教你几招搞定 LSTMs 的独门绝技(附代码)

本文为雷锋字幕组编译的技术博客,原标题 Taming LSTMs: Variable-sized mini-batches and why PyTorch is good for your health ,作者为 William Falcon 。
翻译 | 赵朋飞 马力群 涂世文 整理 | MY

如果你用过 PyTorch 进行深度学习研究和实验的话,你可能经历过欣喜愉悦、能量爆棚的体验,甚至有点像是走在阳光下,感觉生活竟然如此美好 。但是直到你试着用 PyTorch 实现可变大小的 mini-batch RNNs 的时候,瞬间一切又回到了解放前。
不怕,我们还是有希望的。读完这篇文章,你又会找回那种感觉,你和 PyTorch 步入阳光中,此时你的循环神经网络模型的准确率又创新高,而这种准确率你只在 Arxiv 上读到过。真让人觉得兴奋!
我们将告诉你几个独门绝技:
1.如何在 PyTorch 中采用 mini-batch 中的可变大小序列实现 LSTM 。
2. PyTorch 中 pack_padded_sequence 和 pad_packed_sequence 的原理和作用。
3.在基于时间维度的反向传播算法中屏蔽(Mask Out)用于填充的符号。
TIPS: 文本填充,使所有文本长度相等,pack_padded_sequence , 运行LSTM,使用 pad_packed_sequence,扁平化所有输出和标签, 屏蔽填充输出, 计算交叉熵损失函数(Cross-Entropy)。
为何知其难而为之?
当然是速度和性能啦。
将可变长度元素同时输入到 LSTM 曾经可是一个艰巨的技术挑战,不过像 PyTorch 这样的框架已经基本解决了( Tensorflow 也有一个很好的解决方案,但它看起来非常非常复杂)。
此外,文档也没有很清楚的解释,用例也很老旧。正确的做法是使用来自多个示样本的梯度,而不是仅仅来自一个样本。这将加快训练速度,提高梯度下降的准确性 。
尽管 RNNs 很难并行化,因为每一步都依赖于上一步,但是使用 mini-batch 在速度上将会使其得到很大的提升。
序列标注
先来尝试一个简单的序列标注问题,在这里我们会创建一个 LSTM/GRU 模型 对贾斯汀·比伯的歌词做词性标注。譬如:“is it too late now to say sorry?” (移除 ’to’ 和 ’?’ )。
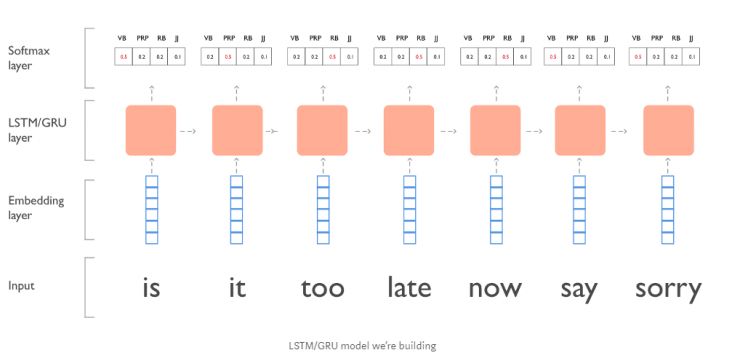
数据格式化
在实际情况中你会做大量的格式化处理,但在这里由于篇幅限制我们不会这样做。为简单起见,让我们用不同长度的序列来制作这组人造数据。
sent_1_x = ['is', 'it', 'too', 'late', 'now', 'say', 'sorry']
sent_1_y = ['VB', 'PRP', 'RB', 'RB', 'RB', 'VB', 'JJ']
sent_2_x = ['ooh', 'ooh']
sent_2_y = ['NNP', 'NNP']
sent_3_x = ['sorry', 'yeah']
sent_3_y = ['JJ', 'NNP']
X = [sent_1_x, sent_2_x, sent_3_x]
Y = [sent_1_y, sent_2_y, sent_3_y]
