算力限制场景下的目标检测实战浅谈
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
本文为极市原创,转载请联系小助手(微信:Extreme-Vision)授权
本文为张博19年1月18日在极市直播分享的文字详细整理版。
算力限制场景主要是指在嵌入式设备,也就是算力相对比较弱的芯片上面做实时或者准实时的目标检测。这个问题在学术和工业界一直都是备受关注,并且在深度学习越来越强调落地的大背景下,这个问题也正变得越来越突出。
因为今天的分享是面向极市开发者们,分享中会相对偏向于实战,更像是一个如何调参的经验方法论方面的分享。需要强调的是,因为不少内容缺少系统的数学和理论基础,所以必须称之为浅谈,比如边际效用递减曲线、特征空间复杂程度等自提概念都还需要进一步提炼和完善,也希望能借此机会可以和大家展开深入讨论。
问题
分享之前,先提出几个问题,我们带着这几个问题来贯穿整个分享。
第一组问题,在实践中,当我们遇到一个具体的任务的时候,比如热门的车辆检测问题,它属于刚体检测(被检测物体内部不会有形变的情况)。那么,一般需要多大的神经网络计算量,可以满足一般场景下检出绝大多数目标,同时保证出现尽量少的误报?当我们需要在嵌入式的低计算能力的硬件平台上完成这个任务的时候,我们应该怎么去完成这个任务?
第二组问题,如果现在我们面临的新任务是手势检测,也就是柔体检测(被检测物体内部会发生形变的情况),刚体检测任务中面临的问题显然是同样存在的。那么,因为我们做过了刚体检测问题,经验直接借鉴过来,适用吗?
第三组触及灵魂的问题来了,既然刚体柔体都搞过一遍了,那么能不能再随便来一个新的任务,都可以套用一套相同的方法来完成?也就是大家最关心的放之四海而皆准的标准“炼丹”方法。更进一步,学术上非常热门的AutoML 与网络结构搜索Network Architecture Search,与这个所谓的同一套方法又有什么关系呢?
目标检测在算力限制场景下的特点
我们先看一下目标检测这个方法在算力限制场景下的基本特点。谷歌在2016年11月Speed/accuracy trade-offs for modern convolutional object detectors 论文中,有这样一张coco 检测问题时所能达到的mAP结果图。图上有当时最热门的神经网络骨干网和检测方法,他们在不同的网络大小下,有的方法能力强,有的方法耗时短。