Dropout终于要被替换 (文末有下载链接及源码)
从深度学习被大家开始重视的时候,后续就出现一个神操作到现在还值得大家去使用,那就是“Dropout”的出现,为大家带来了很多优势,但是今年2018年NIPS开始搞事情了,更新换代的机会终于出现了,Hinton教授又为大家带来了新的发现,构建更新的架构——名为:Targeted Dropout!
想必,大家都对Dropout有所了解了吧,它已经是许多经典网络的标配,主要操作是随机删除部分神经元获得不同的输出。而新的方法——Targeted Dropout其实很类似于将剪枝嵌入到了学习过程,因此训练后再用剪枝操作会有更好的性质。
“计算机视觉战队”在之前也很认真为大家说过“剪枝”的知识,有兴趣的您可以通过下面的链接回顾下。

现在开始我们今天Targeted Dropout的学习!!!
👀大体内容抢先看👀
神经网络是一种非常灵活的模型,由于其参数众多,有利于学习,但也具有高度的冗余性。这使得在不影响性能的情况下压缩神经网络成为可能。
我们引入了有针对性的Targeted Dropout,这是一种对神经网络权重和单元进行剪枝的策略,它将剪枝机制直接引入到学习中。在每次权值更新时,Targeted Dropout使用一个简单的选择标准选择一个候选组进行剪枝,然后通过应用于该集合的dropout对网络进行随机剪枝。与更复杂的正则化方案相比,最终的网络学会了更鲁棒的剪枝,同时具有极其简单的实现和易于调整的特性。
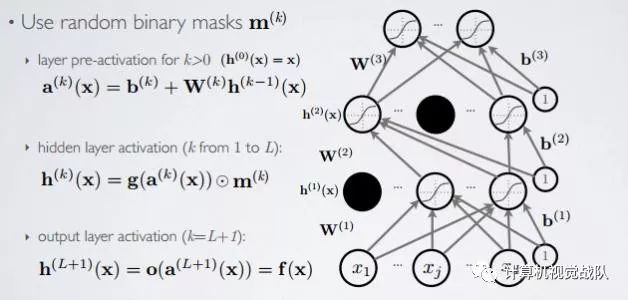
📚基础知识📚
D r o p o u t
本次研究工作主要使用了两种最流行的Bernoulli Dropout技术,Hinton等人的Unit Dropout[1,2]和wan等人的Weight Dropout[3]。对于具有输入张量X、权重矩阵W、输出张量Y和Mask M的全连接层,定义了以下两种技术:
Unit Dropout:
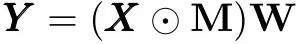
Unit Dropout随机drop unit(有时称为神经元)在每个训练步骤,以减少unit之间的依赖,防止过拟合。
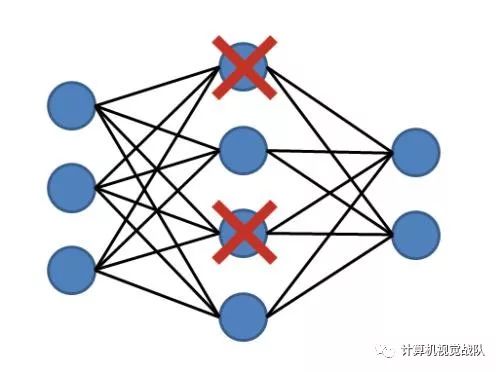
Weight Dropout:
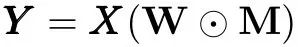
在每个训练步骤中,Weight Dropout都会随机drop权重矩阵中的单个权重。直观地说,这是层间的dropping connection,迫使网络适应不同的连接在每一个训练步骤。
✂️Magnitude-based pruning✂️
一种流行的剪枝策略是那些Magnitude-based的剪枝策略。这些策略将Top-k的最大Magnitude权重视为重要因素,使用arg max-k返回所有考虑的元素中的Top-k元素(单位或权重)。
Unit Dropout:
考虑在L2范数下权矩阵的unit(列向量):
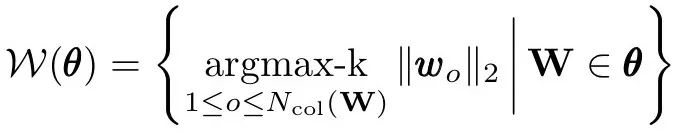
Weight Dropout:
在L1-范数下分别考虑权重矩阵的每一项。请注意,top-k相对于相同滤波器中的其他权重:
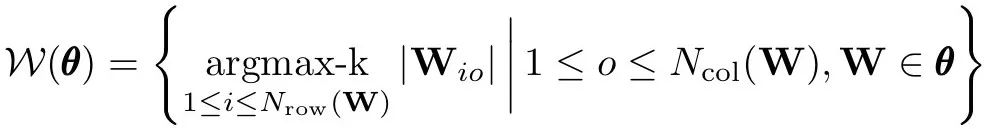
虽然weight剪枝倾向于在更粗的剪枝下保持更多的任务性能,但unit剪枝可以大大节省计算量。
⚠️ 方法 ⚠️
考虑一个由θ参数化的神经网络,且希望按照Unit Dropout和Weight Dropout定义的方法对W进行剪枝。