当我们将每个句子输入到嵌入层(Embedding Layer)的时候,每个单词(word)将会映射(mapping)到一个索引(index),所以我们需要将他们转换成整数列表(list)。
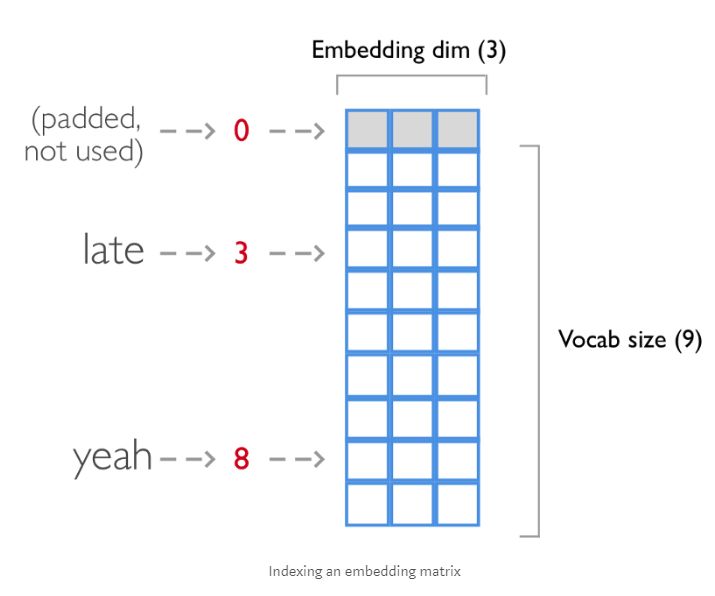
索引一个词嵌入矩阵(Embedding Matrix)
这里我们将这些句子映射到相应的词汇表(V)索引
# map sentences to vocab
vocab = {'<PAD>': 0, 'is': 1, 'it': 2, 'too': 3, 'late': 4, 'now': 5, 'say': 6, 'sorry': 7, 'ooh': 8, 'yeah': 9}
# fancy nested list comprehension
X = [[vocab[word] for word in sentence] for sentence in X]
# X now looks like:
# [[1, 2, 3, 4, 5, 6, 7], [8, 8], [7, 9]]
对于分类标签也是一样的(在我们的例子中是 POS 标记),这些不会嵌入 。
tags = {'<PAD>': 0, 'VB': 1, 'PRP': 2, 'RB': 3, 'JJ': 4, 'NNP': 5}
# fancy nested list comprehension
Y = [[tags[tag] for tag in sentence] for sentence in Y]
# Y now looks like:
# [[1, 2, 3, 3, 3, 1, 4], [5, 5], [4, 5]]
技巧 1:利用填充(Padding)使 mini-batch 中所有的序列具有相同的长度。
在模型里有着不同长度的是什么?当然不会是我们的每批数据!
利用 PyTorch 处理时,在填充之前,我们需要保存每个序列的长度。我们需要利用这些信息去掩盖(mask out)损失函数,使其不对填充元素进行计算。
import numpy as np
X = [[0, 1, 2, 3, 4, 5, 6],
[7, 7],
[6, 8]]
# get the length of each sentence
X_lengths = [len(sentence) for sentence in X]
# create an empty matrix with padding tokens
pad_token = vocab['<PAD>']
longest_sent = max(X_lengths)
batch_size = len(X)
padded_X = np.ones((batch_size, longest_sent)) * pad_token
# copy over the actual sequences
for i, x_len in enumerate(X_lengths):
sequence = X[i]
padded_X[i, 0:x_len] = sequence[:x_len]
# padded_X looks like:
array([[ 1., 2., 3., 4., 5., 6., 7.],
[ 8., 8., 0., 0., 0., 0., 0.],
[ 7., 9., 0., 0., 0., 0., 0.]])