可以发现,所有方法都没有超出作者在图上沿左下右上的一条凸起的虚线,也就是说,在这里速度和精度是“鱼和熊掌不可兼得”的。同样,在谷歌2018年7月发表的MNasNet 论文中,对于MNasNet 和MobileNet-V2的对比,同样也展示出来神似的一条曲线,不同的是横轴从GPU时间换成了手机上的预测时间。
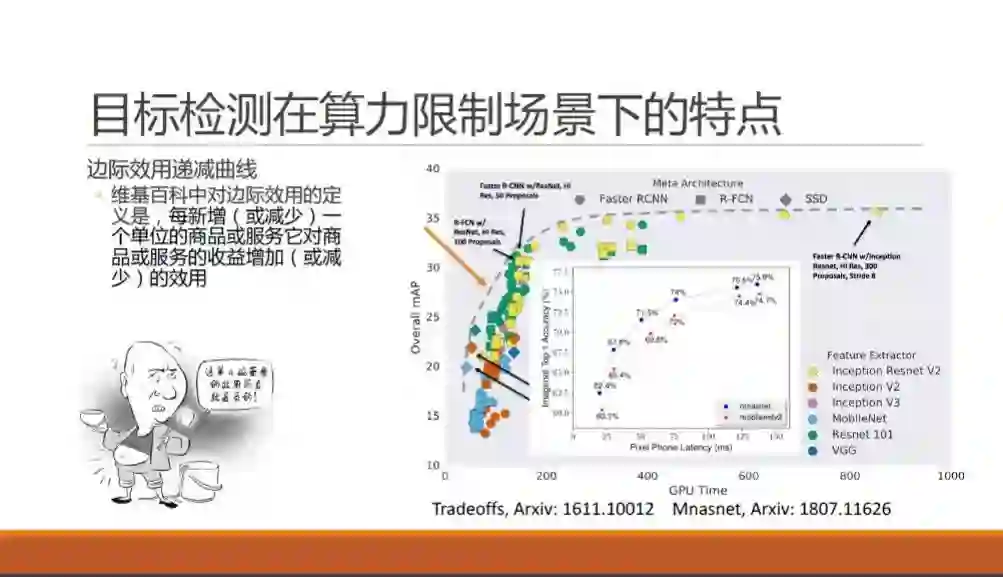
在这里,我们借用一个经济学中非常常用的概念,就是边际效用递减曲线来描述这条论文中常出现的曲线。举一个大家都熟悉的陈佩斯被朱时茂忽悠吃面的例子,当陈佩斯吃掉第一碗面的时候,他的幸福感可以从无到有提升到了七八成,吃完第二碗之后,可能幸福感就爆棚了,但是吃完第三碗和第四碗的时候,估计快要吐了,还谈何幸福感。也就是说,每增加相同的一碗面,陈佩斯获得的实际收益则越来越小,甚至变成负的了。
回到我们问题上面,算力就是陈佩斯的面,我们每给目标检测方法多增加相同量的算力的时候,所能带来的精度提升会越来越少,最后微乎其微,更有甚者,如果发生了过拟合,曲线还可能往下跌,也就是陈佩斯被撑吐了一样。
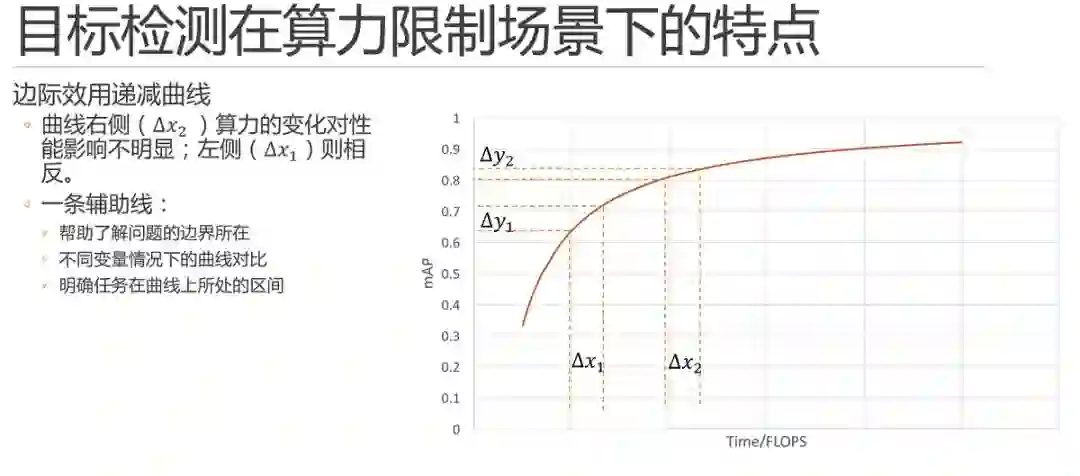
这里就可以随手画出一条曲线进行简单的展示了。需要说明的是,实际的数据和曲线只会遵循大体的趋势,一定不会严格拟合。同时,这条曲线既不是倒数,也不是多项式或是对数曲线,它究竟是什么数学公式,以当前深度学习的研究现状来说并不可以推导和求解的。
简单说,它只是一条辅助线,那它有什么用呢?
首先,他可以帮助我们大体上去了解我们所探索的问题边界所在。
其次,当我们设计调参实验的时候,可以通过绘制或者在脑子里假装绘制不同变量条件下的曲线,这条辅助线可以帮助我们来对比变量优劣。例如,我们可以在某个变量固定时调整它的算力,当进行少量的实验之后,就可以画出这样一条趋势曲线出来了,同理,调整该变量的之后就可以再画一条,两条曲线的对比就可以帮助我们判断该变量的优劣。
最重要的,它可以帮助我们明确我们的任务在这个曲线上所处的区间。首先,不同的区间内解决问题的方法也不尽相同,不同变量在指定区间内的对比关系也不尽相同;同时,当你发现当前问题所处区间位于某个变量的曲线上升区,那么这个变量绝对是一个值得发力重点研究的变量。
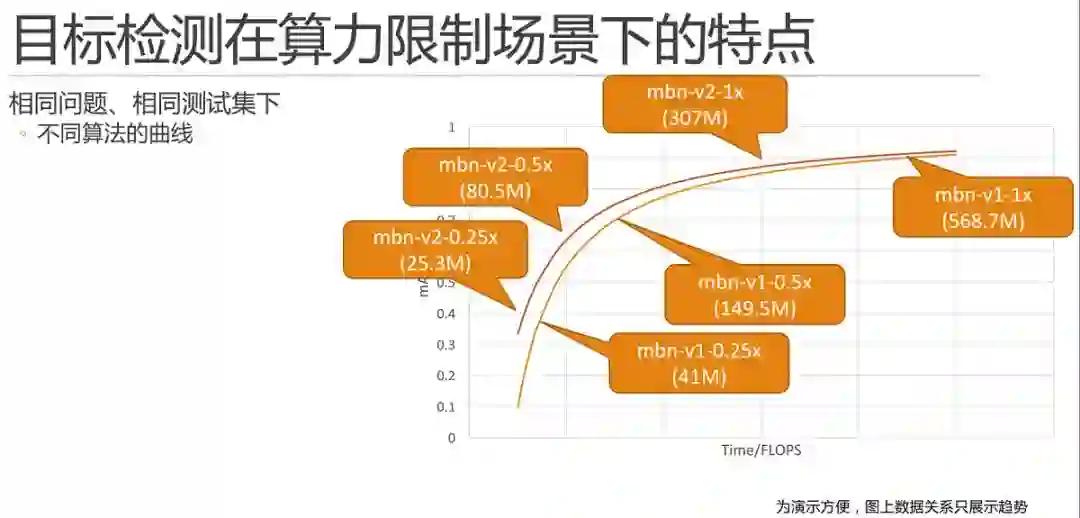
