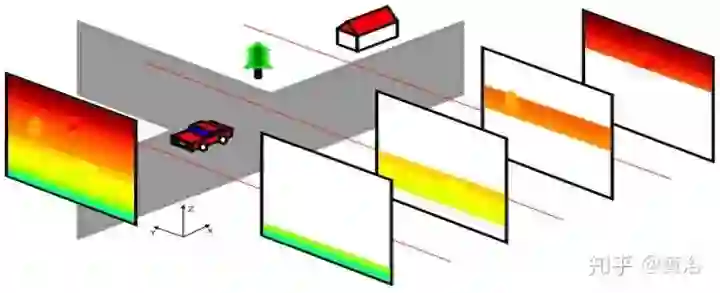
另外一种经典的方法是根据路面方程(立体视觉)得到路面视差,基于此计算出路面的障碍物:

总的看,双目检测障碍物的方法基本基于视差图,基于路面视差的方法较多。也许随着深度学习发展的突飞猛进,加上计算平台的增强,双目自动驾驶系统也会普及起来。
重磅!CVer-自动驾驶交流群已成立
扫码可添加CVer助手,可申请加入CVer大群和细分方向群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索等群。
一定要备注:研究方向+地点+学校/公司+昵称(如自动驾驶+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
麻烦给我一个在看!