我们用同样的方法处理标签 :
import numpy as np
Y = [[1, 2, 3, 3, 3, 1, 4],
[5, 5],
[4, 5]]
# get the length of each sentence
Y_lengths = [len(sentence) for sentence in Y]
# create an empty matrix with padding tokens
pad_token = tags['<PAD>']
longest_sent = max(Y_lengths)
batch_size = len(Y)
padded_Y = np.ones((batch_size, longest_sent)) * pad_token
# copy over the actual sequences
for i, y_len in enumerate(Y_lengths):
sequence = Y[i]
padded_Y[i, 0:y_len] = sequence[:y_len]
# padded_Y looks like:
array([[ 1., 2., 3., 3., 3., 1., 4.],
[ 5., 5., 0., 0., 0., 0., 0.],
[ 4., 5., 0., 0., 0., 0., 0.]])
数据处理总结:
我们将这些元素转换成索引序列并通过加入 0 元素对每个序列进行填充(Zero Padding),这样每批数据就可以拥有相同的长度。
现在我们的数据的形式如下:
# X
array([[ 1., 2., 3., 4., 5., 6., 7.],
[ 8., 8., 0., 0., 0., 0., 0.],
[ 7., 9., 0., 0., 0., 0., 0.]])
# Y
array([[ 1., 2., 3., 3., 3., 1., 4.],
[ 5., 5., 0., 0., 0., 0., 0.],
[ 4., 5., 0., 0., 0., 0., 0.]])
构建模型
借助 PyTorch 我们可以搭建一个非常简单的 LSTM 网络。模型的层结构如下:
1. 词嵌入层(Embedding Layer)
2. LSTM 层
3. 线性全连接层
4. Softmax 层
import torch
import torch.nn as nn
from torch.autograd import Variable
from torch.nn import functional as F
"""
Blog post:
Taming LSTMs: Variable-sized mini-batches and why PyTorch is good for your health:
https://medium.com/@_willfalcon/taming-lstms-variable-sized-mini-batches-and-why-pytorch-is-good-for-your-health-61d35642972e
"""
class BieberLSTM(nn.Module):
def __init__(self, nb_layers, nb_lstm_units=100, embedding_dim=3, batch_size=3):
self.vocab = {'<PAD>': 0, 'is': 1, 'it': 2, 'too': 3, 'late': 4, 'now': 5, 'say': 6, 'sorry': 7, 'ooh': 8,
'yeah': 9}
self.tags = {'<PAD>': 0, 'VB': 1, 'PRP': 2, 'RB': 3, 'JJ': 4, 'NNP': 5}
self.nb_layers = nb_layers
self.nb_lstm_units = nb_lstm_units
self.embedding_dim = embedding_dim
self.batch_size = batch_size
# don't count the padding tag for the classifier output
self.nb_tags = len(self.tags) - 1
# when the model is bidirectional we double the output dimension
self.lstm
# build actual NN
self.__build_model()
def __build_model(self):
# build embedding layer first
nb_vocab_words = len(self.vocab)
# whenever the embedding sees the padding index it'll make the whole vector zeros
padding_idx = self.vocab['<PAD>']
self.word_embedding = nn.Embedding(
num_embeddings=nb_vocab_words,
embedding_dim=self.embedding_dim,
padding_idx=padding_idx
)
# design LSTM
self.lstm = nn.LSTM(
input_size=self.embedding_dim,
hidden_size=self.nb_lstm_units,
num_layers=self.nb_lstm_layers,
batch_first=True,
)
# output layer which projects back to tag space
self.hidden_to_tag = nn.Linear(self.nb_lstm_units, self.nb_tags)
def init_hidden(self):
# the weights are of the form (nb_layers, batch_size, nb_lstm_units)
hidden_a = torch.randn(self.hparams.nb_lstm_layers, self.batch_size, self.nb_lstm_units)
hidden_b = torch.randn(self.hparams.nb_lstm_layers, self.batch_size, self.nb_lstm_units)