举一个简单的例子,如图所示,mobilenet-v1和mobilenet-v2,根据论文或者自己的实验,我们只需要将寥寥几个点绘制上去就可以绘制两条曲线。这里需要解释一下,为了演示方便,图上的数据关系只是展示了趋势。
这里需要特殊说明的是,并不是所有方法对比图都是理想的一上一下优者恒优的,例如,我们组18年发表的fast-downsampling mobilenet MobileNet 结构简单微调的一点性能提升的方法(https://www.jianshu.com/p/681960b4173d),在100MFlops 以下的区间内,mAP 会高于mobilenet-v1,但是超过100MFlops 之后,就要弱于mobilenet-v1了。
因此,我们必须限定任务在曲线上所处的区间。
算力:硬件限制
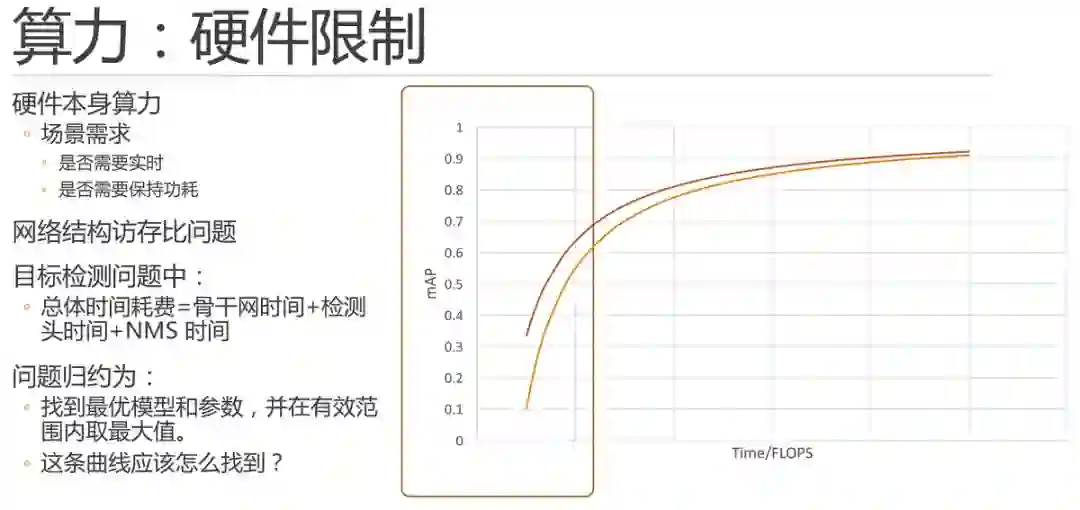
算力限制场景本身就是限定任务在曲线上所处的区间的一个最常见的因素。
众所周知,硬件本身主要就是芯片的算力是有当前芯片研发现状,芯片的价格等等诸多因素决定的。并且,当场景需求不同时,相同的硬件条件下的情况也不尽相同。任务如果是实时的,就必须在30ms 左右计算完毕,当然如果不是实时的,慢一些就没关系了。同时,在有些场景下还要求不能功耗满载,那么我们就需要更快的时间算完,例如10ms 等等。
这里需要说明计算量Flops(浮点运算次数)或者是MAC(加乘数)与实际运行时间之间的关系:
首先,由于网络结构具有不同计算访存比的特点,导致硬件算力和网络flops之间无法形成线性对比关系。这里可参考:Momenta王晋玮:让深度学习更高效运行的两个视角(http://www.sohu.com/a/221649908_610300)。比如,在轻量级网络中很常见的depthwise 卷积中,单位取到的数据所支撑的计算量小于普通卷积,也就是计算访存比小,因此对芯片的缓存访存需求更大。
同时,在目标检测问题中,除了骨干神经网络花费的时间,检测头和nms 也花费了一些时间。例如nms 的数量是不固定的,这部分的时间开销和计算量更加无法准确计算。
因此,如果在测试中直接使用时间对模型进行速度衡量,则必须到设备进行实测,这里还涉及到设备端的如ARM/NOEN、定点算浮点、量化等优化,是非常复杂的,所以一般情况下,我们都会使用Flops对计算能力进行估算。
