使用Keras和LSTM生成说唱歌词
编者按:Shopify数据科学家Ruslan Nikolaev通过歌词生成这一例子介绍了语言模型、RNN、LSTM以及NLP数据预处理流程。

在所有未来的AI应用中,一个重头戏是创建能够从某个数据集中学习,接着生成原创内容。应用这一想法到自然语言处理(NLP),AI社区研发了语言模型(Language Model)
语言模型的假定是学习句子是如何在文本中组织的,并使用这一知识生成新内容
在我的案例中,我希望进行一个有趣的业余项目,尝试生成说唱歌词,看看我是否能够重现很受欢迎的加拿大说唱歌手Drake(#6god)的歌词。
同时我也希望分享一个通用的机器学习项目流程,因为我发现,如果你不是很清楚从哪里开始,自己创建一些新东西经常是非常困难的。
1. 获取数据
首先我们需要构建一个包含所有Drake歌曲的数据集。我编写了一个python脚本,抓取歌词网站metrolyrics.com的网页。
import urllib.request as urllib2
from bs4 import BeautifulSoup
import pandas as pd
import re
from unidecode import unidecode
quote_page = 'http://metrolyrics.com/{}-lyrics-drake.html'
filename = 'drake-songs.csv'
songs = pd.read_csv(filename)
for index, row in songs.iterrows():
page = urllib2.urlopen(quote_page.format(row['song']))
soup = BeautifulSoup(page, 'html.parser')
verses = soup.find_all('p', attrs={'class': 'verse'})
lyrics = ''
for verse in verses:
text = verse.text.strip()
text = re.sub(r"\[.*\]\n", "", unidecode(text))
if lyrics == '':
lyrics = lyrics + text.replace('\n', '|-|')
else:
lyrics = lyrics + '|-|' + text.replace('\n', '|-|')
songs.at[index, 'lyrics'] = lyrics
print('saving {}'.format(row['song']))
songs.head()
print('writing to .csv')
songs.to_csv(filename, sep=',', encoding='utf-8')
我使用了知名的BeautifulSoup包,我花了5分钟,看了Justin Yek写的How to scrape websites with Python and BeautifulSoup教程,了解了BeautifulSoup的用法。你可能已经注意到了,在上面的代码中,我迭代了songs这一dataframe。是的,实际上,我预先定义了想要抓取的歌名。
运行我编写的python爬虫后,.csv文件中包含了所有的歌词。是时候开始预处理数据并创建模型了。
songs = pd.read_csv('data/drake-songs.csv')
songs.head(10)
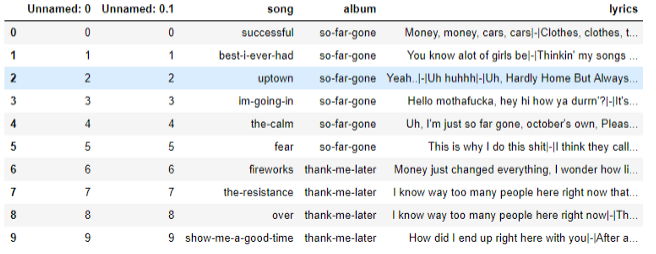
DataFrame中储存了所有歌词
关于模型
现在,我们将讨论文本生成的模型,这是本文的重头戏。
创建语言模型的两种主要方法:(一)字符层次模型;(二)单词层次模型
这两种方法的主要差别在于输入和输出。下面我将介绍这两种方法到底是如何工作的。
字符层次模型
字符层次模型的输入是一系列字符seed(种子),模型负责预测下一个字符new_char。接着使用seed + new_char生成下一个字符,以此类推。注意,由于网络输入必须保持同一形状,在每一次迭代中,实际上我们将从种子丢弃一个字符。下面是一个简单的可视化:
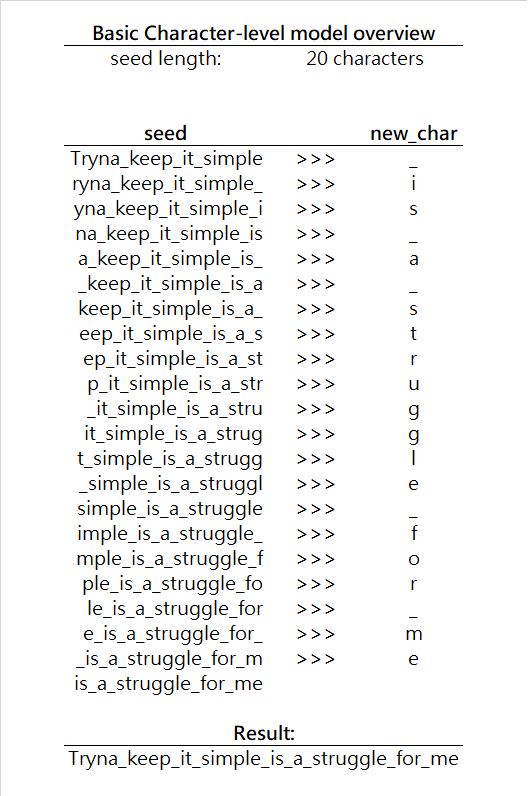
在每一次迭代中,基本上模型根据给定的种子字符预测最可能出现的下一个字符,用条件概率可以表达为,寻找P(new_char | seed)的最大值,其中new_char是字母表中的任意字符。在我们的例子中,字符表是所有英语字母,加上空格字符。(注意,你的字母表可能大不一样,取决于模型适用的语言,字母表可以包含任何你需要的字符。)
单词层次模型
单词层次模型几乎和字符层次模型一模一样,只不过生成下一个单词,而不是下一个字符。下面是一个简单的例子:

在单词层次模型中,我们预测的单位不再是字符,而是单词。也就是,P(new_word | seed),其中new_word是词汇表中的任何单词。
注意,现在我们要搜索的空间比之前大很多。在字符层次模型中,每次迭代只需搜索几十种可能性,而在单词层次模型中,每次迭代的搜索项多很多。因此,单词层次算法需要在每次迭代上花费更多的时间,好在由于每次迭代生成的是一个完整的单词,而不是单个字符,所以其实并没有那么糟。
另外,在单词层次模型中,我们可能会有一个非常多样化的词汇表。通常,我们通过在数据集中查找所有独特的单词构建词汇表(一般在数据预处理阶段完成)。由于词汇表可能变得无限大,有很多技术用于提升算法的效率,比如词嵌入,以后我会专门写文章介绍词嵌入。
就本文而言,我将使用字符层次模型,因为它更容易实现,同时,对字符层次模型的理解可以很容易地迁移到单词层次模型。其实在我撰写本文的时候,我已经创建了一个单词层次的模型——以后我会另外写一篇文章加以介绍。
2. 数据预处理
就字符层次模型而言,我们将依照如下方式预处理数据:
将数据集切分为token 我们不能直接将字符串传给模型,因为模型接受字符作为输入。所以我们需要将每行歌词切分为字符列表。
定义字母表 上一步让我们得到了所有可能出现在歌词中的字符,我们将查找所有独特的字符。为了简化问题,再加上整个数据集不怎么大(我只使用了140首歌),我将使用英语字母表,加上一些特殊字符(比如空格),并忽略数字和其他东西(由于数据集较小,我将选择让模型预测较少种字符)。
创建训练序列 我们将使用滑窗(sliding window)技术,通过在序列上滑动固定尺寸的窗口创建训练样本集。
每次移动一个字符,我们生成20个字符长的输入,以及单个字符输出。此外,我们得到了一个附带的好处,由于我们每次移动一个字符,实际上我们显著扩展了数据集的尺寸。
标签编码训练序列 最后,由于我们不打算让模型处理原始字符(不过理论上这是可行的,因为技术上字符即数字,你几乎可以说ASCII为我们编码了所有字符),我们将给字母表中的每个字符分配一个整数,你也许听说过这一做法的名称,标签编码(Label Encoding)。我们创建了映射
character-to-index和index-to-character。有了这两个映射,我们总是能够将任何字符编码为独特的整数,同时解码模型输出的索引数字为原本的字符。one-hot编码数据集 由于我们处理的是类别数据(字符属于某一类别),因此我们将编码输入列。关于one-hot编码,可以参考Rakshith Vasudev撰写的What is One Hot Encoding? Why And When do you have to use it?一文。

当我们完成以上5步后,我们只需创建模型并加以训练。如果你对以上步骤的细节感兴趣,可以参考下面的代码。
加载所有歌曲,并将其合并为一个巨大的字符串。
songs = pd.read_csv('data/drake-songs.csv')
for index, row in songs['lyrics'].iteritems():
text = text + str(row).lower()
找出所有独特的字符。
chars = sorted(list(set(text)))
创建character-to-index和index-to-character映射。
char_indices = dict((c, i) for i, c in enumerate(chars))
indices_char = dict((i, c) for i, c in enumerate(chars))
切分文本为序列。
maxlen = 20
step = 1
sentences = []
next_chars = []
# 迭代文本并保存序列
for i in range(0, len(text) - maxlen, step):
sentences.append(text[i: i + maxlen])
next_chars.append(text[i + maxlen])
为输入和输出创建空矩阵,然后将所有字符转换为数字(标签编码和one-hot向量化)。
x = np.zeros((len(sentences), maxlen, len(chars)), dtype=np.bool)
y = np.zeros((len(sentences), len(chars)), dtype=np.bool)
for i, sentence in enumerate(sentences):
for t, char in enumerate(sentence):
x[i, t, char_indices[char]] = 1
y[i, char_indices[next_chars[i]]] = 1
3. 创建模型
为了使用之前的一些字符预测接下来的字符,我们将使用循环神经网络(RNN),具体来说是长短时记忆网络(LSTM)。如果你不熟悉这两个概念,我建议你参考以下两篇文章:循环神经网络入门和一文详解LSTM网络。如果你只是想温习一下这两个概念,或者信心十足,下面是一个快速的总结。
RNN
你通常见到的神经网络像是一张蜘蛛网,从许多节点收敛至单个输出。就像这样:

图片来源:neuralnetworksanddeeplearning.com/
在这里我们有单个输入和单个输出。这样的网络对非连续输入效果很好,其中输入的顺序不影响输出。但在我们的例子中,字符的顺序非常重要,因为正是字符的特定顺序构建了单词。
RNN接受连续的输入,使用前一节点的激活作为后一节点的参数。
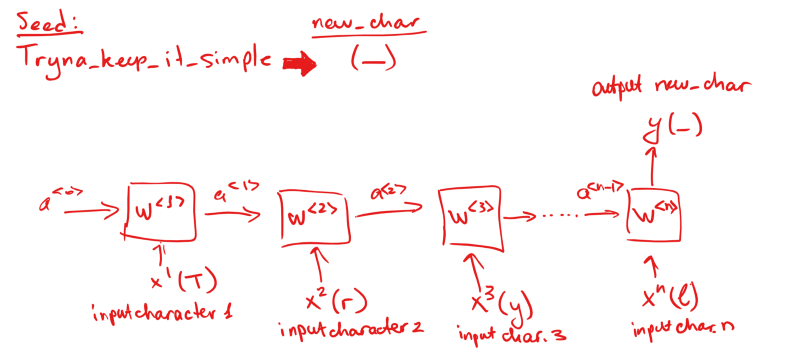
LSTM
简单的RNN有一个问题,它们不是非常擅长从非常早的单元将信息传递到之后的单元。例如,如果我们正查看句子Tryna keep it simple is a struggle for me,如果不能回头查看之前出现的其他单词,预测最后一个单词me(可能是任何人或物,比如:Bake、cat、potato)是非常难的。
LSTM增加了一些记忆,储存之前发生的某些信息。
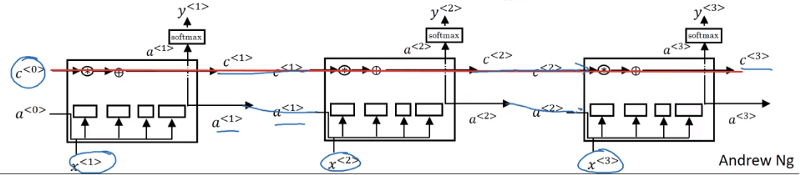
LSTM可视化;图片来源:吴恩达的深度学习课程
除了传递a<n>激活之外,同时传递包含之前节点发生信息的c<n>。这正是LSTM更擅长保留上下文信息,一般而言在语言模型中能做出更好预测的原因。
代码实现
我以前学过一点Keras,所以我使用这一框架构建网络。事实上,我们可以手工编写网络,唯一的差别只不过是需要多花许多时间。
创建网络,并加上LSTM层:
model = Sequential()
model.add(LSTM(128, input_shape=(maxlen, len(chars))))
增加softmax层,以输出单个字符:
model.add(Dense(len(chars)))
model.add(Activation('softmax'))
选择损失函数(交叉熵)和优化器(RMSprop),然后编译模型:
model.compile(loss='categorical_crossentropy', optimizer=RMSprop(lr=0.01))
训练模型(我们使用了batch进行分批训练,略微加速了训练过程):
model.fit(x, y, batch_size=128, epochs=30)
4. 生成歌词
训练网络之后,我们将使用某个随机种子(用户输入的字符串)作为输入,让网络预测下一个字符。我们将重复这一过程,直到创建了足够多的新行。
下面是一些生成歌词的样本(歌词未经审查)。





你也许注意到了,有些单词没有意义,这是字符层次模型的一个十分常见的问题,输入数据经常在单词中间切开,使得网络学习并生成奇怪的新单词,并通过某种方式赋予其“意义”。
单词层面的模型能够克服这一问题,不过对于一个不到200行代码的项目而言,字符层次模型仍然十分令人印象深刻。
其他应用
字符层次网络的想法可以扩展到其他许多比歌词生成更实际的应用中。
例如,预测手机输入:
想象一下,如果你创建了一个足够精确的Python语言模型,它不仅可以自动补全关键字或变量名,还能自动补全大量代码,大大节省程序员的时间。
你也许注意到了,这里的代码并不是完整的,有些部分缺失了,完整代码见我的GitHub仓库nikolaevra/drake-lyric-generator。在那里你可以深入所有细节,希望这有助于你自己创建类似项目。
本文参考了Keras项目自带的示例examples/lstmtextgeneration.py。
我希望你喜欢本文,如果你喜欢本文,请考虑关注或点赞。如果你对更多类似内容感兴趣,请在各大社交网络上关注 @nikolaevra
感谢TDS Team和Ludovic Benistant对本文草稿的反馈。
原文地址:https://towardsdatascience.com/generating-drake-rap-lyrics-using-language-models-and-lstms-8725d71b1b12