if self.hparams.on_gpu:
hidden_a = hidden_a.cuda()
hidden_b = hidden_b.cuda()
hidden_a = Variable(hidden_a)
hidden_b = Variable(hidden_b)
return (hidden_a, hidden_b)
技巧2:使用 PyTorch 中的 pack_padded_sequence 和 pad_packed_sequence API
再次重申一下,现在我们输入的一批数据中的每组数据均已被填充为相同长度。
在前向传播中,我们将:
1. 对序列进行词嵌入(Word Embedding)操作
2. 使用 pack_padded_sequence 来确保 LSTM 模型不会处理用于填充的元素。
3. 在 LSTM 上运行 packed_batch
4. 使用 pad_packed_sequence 解包(unpack)pack_padded_sequence 操作后的序列
5. 对 LSTM 的输出进行变换,从而可以被输入到线性全连接层中
6. 再通过对序列计算 log_softmax
7. 最后将数据维度转换回来,最终的数据维度为 (batch_size, seq_len, nb_tags)
"""
Blog post:
Taming LSTMs: Variable-sized mini-batches and why PyTorch is good for your health:
https://medium.com/@_willfalcon/taming-lstms-variable-sized-mini-batches-and-why-pytorch-is-good-for-your-health-61d35642972e
"""
def forward(self, X, X_lengths):
# reset the LSTM hidden state. Must be done before you run a new batch. Otherwise the LSTM will treat
# a new batch as a continuation of a sequence
self.hidden = self.init_hidden()
batch_size, seq_len, _ = X.size()
# ---------------------
# 1. embed the input
# Dim transformation: (batch_size, seq_len, 1) -> (batch_size, seq_len, embedding_dim)
X = self.word_embedding(X)
# ---------------------
# 2. Run through RNN
# TRICK 2 ********************************
# Dim transformation: (batch_size, seq_len, embedding_dim) -> (batch_size, seq_len, nb_lstm_units)
# pack_padded_sequence so that padded items in the sequence won't be shown to the LSTM
X = torch.nn.utils.rnn.pack_padded_sequence(x, X_lengths, batch_first=True)
# now run through LSTM
X, self.hidden = self.lstm(X, self.hidden)
# undo the packing operation
X, _ = torch.nn.utils.rnn.pad_packed_sequence(X, batch_first=True)
# ---------------------
# 3. Project to tag space
# Dim transformation: (batch_size, seq_len, nb_lstm_units) -> (batch_size * seq_len, nb_lstm_units)
# this one is a bit tricky as well. First we need to reshape the data so it goes into the linear layer
X = X.contiguous()
X = X.view(-1, X.shape[2])
# run through actual linear layer
X = self.hidden_to_tag(X)
# ---------------------
# 4. Create softmax activations bc we're doing classification
# Dim transformation: (batch_size * seq_len, nb_lstm_units) -> (batch_size, seq_len, nb_tags)
X = F.log_softmax(X, dim=1)
# I like to reshape for mental sanity so we're back to (batch_size, seq_len, nb_tags)
X = X.view(batch_size, seq_len, self.nb_tags)
Y_hat = X
return Y_hat
技巧 3 : 屏蔽(Mask Out )我们并不想在损失函数中处理的网络输出

屏蔽(Mask Out) 那些填充的激活函数
最终,我们准备要计算损失函数了。这里的重点在于我们并不想让用于填充的元素影响到最终的输出。
小提醒:最好的方法是将所有的网络输出和标签展平。然后计算其所在序列的损失值。
"""
Blog post:
Taming LSTMs: Variable-sized mini-batches and why PyTorch is good for your health:
https://medium.com/@_willfalcon/taming-lstms-variable-sized-mini-batches-and-why-pytorch-is-good-for-your-health-61d35642972e
"""
def loss(self, Y_hat, Y, X_lengths):