因此,截止目前,我们可以将问题归约为,通过曲线的辅助,找到最优模型和参数,并在有效范围内取最大值。
最关键的问题来了,这条曲线该怎么找到呢?这条曲线其实是没法求的,我们会在后边进行调参举例来进行一定的说明,接下来我们再花些时间在我们的边际效用递减曲线上面。
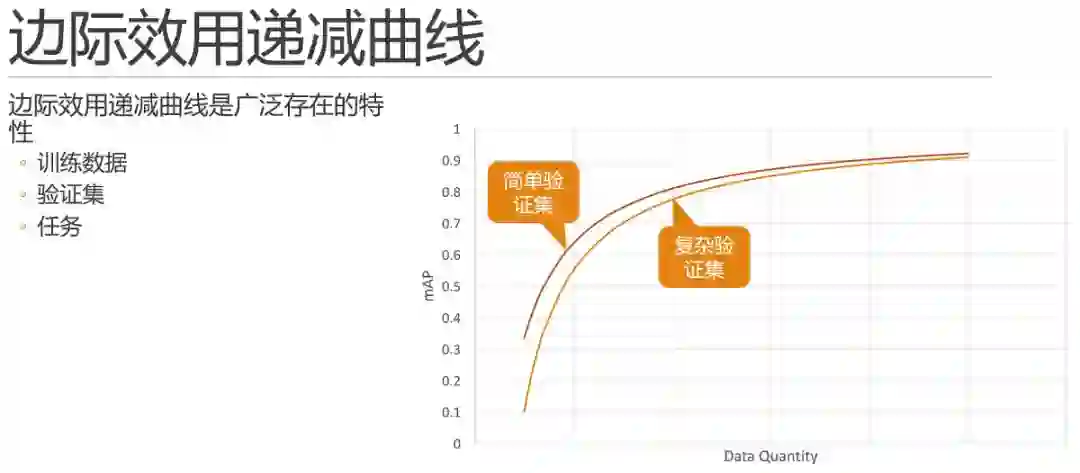
首先,该曲线是广泛存在的。
除去算力,当横轴是数据量的时候,往往情况下也是可以体现出来类似的边际效用特点的,也就是说当我们在数据不足够充分的时候,每次增加单位数量的同分布数据时,相同模型相同参数,所能提高的精度也是符合边际效用递减曲线的。
所以,如果在测试中,你发现增减数据对结果的影响非常大,那么极有可能你的问题当前处在数据量不够的阶段,需要想办法增加数据。这也就是前面所说的这条曲线可以帮助我们明确问题所在的区间。
此外,验证集和评价标准也不是一成不变的,在其他因素不变的情况下,相同方法在简单验证集下,结果的数值上显然是要优于复杂验证集的。
关于训练集和验证集的问题我们后边会再展开讲解,我们这里看一下不同任务的情况下,边际效用递减曲线之间的对比关系是怎样的?
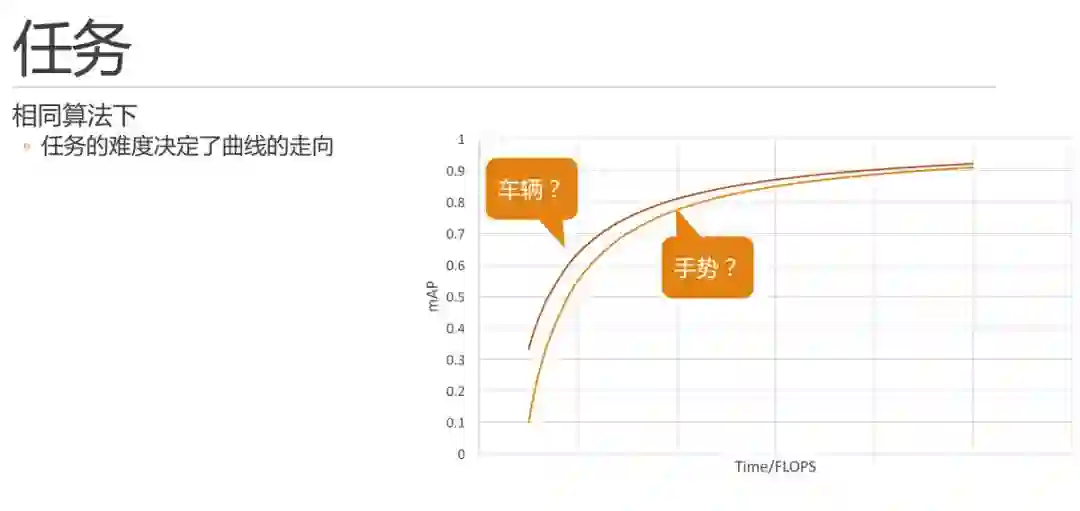
通过实践,我们了解到,相同算法下,任务的难度决定了曲线的走向。
那么,在前文提到的车辆和手势两个任务,我们能否把任务和曲线进行如图的对比关系呢?
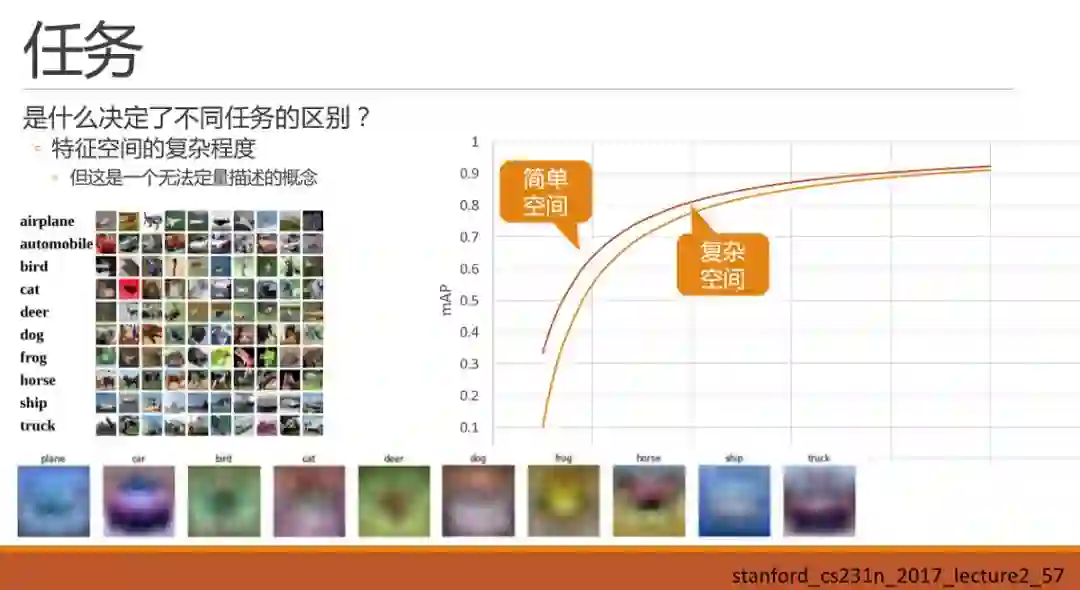
先把车辆和手势放一边,先看:是什么决定了不同任务的区别呢?直接抛出一个小的直观的感觉:即特征空间的复杂程度,决定了任务的区别。暂时我还只能称之为感觉,而不是结论,这里还真不敢下结论。虽然是感觉,但是建立这样一种感觉,可能对我们后续调参会有一些帮助。
那么什么是特征空间的复杂程度呢?这暂时还是一个无法定量描述,甚至无法准确定义的概念。我们可以就看一下什么样的空间复杂,什么样的空间简单:
我们都知道深度学习最核心的能力就是对数据特征的描述以及泛化,那么我们再来看一下数据特征具体长什么样子加深再这个理解。在Stanford cs231n课程中曾经提到cifar10 的数据集中,如果对每一类图的采样并进行平均化的话,可以得到如图的平均图,我们直观的去观察这个平均图,会发现最容易辨认的是第二类car。
那么车辆检测就是简单空间吗?我们继续看下一个例子。