因此,希望找到最优参数θ*,它能令损失函数ε(W(θ*))尽可能小的同时,令|W(θ* )|≤k,即希望保留神经网络中最高数量级的k个权重。一个确定性的实现可以选择最小的|θ|−k个元素,并删除它们。但是如果这些较小的值在训练中变得更重要,那么它们的数值应该是增加的。因此,通过利用targeting proportion γ和删除概率α,将随机性引入到了这个过程中。
其中targeting proportion表示会选择最小的γ|θ|个权重作为Dropout的候选权值,并且随后以删除概率α独立地去除候选集合中的权值。这意味着在Targeted Dropout中每次权重更新所保留的单元数为(1−γ*α)|θ|。
正如在后文所看到的,Targeted Dropout降低了重要子网络对不重要子网络的依赖性,因此降低了对已训练神经网络进行剪枝的性能损失。如下表1和表2所示,权重剪枝实验表示正则化方案的基线结果要比Targeted Dropout差,并且应用了Tageted Dropout的模型比不加正则化的模型性能更好,且同时参数量只有一半。通过在训练过程中逐渐将targeting proportion由0增加到99%,最终表示该方法能获得极高的剪枝率。
表1 ResNet-32在CIFAR-10的准确率,它会使用不同的剪枝率和正则化策略

注:上表展示了Weight Dropout策略的结果,下表展示了Unit Dropout的结果。
表2 比较Targeted Dropout和ramping Targeted Dropout的Smallify

实验在CIFAR-10上使用ResNet-32。其中左图为三次targeted中最好的结果与 6次smallify中最好结果的对比,中间图为检测出最高的剪枝率,右图为ramping Tageted Dropout检测出的更高剪枝率。
📚参考文献📚
[1] Geoffrey E Hinton, Nitish Srivastava, Alex Krizhevsky, Ilya Sutskever, and Ruslan R Salakhut- dinov. Improving neural networks by preventing co-adaptation of feature detectors. arXiv preprint arXiv:1207.0580, 2012.
[2] Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: A simple way to prevent neural networks from overfitting. The Journal of Machine Learning Research, 15(1):1929–1958, 2014.
[3] Li Wan, Matthew Zeiler, Sixin Zhang, Yann Le Cun, and Rob Fergus. Regularization of neural networks using dropconnect. In International Conference on Machine Learning, pages 1058–1066, 2013.
文末福利

论文下载地址:https://openreview.net/pdf?id=HkghWScuoQ
源码:https://nips.cc/Conferences/2018/Schedule?showEvent=10941