# TRICK 3 ********************************
# before we calculate the negative log likelihood, we need to mask out the activations
# this means we don't want to take into account padded items in the output vector
# simplest way to think about this is to flatten ALL sequences into a REALLY long sequence
# and calculate the loss on that.
# flatten all the labels
Y = Y.view(-1)
# flatten all predictions
Y_hat = Y_hat.view(-1, self.nb_tags)
# create a mask by filtering out all tokens that ARE NOT the padding token
tag_pad_token = self.tags['<PAD>']
mask = (Y > tag_pad_token).float()
# count how many tokens we have
nb_tokens = int(torch.sum(mask).data[0])
# pick the values for the label and zero out the rest with the mask
Y_hat = Y_hat[range(Y_hat.shape[0]), Y] * mask
# compute cross entropy loss which ignores all <PAD> tokens
ce_loss = -torch.sum(Y_hat) / nb_tokens
return ce_loss
哇哦~ 就是这么简单不是吗?现在使用 mini-batches 你可以更快地训练你的模型了!
当然这还仅仅是个非常简单的 LSTM 原型。你还可以做这样一些事情来增加模型的复杂度,以此提升模型的效果:
1. 利用 Glove Embeddings 进行初始化。
2. 使用 GRU Cell 代替 LSTM 部分结构
3. 采用双向机制(别忘了修改 init_hidden 函数)
4. 通过用卷积神经网络生成编码向量并加入词向量中来使用字符级特征
5. 添加 Dropout 层
6. 增加神经网络的层数
7. 当然,也可以使用基于 Python 的超参数优化库(test-tube,链接:https://github.com/williamFalcon/test_tube) 来寻找最优超参数。
总结一下:
这便是在 PyTorch 中解决 LSTM 变长批输入的最佳实践。
1. 将序列从长到短进行排序
2. 通过序列填充使得输入序列长度保持一致
3. 使用 pack_padded_sequence 确保 LSTM 不会额外处理序列中的填充项(Facebook 的 Pytorch 团队真应该考虑为这个绕口的 API 换个名字 !)
4. 使用 pad_packed_sequence 对步骤 3的操作进行还原
5. 将输出和标记展平为一个长的向量
6. 屏蔽(Mask Out) 你不想要的输出
7. 计算其 Cross-Entropy (交叉熵)
完整代码:
import torch
import torch.nn as nn
from torch.autograd import Variable
from torch.nn import functional as F
"""
Blog post:
Taming LSTMs: Variable-sized mini-batches and why PyTorch is good for your health:
https://medium.com/@_willfalcon/taming-lstms-variable-sized-mini-batches-and-why-pytorch-is-good-for-your-health-61d35642972e
"""
class BieberLSTM(nn.Module):
def __init__(self, nb_layers, nb_lstm_units=100, embedding_dim=3, batch_size=3):
self.vocab = {'<PAD>': 0, 'is': 1, 'it': 2, 'too': 3, 'late': 4, 'now': 5, 'say': 6, 'sorry': 7, 'ooh': 8,
'yeah': 9}
self.tags = {'<PAD>': 0, 'VB': 1, 'PRP': 2, 'RB': 3, 'JJ': 4, 'NNP': 5}
self.nb_layers = nb_layers
self.nb_lstm_units = nb_lstm_units
self.embedding_dim = embedding_dim
self.batch_size = batch_size
# don't count the padding tag for the classifier output
self.nb_tags = len(self.tags) - 1
# when the model is bidirectional we double the output dimension
self.lstm
# build actual NN
self.__build_model()
def __build_model(self):
# build embedding layer first
nb_vocab_words = len(self.vocab)
# whenever the embedding sees the padding index it'll make the whole vector zeros
padding_idx = self.vocab['<PAD>']
self.word_embedding = nn.Embedding(
num_embeddings=nb_vocab_words,
embedding_dim=self.embedding_dim,
padding_idx=padding_idx
)
# design LSTM
self.lstm = nn.LSTM(
input_size=self.embedding_dim,
hidden_size=self.nb_lstm_units,
num_layers=self.nb_lstm_layers,
batch_first=True,
)
# output layer which projects back to tag space
self.hidden_to_tag = nn.Linear(self.nb_lstm_units, self.nb_tags)
def init_hidden(self):