这里是在100张城市数据集车辆尾部数据中采样并得到一张平均图。可以发现一整辆车的轮廓已经出来了。再继续深入去定性分析的话,因为车辆首先是刚体数据,其次线条简单清晰,不同车型的部件基本相同,如后窗、尾灯、牌照、车轮还有车轮下方的阴影区域。这里面图是随机挑选的,感觉白车有点多哈,可能是因为白车不容易脏,买的人本来就多吧?
这里需要注意的是任务需求,这个需求到底是检出来车屁股即可,还是说必须分辨出来是颜色车型等具体信息,甚至需要车辆牌照信息。因为当任务需求发生变化时,神经网络需要去描述的特征的量也会随之发生变化。

再看一下货车的。和轿车的大体相同。

好,我们再看一下人脸数据集的平均图,和车辆差不多,人脸的平均图也差不多出来了一个人,有鼻有嘴,就是看不清。但因为数据中西方人男性居多,所以我们还能大概看出来是个西方男人的感觉。同理,如果任务需要区分人脸的情绪,也就是眼角、嘴型的细微变化,这个新的需求对神经网络所需要描述的特征量的要求也就变得非常大了,也就不简单了。

继续看例子,手势,貌似隐隐约约能看出来一个胜利V的手势,但是,这个数据集显然是需要能够识别出这些手势的基本含义。直观看起来,需要的基础特征的形状也是很多的。
特征空间的复杂程度

现在又要祭出这张经典的特征可视化图了,简单的说,就是浅层特征基本就是直线和点,之后的每一层都是再对上一层特征进行概率意义上的组合。
回到特征空间复杂程度的问题上面来,我们再举一个极端的例子,mnist 手写数据集中所需要的特征,直观感觉上就是些直线折线和圈圈,而imagenet 是几乎要应对整个自然图像中所能涉及到的方方面面的情况,需要的特征和特征的组合关系几乎是无法想象的。而在实践中,大家都知道可以让两者跑的好的神经网络,容量相差甚远。
好,我们直观上现在知道了,对于一个特定问题,其实一定程度上可以说它所需要的特征量一般是确定的。当然我们没法准确的得到具体的值,神经网络要基本上能匹配上这个量,才能尽可能的做到精准。当你减少网络参数时,势必会削减网络对某些情况的判断能力,进而减少精度。
这里不得不提一下二八定量,即在正常概率的世界中,我们一般可能需要20%的精力去处理80%的情况,反之需要80%的精力去处理剩下20%的疑难杂症。通过经验我们认为,神经网络大概也是用80%的特征组合关系去处理了那20%的疑难杂症情况,所以如果抛弃部分甚至全部疑难杂症,可能20%的特征组合关系就够用了。也是为什么边际效用递减曲线画出来是一条向左上方凸出的曲线的原因吧。
实战中的实验设计

好了,虚的讲完了。结果遗憾的是,前面所讲的虚的东西,全部都是不能通过数学公式进行推导的。
这咋整?
秀了半天虚的,其实也没什么特别高明的方法,就是试。但是怎么设计实验,也就是说怎么试,每次试什么,试完之后改什么,还是很有文章可以做的。也就是这里所说的通过实验设计逐步获得最优值。这也是本次报告要分享的核心点。
其实,最近研究界大热的automl 或者是network architecture search 的方法,就是以替代掉人类的这部分调参过程为目标的。
但是本次报告我还是寄希望于完全通过手工方法来还原调优过程,通过还原这个调优过程,给大家展示调优过程中的一些小的trick 和机理。这件事虽说未来有可能要失业,但是在automl和nas仍存在学术研究阶段的情况下还是很重要的,也可能会帮助我们去认识和研究automl吧。

先再放个虚的框架,然后一一展开说一下。

先说数据集,数据集有可能是一个被忽略的因素。为什么这么说呢,因为我们对学术界论文的依赖度还是非常高的,而做论文的思路呢,一般都会使用公开数据集和通用评价标准,因为不使用这些你怎么跟同行进行比较呢?同理做比赛也有这样的问题,虽然比赛已经比较贴近实际任务了,但是也必须有一个公平的评价标准,不然排名靠前靠后凭什么呢?
但是在做实际任务的时候,数据集就必须需要适应问题本身的需求,首先是验证集。大家都知道,其实机器学习就好比训练小学生去应付期末考试。验证集就是期末考试,日常小朋友练习的题目不管怎样也得和期末考试差不多,不然一定懵逼。验证集做简单了,数据分布上可能没有覆盖到实际情况中的大部分情况,也有可能做难了,对于一些不会出现的情况上花费了太多精力。还有一种情况就是验证集和训练集的重复关系,小心验证集达标的时候其实有可能只是过拟合了训练集。所以这时候没人给做验证集,只能靠自己。
训练集数据,根据前文所讲的数据与mAP的边际效用关系,这里肯定是能尽量搞定足够多的数据才是王道。数据量不够的情况下可能还需要使用一些迁移学习的方法来弥补,这里因为时间关系就不展开了。本文的最后还会对imagenet 等数据集对轻量级模型下的迁移学习进行一些补充。
评价标准的重要性在这里也就显现出来了,一般情况下我们会用通用的目标检测评价标准(mAP)来描述我们的目标检测方法。必须承认,mAP 确实是综合的描述了一个模型的基本和平均能力,但是它不能同时兼顾漏检率和误捡率。由于mAP 是一个随着confidence 下降来同时加入tp和fp绘制曲线并计算总面积的,因此fp 也就是误捡的sample 并不会很明显的体现出来,针对比较关注误捡率的问题,最好还是不要用mAP。