# the weights are of the form (nb_layers, batch_size, nb_lstm_units)
hidden_a = torch.randn(self.hparams.nb_lstm_layers, self.batch_size, self.nb_lstm_units)
hidden_b = torch.randn(self.hparams.nb_lstm_layers, self.batch_size, self.nb_lstm_units)
if self.hparams.on_gpu:
hidden_a = hidden_a.cuda()
hidden_b = hidden_b.cuda()
hidden_a = Variable(hidden_a)
hidden_b = Variable(hidden_b)
return (hidden_a, hidden_b)
def forward(self, X, X_lengths):
# reset the LSTM hidden state. Must be done before you run a new batch. Otherwise the LSTM will treat
# a new batch as a continuation of a sequence
self.hidden = self.init_hidden()
batch_size, seq_len, _ = X.size()
# ---------------------
# 1. embed the input
# Dim transformation: (batch_size, seq_len, 1) -> (batch_size, seq_len, embedding_dim)
X = self.word_embedding(X)
# ---------------------
# 2. Run through RNN
# TRICK 2 ********************************
# Dim transformation: (batch_size, seq_len, embedding_dim) -> (batch_size, seq_len, nb_lstm_units)
# pack_padded_sequence so that padded items in the sequence won't be shown to the LSTM
X = torch.nn.utils.rnn.pack_padded_sequence(x, X_lengths, batch_first=True)
# now run through LSTM
X, self.hidden = self.lstm(X, self.hidden)
# undo the packing operation
X, _ = torch.nn.utils.rnn.pad_packed_sequence(X, batch_first=True)
# ---------------------
# 3. Project to tag space
# Dim transformation: (batch_size, seq_len, nb_lstm_units) -> (batch_size * seq_len, nb_lstm_units)
# this one is a bit tricky as well. First we need to reshape the data so it goes into the linear layer
X = X.contiguous()
X = X.view(-1, X.shape[2])
# run through actual linear layer
X = self.hidden_to_tag(X)
# ---------------------
# 4. Create softmax activations bc we're doing classification
# Dim transformation: (batch_size * seq_len, nb_lstm_units) -> (batch_size, seq_len, nb_tags)
X = F.log_softmax(X, dim=1)
# I like to reshape for mental sanity so we're back to (batch_size, seq_len, nb_tags)
X = X.view(batch_size, seq_len, self.nb_tags)
Y_hat = X
return Y_hat
def loss(self, Y_hat, Y, X_lengths):
# TRICK 3 ********************************
# before we calculate the negative log likelihood, we need to mask out the activations
# this means we don't want to take into account padded items in the output vector
# simplest way to think about this is to flatten ALL sequences into a REALLY long sequence
# and calculate the loss on that.
# flatten all the labels
Y = Y.view(-1)
# flatten all predictions
Y_hat = Y_hat.view(-1, self.nb_tags)
# create a mask by filtering out all tokens that ARE NOT the padding token
tag_pad_token = self.tags['<PAD>']
mask = (Y > tag_pad_token).float()
# count how many tokens we have
nb_tokens = int(torch.sum(mask).data[0])
# pick the values for the label and zero out the rest with the mask
Y_hat = Y_hat[range(Y_hat.shape[0]), Y] * mask
# compute cross entropy loss which ignores all <PAD> tokens
ce_loss = -torch.sum(Y_hat) / nb_tokens
return ce_loss
原文链接:
https://towardsdatascience.com/taming-lstms-variable-sized-mini-batches-and-why-pytorch-is-good-for-your-health-61d35642972e

新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据资料】
简简单单,用 LSTM 创造一个写诗机器人
▼▼▼