好,我们开始跑了。
一般的,我会花一些时间来建立baseline,这个下一页详解。
然后开始迭代,核心思路是使用对照实验(control experiment),只改变一个变量,固定其他所有变量。
既然每次都只能调整一个参数与变量,那就最好沿着最有可能提高性能的方向调整,那么哪个是最大的变量呢?这需要熟悉神经网络的原理和研究现状,等下我们具体举例来说明一下。
这时我们前面讲的辅助线可能就能用上了,几次实验之后,你心目中大概可以形成一个或者多个边际效用递减曲线了,就可以估算一下某个变量在上面所处的位置。嗯,上升趋势比较明显的变量值得着重考虑。
所有维度都尝试之后再重头逐一尝试,因为毕竟每次只调整一个参数没有考虑到参数和参数之间的相互作用关系。
什么时候停止呢?调参小能手一般是没有止境的,yeah。不过一般也就是验证集达标,但是前面也提到了,手头这个验证集符合实际情况吗?要去实际情况跑一跑你的模型了。
举例

刚刚是原则性的套路,现在我们来举一个例子。
要求如图所示,根据我们前面对任务特征空间的描述,这个问题应该有可能能在这个量级下完成吧,我们来试试。

首先我需要一个baseline,虽然我现在要用的是10M 的网络,10M 的论文可能不多,但是我这时还是会先去复现mobilenet-v1,mobilenet-v2,shufflenet-v1/v2,以及各种坊间反馈还比较优秀的所有轻量级网络结构。
为什么要先做这件事呢,除了作为参考系方便进行比较之外,最大的目的是可以最大限度的保证方法本身、你用的框架等等没有问题,如果这时不搞清楚,未来长期在坑里待着,显然完成不了任务了。同时这样会很容易帮你发现论文中的细节部分,论文搞得多的同学都知道,论文不可以没有创新性,所以很有可能一篇论文中号称的自己最核心的算法点在实测中不是对性能提升最优的点,相反,可能论文中会有些很实用但是看起来不是很有创新性的东西,而你不真的去跑一下,是不知道的。
另外,如果一篇论文已经是一两年前的,这一两年之中有些其他论文会提出一些有趣的小trick 和小参数或者小调整,这些东西有的时候也可以在复现经典论文和方法的时候一起揉进去,例如何凯明提出的fan-in,fan-out参数初始化方法,就可以应用到其前面就发表的论文或者项目中去。(这里可引出一个问题:有没有必要把机器学习算法自己实现一遍 )
总之,这是一个磨刀不误砍柴工的工作,也是一个积累基础经验的过程。
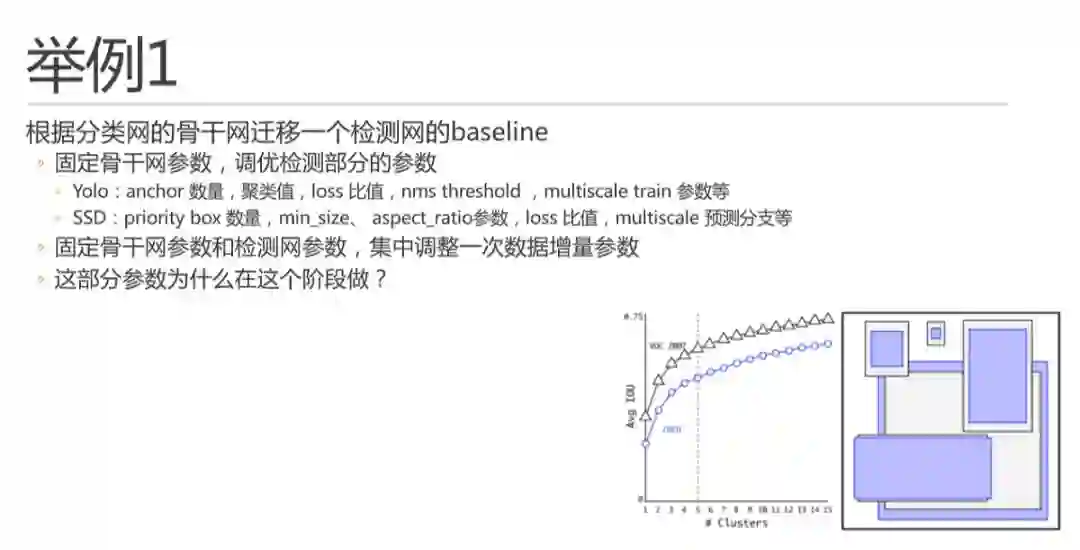
由于不少论文是分类网的论文,或者是不同检测头做的检测模型,比如faster-rcnn 两阶段方法,我们需要换成自己使用的检测头,比如Yolo。这时我就需要再做一个baseline,并获得自有训练数据集下的检测结果。
首先,我会先固定骨干网参数,直接检测部分的参数进行调优。例如Yolo 和SSD 中如图所示的这些参数,简单说原则还是迭代尝试,每次只调整其中一个。
这里多说一嘴,不管是yolo 还是ssd ,他们的anchor 或者priority box 机制,其数量也是符合边际效用递减曲线的,如yolo v2 论文中的这幅图。大家看,这曲线无处不在是吧。所以当其数量适当增加的时候对精度提升是很有用的,但是在算力有限场景下也不能加太多,因为总的proposal 会太多,nms 也会变的很多。
另外,这里anchor聚类出来的具体长宽,只要大体符合数据分布,就可以了,不用很精确,每次增加了同分布数据的时候也不用重复做聚类,因为回归器会自动完成回归过程的,不要离的太远就好。这里不展开了。
调整完检测参数之后,还要再集中调整一次数据增量参数。数据增量也是非常重要的,其实同理,数据增量也是符合边际效用递减曲线的,做太多了也就没啥用了,该增加数据还是增加数据吧。
这里里其实是可以提出这样一个问题的,就是这部分参数为什么在这个阶段做?为什么不在先裁剪出来一个10M 的骨干网再加检测头。这里我个人更加倾向于在后续调优过程中的测试过程更加end2end,因为你的目的就是目标检测嘛。同时,需要注意的是这时的参数并不是最优参数,只是一个起始baseline,未来骨干网确定之后还会再来迭代。
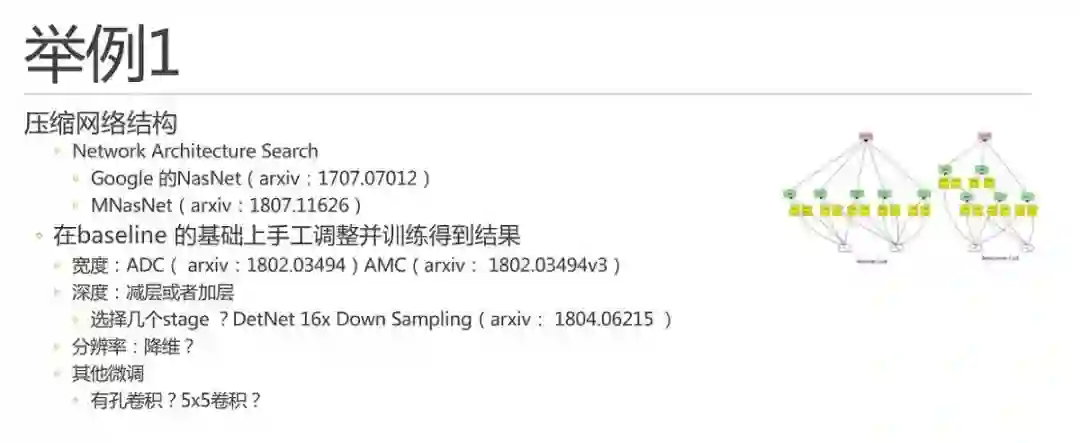
现在我们要开始裁剪网络结构了,虽然这部分最前沿的研究工作表示完全可以有NAS来完成。比如Google 2017年的NasNet 和2018年的MNasNet,不过我倒是觉得一般情况下一般人可能也部署不起能快速进行网络结构搜索的分布式搜索框架。右图即为NasNet 搜索出来的网络结构,确实看起来也不像是设计出来的。
我们还是在baseline 的基础上逐步手工调整吧,可能确实相比搜索达不到最优,但是因为有迹可循,有经验的时候还是有可能会比nas 上使用强化学习学出来的过程快一点。不过这块不敢说大话,说不好未来有可能就不行了。
根据mobilenet-v1 论文,有几个方向可以调整:宽度、深度、分辨率。
先说宽度,这块有两篇比较相关的论文,主要是ADC和AMC,是同一个组做的。这两篇论文可以做到逐层选择最优的层宽度,效果还不错。这里我们还是跟mobilenet-v1一样进行等比例的宽度压缩,不过有的时候也可能会进行一些相应层的区别性调整。
深度,就是加减层。这里的问题是,既然是压缩为什么还要加层,因为可能宽度下来了,计算量已经大幅下来了,增加深度还可以在计算量和运行时间上达标。
深度这里还有一个很重要的就是选择几个stage 的问题,一般的分类网都是32x downsampling ,5个stage,旷视在2018年提出DetNet 中使用了16x downsampling ,4个标准stage。这样的好处是,224x224 输入下检测头的featuremap 是14x14 的,可以兼顾细节和语义,同时速度也不慢。
对于语义信息和细节信息保持更好的检测方法,FPN 是个不错的选择,但是FPN 在算力限制的条件下略显笨重,实时运行压力有点大。
对于分辨率,我们则大胆的假设这是一个可以暂时忽略的维度,原因是高分辨率可能带来的只是小目标和边框精度的提升。一般的,可以在一个可行的分辨率下面专注于其他超参数的调整。
这里还会涉及一些其他微调,例如使用其他形状或者大小的卷积核,提升感受野等。例如有孔卷积和5x5 卷积。不过有孔卷积在移动设备的性能一般般。

接下来就是在各种调整中找一个最优的tradeoff 点了,如图是我在mobilenet-v2 这个网络结构上尝试的结果,尝试了一些不同宽度、深度和微调结构等调整。左半侧的点基本是3/8这个宽度的,右半侧的点是3/4这个宽度的。箭头指向的是简单按stage裁剪完深度之后的baseline。
举个小例子,这里针对mobilenet-v2 有一个小的点是我着重去调整的,就是1/4 这个尺寸下,第一个bottleneck极小只有4,是否这个值太小会导致对特征的描述太弱,而调大它对网络整体计算量影响并不大,则可以尝试。
这里总结一下,简单说就是在当前状态找一个最需要调整的维度,有哪些维度就靠经验和他山之石了。另外,一般情况下,如果某个变量会明显提高,那么就着重优化一下它呗,也就是前文所说的在边际效用递减曲线上上升趋势比较明显的变量值得着重考虑。
而哪一个是最需要调整的呢,如果靠经验都想不出的时候,那就随便挑一个,因为真的可能有奇效哦。其实我的感觉是,这个人肉搜索过程其实完全可以看做是一个随机梯度下降的过程,每次自己都是用自己的评价函数找到了一个最佳维度然后往最优迭代。并且有的时候尝试的调整可以超出预期的值一定范围,例如裁窄网络之后加深的时候可以超量多加一些层,看看趋势。这个就可以好比是使用大的学习率或者时模拟退火算法了。
而人肉调整的好处是,我不需要每次都按相同的学习率调整,有的时候可以走一大步,节省不少迭代次数。

好,好不容易找几个模型,但是事情还没完,现在需要翻回头去在现在的结构上,再次调整之前的参数了。而在这些参数确定之后,还要再次回头把挑出来的网络结构再验证一次。因为这里存在多变量联合作用影响结果的情况,以及评价标准缺陷或者训练过程随机因素导致的偶然因素。不过这里的工作量相比之前已经不大了,因为前面已经排除掉了一些明显不行的选项嘛。
最后还要通过任务本身的实际测试去根据实测问题调整验证集。如果有问题还要再回去前面某个点上再调一遍。

刚刚的例子暂时告一段落吧,现在抛出第二个问题,毕竟预告里面提了要说一说,其实答案相比大家心中已经有了答案。
根据之前的背景,这两个问题中数据特征空间差异是巨大的,所以,其实两个问题不可能直接进行迁移学习,但是,这里方法论是适用的,这里偷个懒,就不再展开介绍如何重新适配了一遍了,相信有了第一个任务的经验,这个任务做起来并不难,迭代次数也会大幅下降。
而通过讲解,相信开篇的问题也可以得到一定的解答。
总结

首先,基础知识很重要,需要掌握大量的基础性调参经验,这里强烈推荐大家去查阅学习旷视大神魏秀参的博客(http://lamda.nju.edu.cn/weixs/project/CNNTricks/CNNTricks.html)。(查看魏秀参大神在极市平台的直播分享及大神的书籍解析深度学习 )
其次,需要严格做到对比实验方法,帮助自己准确获得这一次调整带来的性能提升,并就此思考这次调整所带来改变的原因。因为一旦有多维参数发生变化,就很难确定到底是哪一维的问题,不能准确的确定原因。另外,这里虽然排除了多维参数交叉作用的成分,但是可以通过螺旋迭代方法进行弥补。
特别需要提醒大家的是,精细的实验设计会导致尝试路径和次数很长,非常需要耐心。这时是很有必要先大胆降维,避免多个因素不知从何下手;而遇到瓶颈时则可以大胆猜测并假设问题,小心设计实验进行验证,很大概率会有惊喜。
最后,辅助性的工作/工具至关重要,是保证快速迭代的基础。所以选择一个方便上手的框架至关重要,维护框架的细节也非常重要。这里值得建议的是,能用多卡加速就用多卡加速,然后有必要关注一下硬盘读写瓶颈,建议换SSD固态硬盘。不过有一点值得庆幸,小模型的单模型训练速度很快,多因素尝试的时候,迭代速度还可以接受。
最后,一个良好的笔记软件以及使用习惯可以帮你梳理尝试过程中的逻辑和细节。不然,间隔几个小时的训练工作完成之后,只怕你已经忘记上次调整的是什么了。
问题回答
后边回答环节问题较多,回答的时间比较仓促,这边挑三个出来简单再说一下。
第一是关于超参数方面的,也就是学习率batch size,iteration等等超参数的配置。这里也是需要严格的对比实验设计来尝试的。同时,超参数是一般情况下变化不大,总的尝试次数(batchsize * iteration)基本是随着数据集总量来的。所以一般确定了的超参数,在数据量变化不大的时候可以保持不动。
第二是关于检出率和召回率如何兼顾?这个问题现场时候我理解错了,讲的更多的是如何挑选一个好的评价标准。事实上,如果回到本文所最长提到的边际效用递减曲线来说,兼顾检出率和召回率,就是找到一个最靠上的模型和超参数。具体找到这个模型,就是文中所讲的方法论来做了。
第三是轻量级模型下,用imagenet预训练有没有意义?回到特征空间的背景,因为轻量级模型的网络结构容量本身较小,所能容纳的特征量不大。但是imagenet的数据集特征空间非常大,远超了轻量级模型的能力。会导致预训练模型中对特征的描述和目标问题领域相距过大,预训练学出来的特征后边都会被新问题训练过程中覆盖掉。所以,数据不够时合理的解决方法是,可以使用特征相比比较相似的数据集进行预训练,例如车辆检测问题中,数据量不够,可以使用kitti、bdd100k等数据集进行一定的迁移工作。
最后,欢迎大家来信交流,邮箱是zzningxp@gmail.com,也可以关注我的博客(https://www.jianshu.com/u/91e8e03fc975)。
*延伸阅读
每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击左下角“阅读原文”立刻申请入群~

觉得有用麻烦给个好看啦~



